
A No-SQL Big Data project from scratch
The GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world. With new files uploaded every 15 minutes, GDELT data bases contain more than 700 Gb of zipped data for the single year 2018.
In order to be able to work with a large amount of data, we have chosen to work with the following architecture :
- NoSQL : Cassandra
- AWS : EMR to transfer the data to Cassandra, and EC2 for the resiliency for the requests
- Visualization : A Zeppelin Notebook
Contributors : Raphael Lederman, Anatoli De Bradke, Alexandre Bec, Anthony Houdaille, Thomas Binetruy
The Github of the project can be found here :
0. Articles
I’ve made a series of articles regarding this work. Here the links in order :
- Install and run Zeppelin Locally
- Install and run Zeppelin on AWS EMR
- Working with Amazon S3 buckets
- Launch and access an AWS EC2 Cluster
- Install Apache Cassandra on an AWS EC2 Cluster
- Install Zookeeper on EC2 instances
- Install Apache Spark on EC2 instances
- Big (Open) Data , the GDELT Project
- Build an ETL in Scala for GDELT Data
- Move Scala Dataframes to Cassandra
1. The data
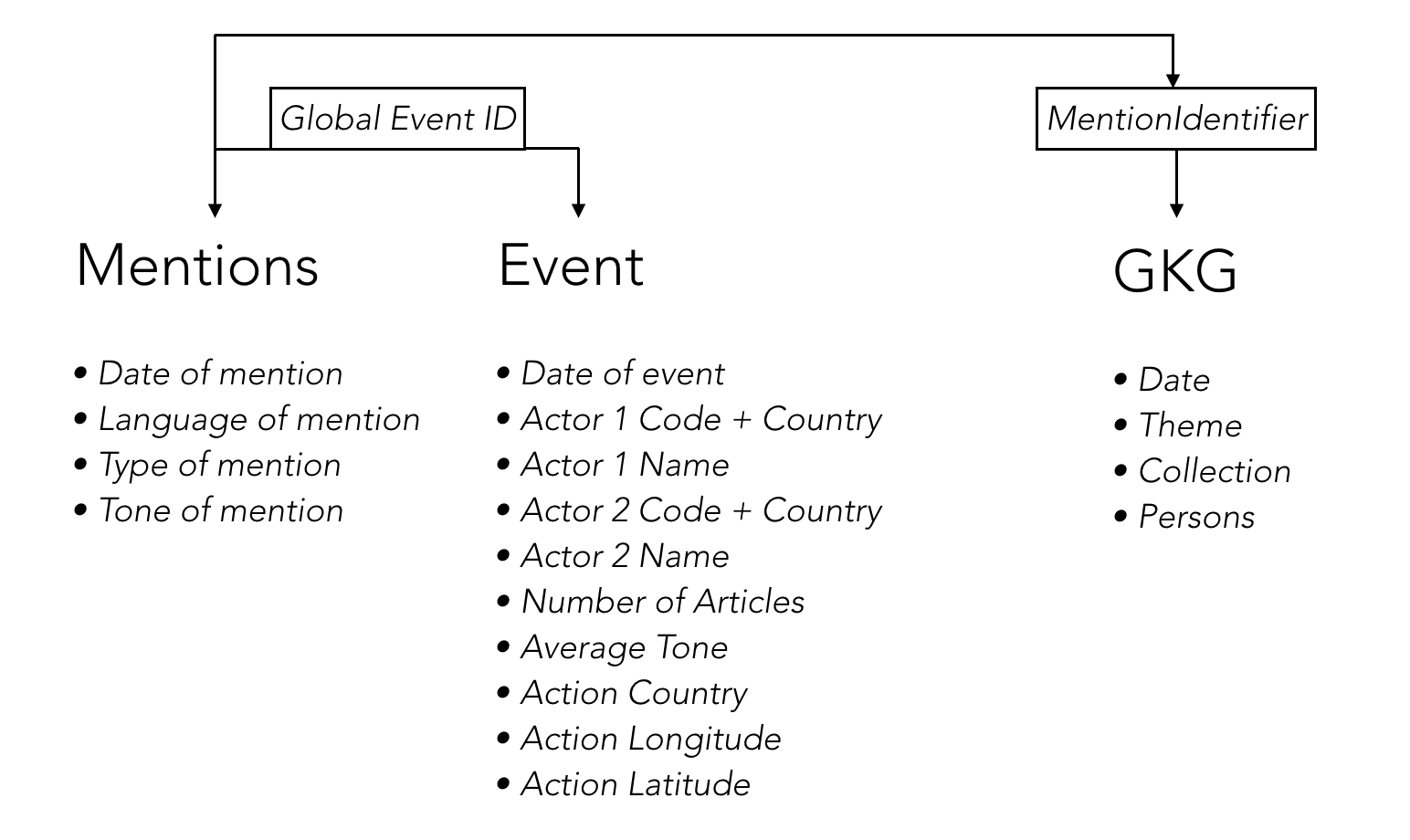
A event is defined as an action that an actor (Actor1) takes on another actor (Actor2). A mention is an article or any source that talks about an event. The GKG database reflects the events that took place in the world, ordered by theme, type of event and location.
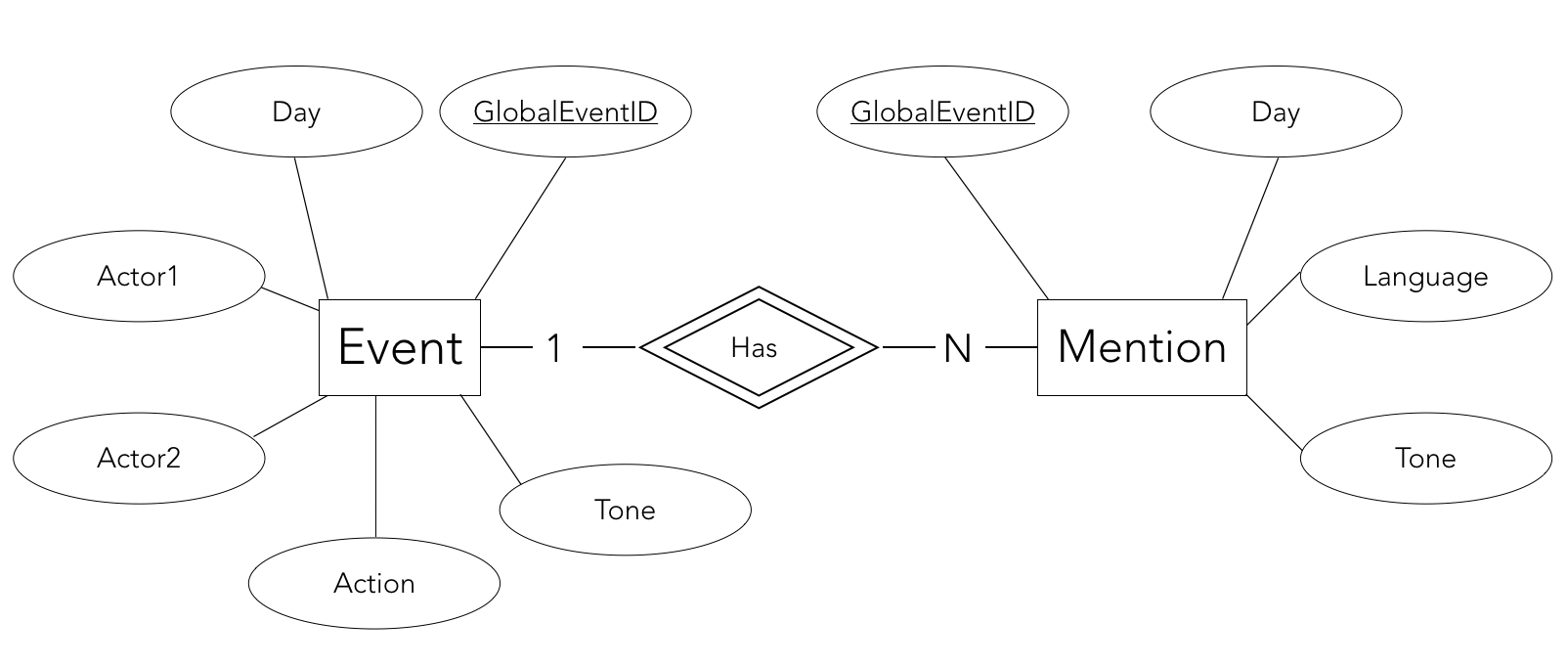
The conceptual model of the data is the following :
2. Architecture
The architecture we have chosen is the following :
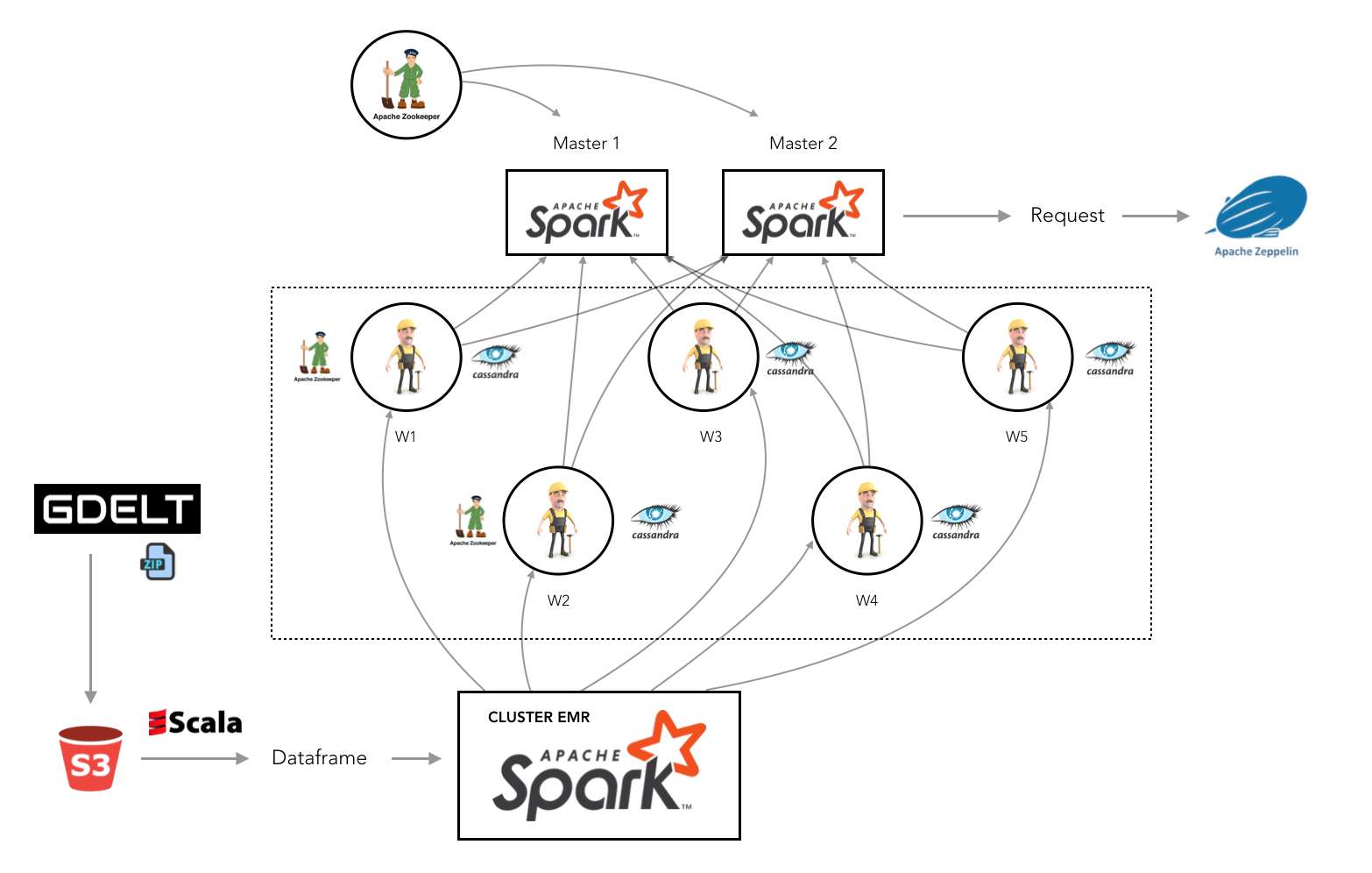
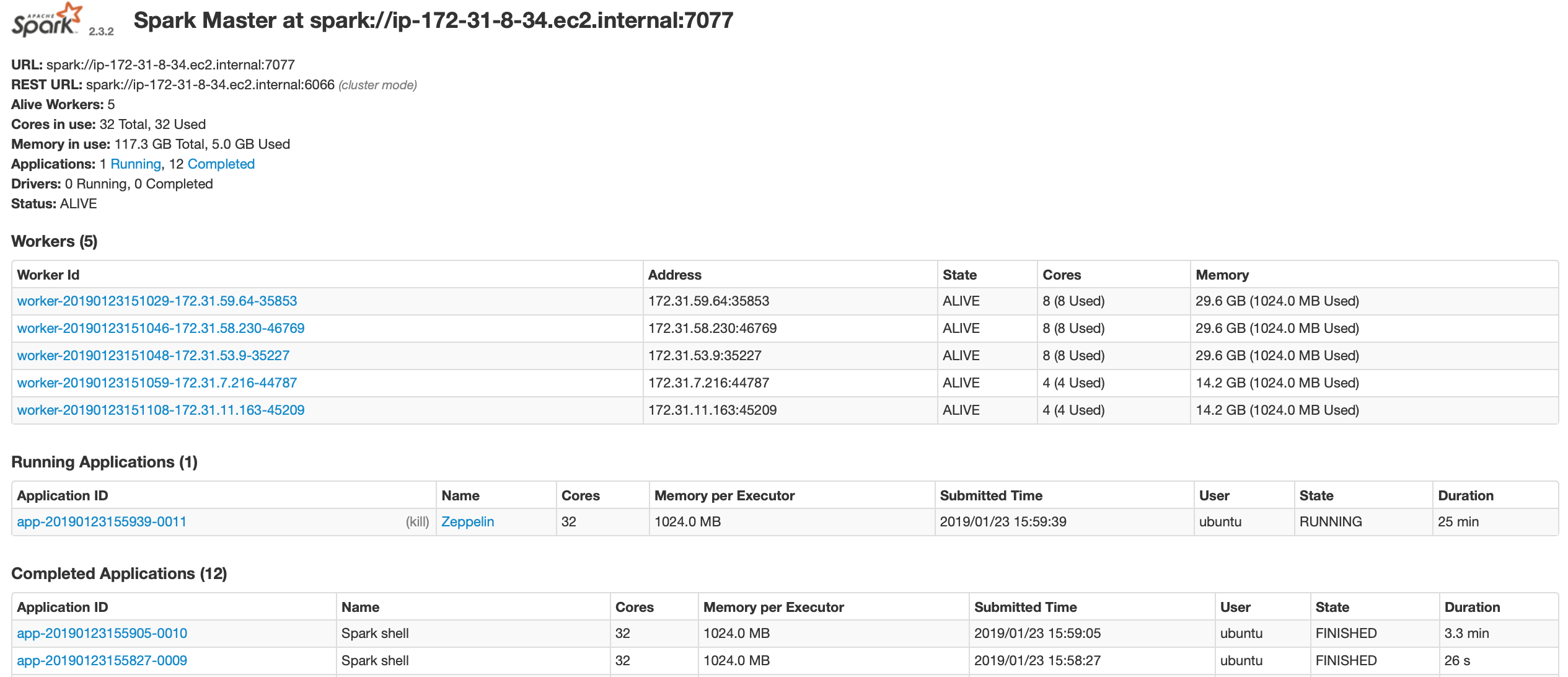
Our architecture is composed by one cluster EMR (1 master and 5 slaves) and one cluster EC2 (8 instances).
In our 8 EC2 instances we have :
- 2 Masters nodes with apache-Spark-2.3.2 and apache-Zeppelin-0.8.0
- 5 Slaves nodes with apache-Spark-2.3.2 and apache-cassandra-3.11.2, including zookeeper installed on 2 of these nodes.
- The last one is a node created for the resilience of the Master. We Installed zookeeper in it.
The Slaves resilience is automatically handled by the master Spark. The Masters resilience is handled by Zookeper. For the Zookeeper, refer to the ReadMe of the dedicated Github folder
The cluster EMR is used to transfer data from S3 to our Cassandra nodes on EC2. The reason for this architecture is that our EC2 Spark instaces could not connect to S3 due to issues with package dependencies. For Cassandra, refer to the ReadMe the dedicated Github folder
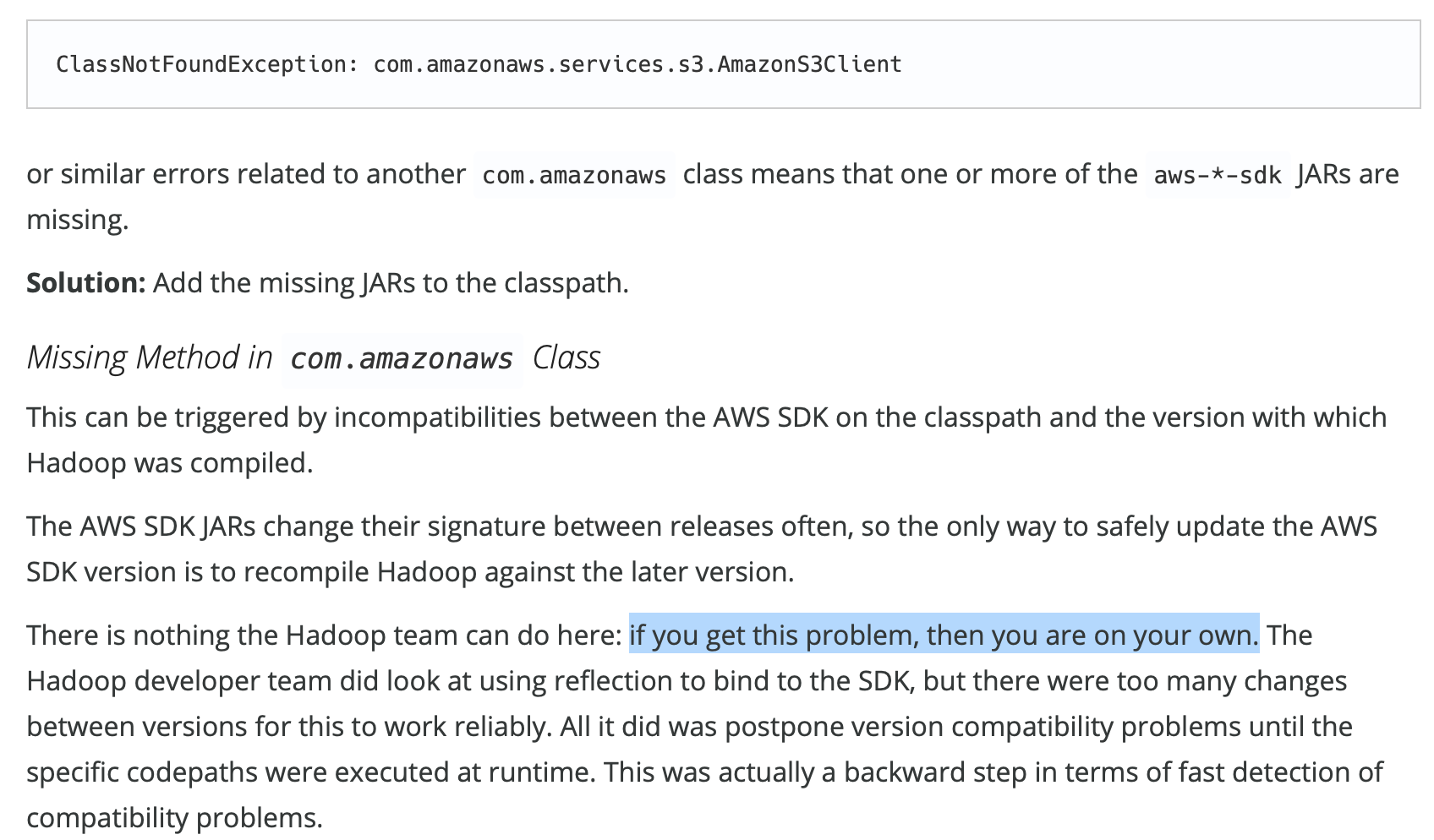
We do not find any solution : link
When all data are on our Casandra nodes, we shutdown the EMR cluster. We run our Spark-SQL request on Zeppelin.
3. Data Preparation
Import the necessary packages :
// Imports
import sys.process._
import java.net.URL
import java.io.File
import java.io.File
import java.nio.file.{Files, StandardCopyOption}
import java.net.HttpURLConnection
import org.apache.spark.sql.functions._
import sqlContext.implicits._
import org.apache.spark.input.PortableDataStream
import java.util.zip.ZipInputStream
import java.io.BufferedReader
import java.io.InputStreamReader
import org.apache.spark.sql.SQLContext
import com.amazonaws.services.s3.AmazonS3Client
import com.amazonaws.auth.BasicAWSCredentials
import org.apache.spark.sql.cassandra._
import com.datastax.spark.connector._
import org.apache.spark.sql.types.IntegerType
The ZIP files are extracted from the GDELT website following this procedure :
- Define a file downloading function
def fileDownloader(urlOfFileToDownload: String, fileName: String) = {
val url = new URL(urlOfFileToDownload)
val connection = url.openConnection().asInstanceOf[HttpURLConnection]
connection.setConnectTimeout(5000)
connection.setReadTimeout(5000)
connection.connect()
if (connection.getResponseCode >= 400)
println("error")
else
url #> new File(fileName) !!
}
Grab the list of URLs to download the ZIP files from, from the english and the translated documents.
// Download locally the list of URL
fileDownloader("http://data.gdeltproject.org/gdeltv2/masterfilelist.txt", "/tmp/masterfilelist.txt") // save the list file to the Spark Master
fileDownloader("http://data.gdeltproject.org/gdeltv2/masterfilelist-translation.txt", "/tmp/masterfilelist_translation.txt")
Then, put the file that contains the list of the files to download into the S3 bucket :
awsClient.putObject("fabien-mael-telecom-gdelt2018", "masterfilelist.txt", new File("/tmp/masterfilelist.txt") )
awsClient.putObject("fabien-mael-telecom-gdelt2018", "masterfilelist_translation.txt", new File( "/tmp/masterfilelist_translation.txt") )
We will focus only on year 2018 :
val list_csv = spark.read.format("csv").option("delimiter", " ").
csv("s3a://fabien-mael-telecom-gdelt2018/masterfilelist.txt").
withColumnRenamed("_c0","size").
withColumnRenamed("_c1","hash").
withColumnRenamed("_c2","url")
val list_2018_tot = list_csv.where(col("url").like("%/2018%"))
We download all the data of 2018 for the English URLs :
list_2018_tot.select("url").repartition(100).foreach( r=> {
val URL = r.getAs[String](0)
val fileName = r.getAs[String](0).split("/").last
val dir = "/mnt/tmp/"
val localFileName = dir + fileName
fileDownloader(URL, localFileName)
val localFile = new File(localFileName)
AwsClient.s3.putObject("fabien-mael-telecom-gdelt2018", fileName, localFile )
localFile.delete()
})
We duplicate this task for the translation data. Then, we need to create four data frames :
- Mentions in english
- Events in english
- Mentions translated
- Events translated
This is done the following way :
val mentionsRDD_trans = sc.binaryFiles("s3a://fabien-mael-telecom-gdelt2018/201801*translation.mentions.CSV.zip"). // charger quelques fichers via une regex
flatMap { // decompresser les fichiers
case (name: String, content: PortableDataStream) =>
val zis = new ZipInputStream(content.open)
Stream.continually(zis.getNextEntry).
takeWhile{ case null => zis.close(); false
case _ => true }.
flatMap { _ =>
val br = new BufferedReader(new InputStreamReader(zis))
Stream.continually(br.readLine()).takeWhile(_ != null)
}
}
val mentionsDF_trans = mentionsRDD_trans.map(x => x.split("\t")).map(row => row.mkString(";")).map(x => x.split(";")).toDF()
In order to reach fast responding queries, we create several smaller data frames for the different queries we later on build. For example :
// Mentions
val mentions_trans_1 = mentionsDF_trans.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(14).as("language")
)
val mentions_1 = mentionsDF.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(14).as("language")
)
// Events
val events_trans_1 = exportDF_trans.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(1).as("day"),
$"_tmp".getItem(33).as("numarticles"),
$"_tmp".getItem(53).as("actioncountry")
)
val events_1 = exportDF.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(1).as("day"),
$"_tmp".getItem(33).as("numarticles"),
$"_tmp".getItem(53).as("actioncountry")
)
// Join english and translated data
val df_events_1 = events_1.union(events_trans_1)
val df_mentions_1 = mentions_1.union(mentions_trans_1)
// Join events and mentions
val df_1 = df_mentions_1.join(df_events_1,"GlobalEventID")
We can later on build the Cassandra tables that will allow us transfer the spark dataframes :
%cassandra
CREATE TABLE q1_1(
day int,
language text,
actioncountry text,
numarticles int,
PRIMARY KEY (day, language, actioncountry));
Finally, we can write the dataframe to Cassandra. Therefore, the lazy evaluation will take place before we add requests to the data base.
df_1.write.cassandraFormat("q1_1", "gdelt_datas").save()
val df_1_1 = spark.read.cassandraFormat("q1_1", "gdelt_datas").load()
df_1_1.createOrReplaceTempView("q1_1")
The requests are then simple to make :
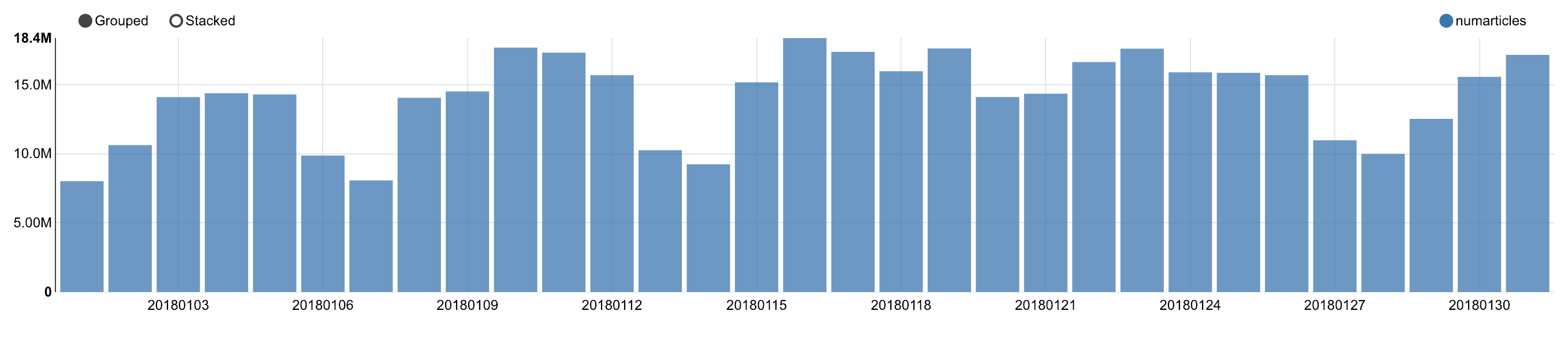
z.show(spark.sql(""" SELECT * FROM q1_1 ORDER BY NumArticles DESC LIMIT 10 """))
Zeppelin also has a great feature of Map Visualization. In order to activate it, you need to activate the Helium Zeppelin Leaflet in Zeppelin.
Simply click on Helium from the interpreter menu, and activate “Zeppelin Leaflet”. A new option on the Zeppelin show request will then appear :
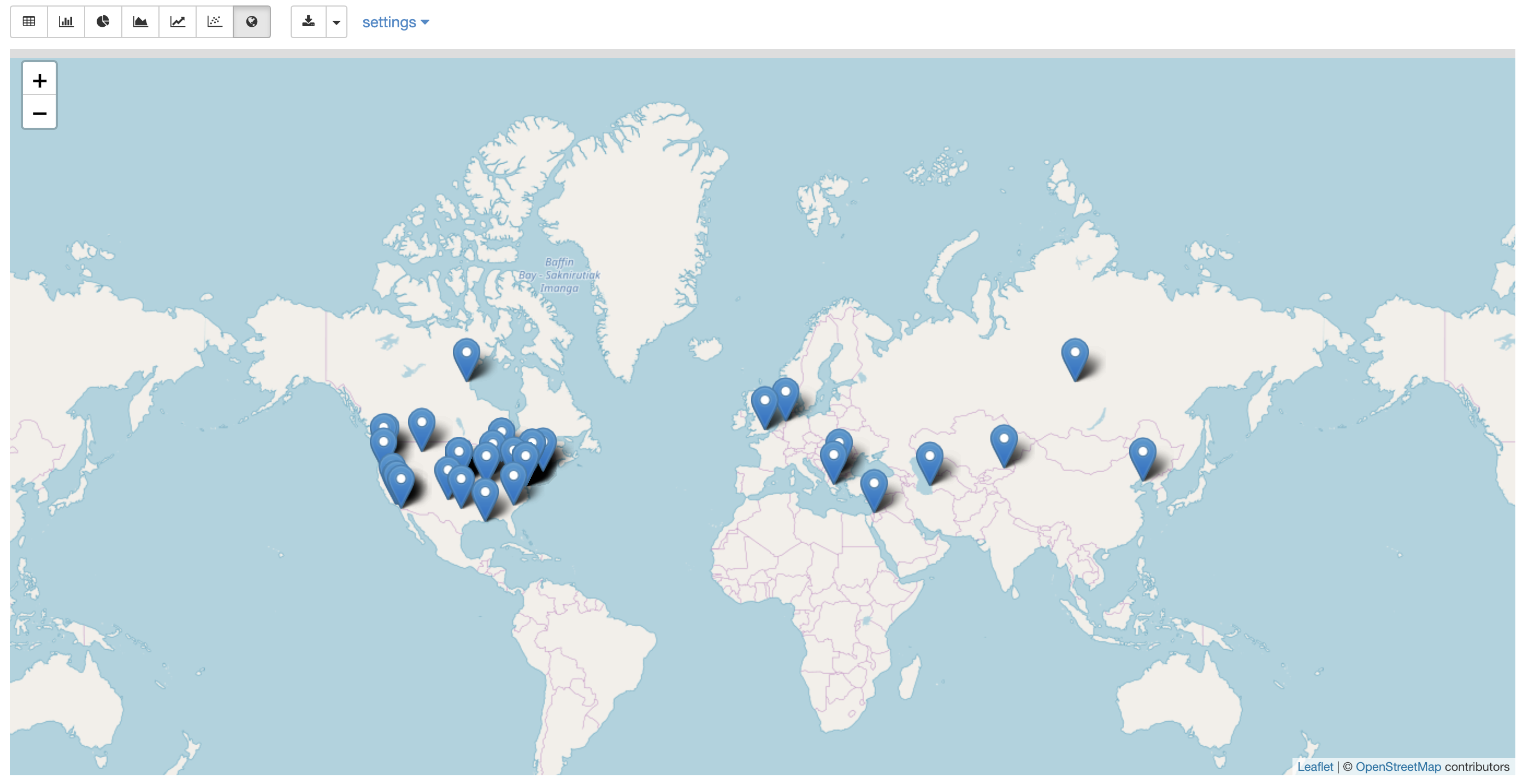
4. Exploration
We will present in this section the results of the analsis we lead on the Cassandra tables :
-
Number of articles by day and language
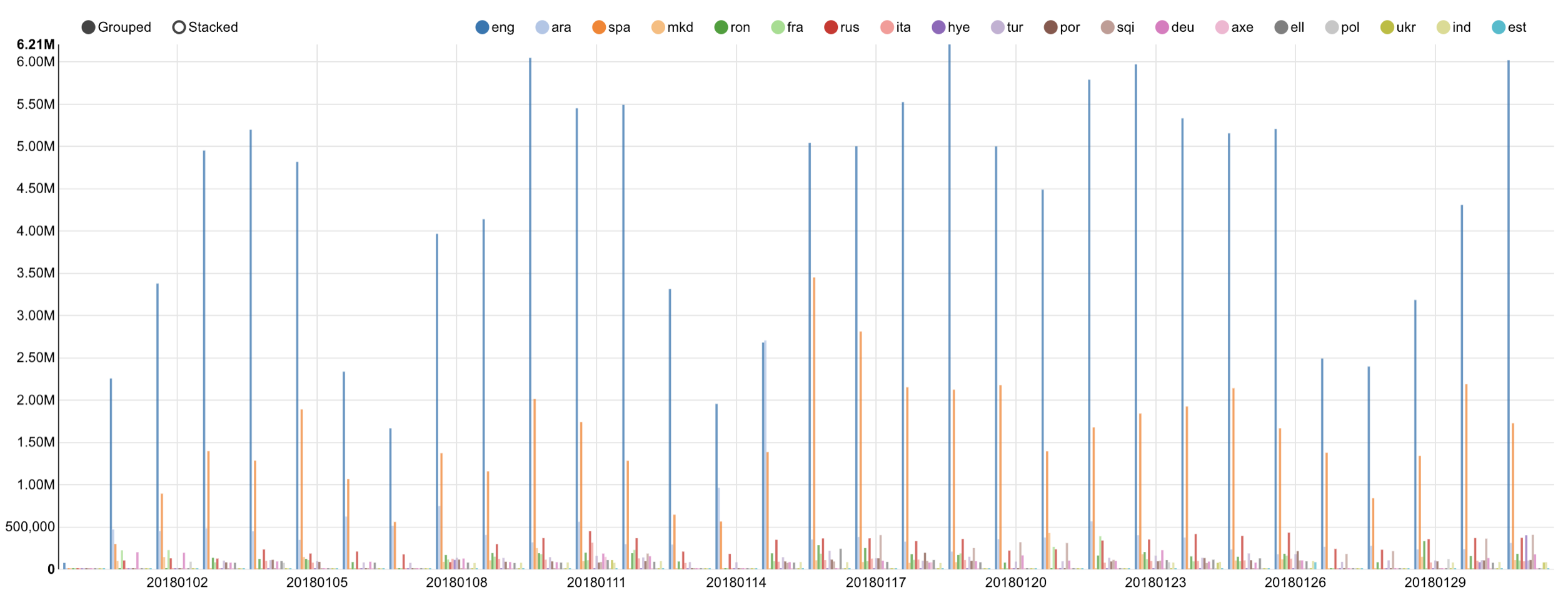
-
Number of articles by day
-
Number of articles by language
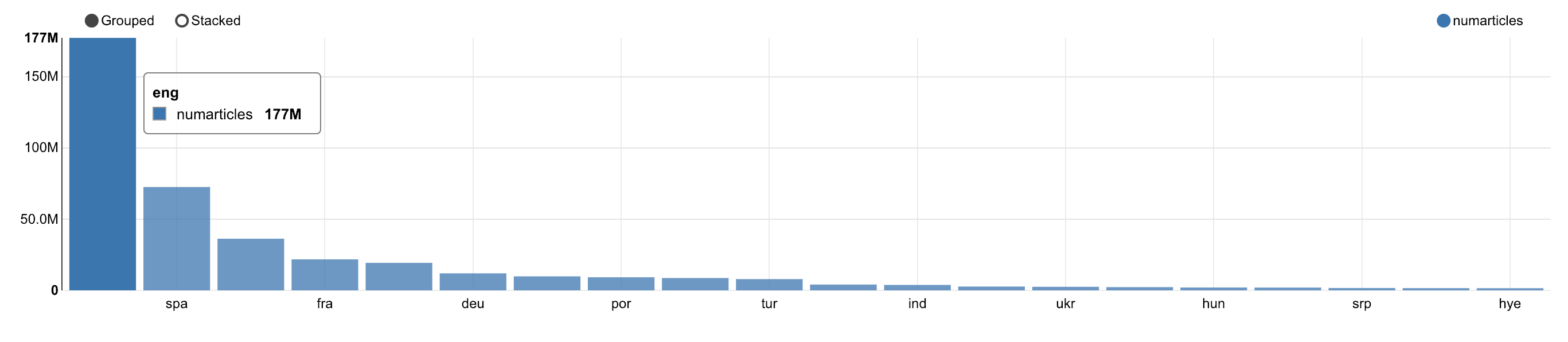
-
Countries which received the most negative articles
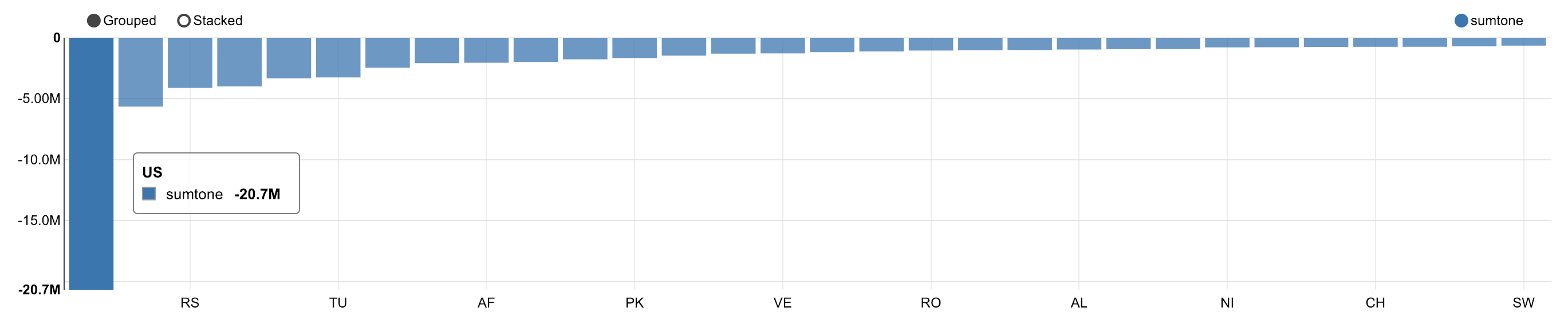
-
Actors or countries that divide the most
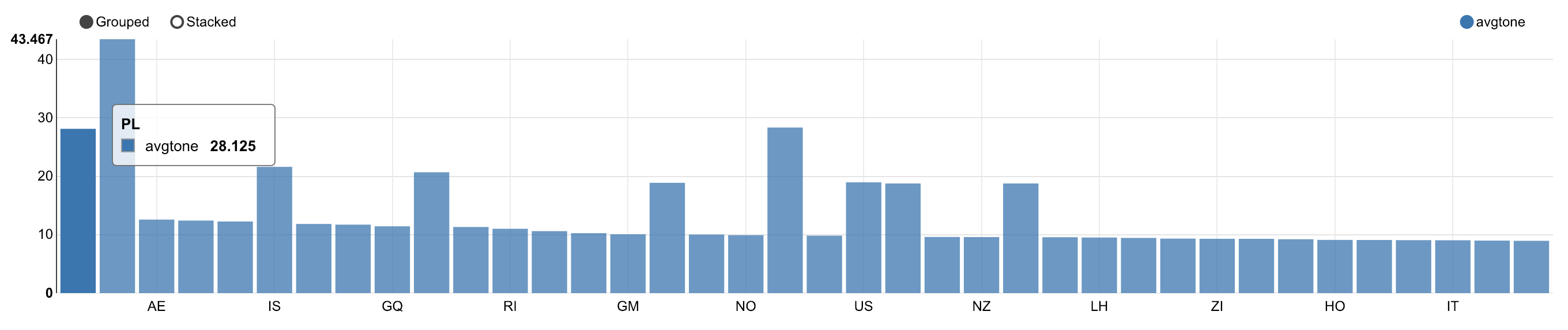
-
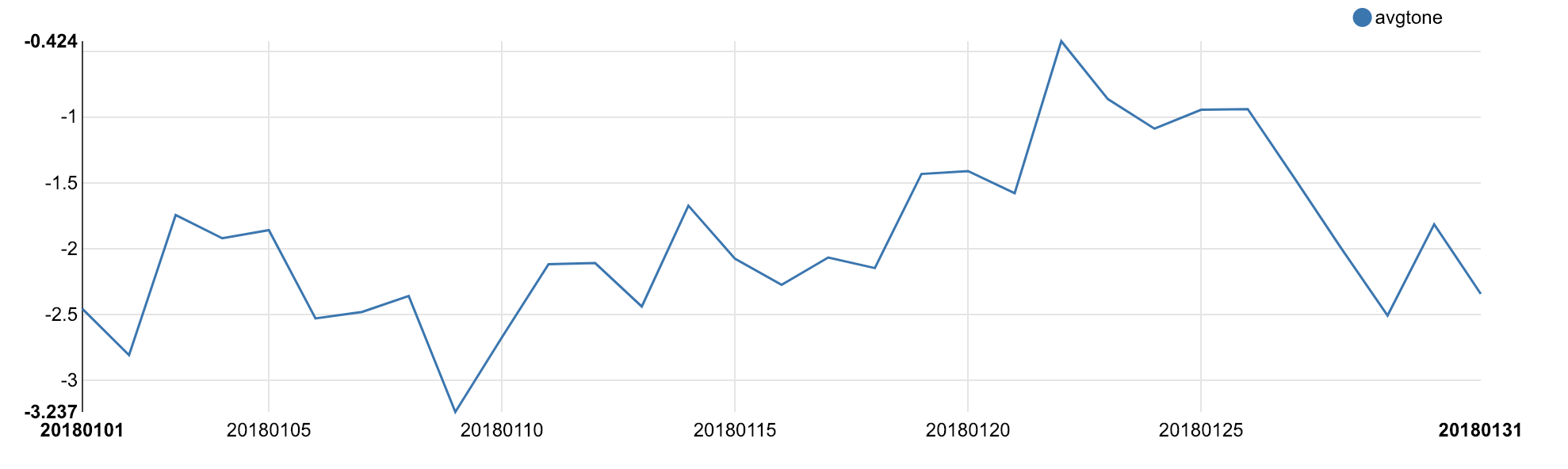
Evolution of the relation two countries (Here USA and Israel)
5. Performance
The total zipped files (Mentions, Events, GKG) reached 698.9 Gb on our S3 bucket.
aws s3 ls --summarize --human-readable --recursive s3://fabien-mael-telecom-gdelt2018

In order to write the files into Cassandra, for 1 month of data, the requests usually took around 20 minutes. Then, once loaded, the different requests could be loaded within 1 to 10 seconds at most.
6. Resiliency
By killing a worker from AWS :

The resiliency should be observed. The requests should always be able to run due to the replication factor of Cassandra.
Also, if one of the Spark master nodes fail, Zookeeper elects a new leader node and workers switch to the new leader node.
7. Budget
One should take into account the budget of implementing such structure. The costs for our project was the following :
- S3 storage and EMR to load the data in Cassandra : 150$
- EC2 instances : 60$
For an overall budget of 210$. The architecture was up for 3 days.
8. Potential improvements
Some recent projects on the GDELT Project include :
- a streaming architecture updating the data every 15 minutes
- a web interface using CartoDB
- a further exploration : Time series, ML, DL
- automate deployment (Ansible, Docker…)