

Zeppelin notebooks are web-based notebooks that enable data-driven, interactive data analytics and collaborative documents with SQL, Scala, Spark and much more. Zeppelin also offers built-in visualizations and allows multiple users when configured on a cluster. In this article, I am going to go through the basic steps that allow you to configure Zeppelin the easy way, locally.
The following procedure was tested on macOS.
Install
First of all, let’s install the dependencies we will later on need. If you do not have homebrew installed, start by running this line in your terminal :
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Then, we need to install Java, Scala, Spark, and Zeppelin.
$ brew cask install java8
$ brew install scala
$ brew install apache-spark
$ brew install apache-zeppelin
Your Zeppelin will be installed here :
/usr/local/Cellar/apache-zeppelin
Running Zeppelin
To run Zeppelin and create a Zeppelin notebook, run the following command :
$ zeppelin-daemon.sh start
If everything goes well, you should see this :
Zeppelin start [ OK ]
There are some useful Zeppelin commands one should know :
$ zeppelin-daemon.sh start -> To start the Daemon
$ zeppelin-daemon.sh stop -> To stop the Daemon
$ zeppelin-daemon.sh restart -> To restart the Daemon
Your Zeppelin Notebook should be accessible from the following link :
http://localhost:8080/
At that point, you should see this :

Click on “Create new note”, leave the Spark interpreter as the default one.
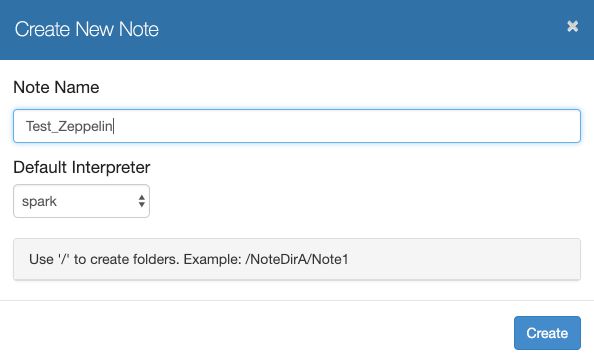
Test your Zeppelin configuration
The default interpreter language is Spark-Scala. In the first cell, simply type :
val i = 1
It should return :
i: Int = 1
There are also Python interpreters in Zeppelin. You can try it the following way :
%python
import numpy as np
If no error is displayed, well, congrats! Your Zeppelin notebook is ready!
**Conclusion **: Your Zeppelin is now configured locally. The next article will include the next step of our road to big data analysis: starting a Zeppelin Notebook on an AWS EMR instance!