

To store the data we downloaded previously, it is now essential to prepare them and split them into different sub-tables. This will allow us to create smaller data sets, and move those sets to Cassandra.
Split the data sets
Suppose we’re building a pretty easy request in which we would like to know the number of articles per day, language and country in which the event took place.
Mentions contains for a given EventID the language in which the article was written.
val mentions_1 = mentionsDF.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(14).as("language")
)
The country of the event, as well as the day of the event, are in the Export table. Instead of selecting all columns (more than 50), we’ll focus on some specific ones :
val events_1 = exportDF.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(1).as("day"),
$"_tmp".getItem(33).as("numarticles"),
$"_tmp".getItem(53).as("actioncountry")
)
We can also replicate those steps for the translated data :
val mentions_trans_1 = mentionsDF_trans.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(14).as("language")
)
val events_trans_1 = exportDF_trans.withColumn("_tmp", $"value").select(
$"_tmp".getItem(0).as("globaleventid"),
$"_tmp".getItem(1).as("day"),
$"_tmp".getItem(33).as("numarticles"),
$"_tmp".getItem(53).as("actioncountry")
)
Join the tables
Once we selected the essential columns of both tables, we can join the tables :
val df_events_1 = events_1.union(events_trans_1)
val df_mentions_1 = mentions_1.union(mentions_trans_1)
// Join events and mentions
val df_1 = df_mentions_1.join(df_events_1,"GlobalEventID")
Build the Cassandra Table
Start cqlsh from the terminal of your instance and create a table to welcome the data :
CREATE TABLE q1_1(
day int,
language text,
actioncountry text,
numarticles int,
PRIMARY KEY (day, language, actioncountry));
Make sure to have the name for the fields, and no capital letters. It happened to cause some troubles in our project.
Write the data in Cassandra
Once the data set has been created, since Scala Spark is a lazy evaluation framework, we have to compute the data set and load the data into Cassandra at the same time :
df_1.write.cassandraFormat("q1_1", "gdelt_datas").save()
val df_1_1 = spark.read.cassandraFormat("q1_1", "gdelt_datas").load()
df_1_1.createOrReplaceTempView("q1_1")
It might take some time (several minutes). Once done, all your data for this specific query are in Cassandra!
Query Cassandra Tables
Since we prepared the data to fit the queries, our queries are really simple to make in Zeppelin :
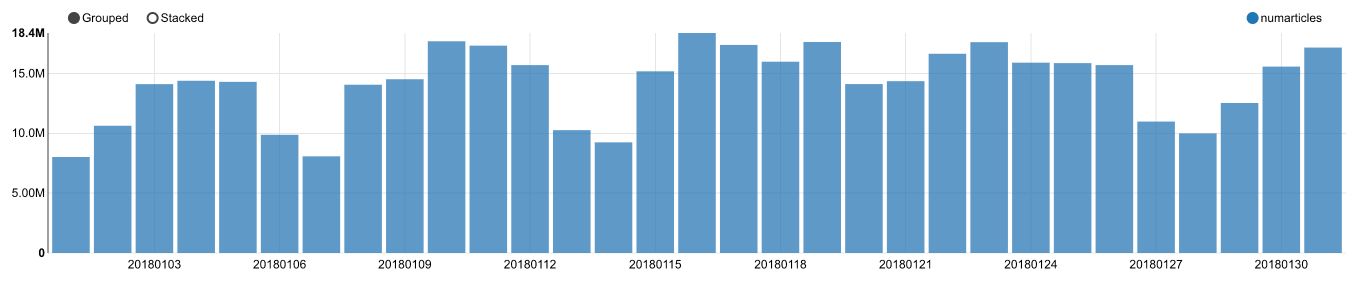
z.show(spark.sql(""" SELECT * FROM q1_1 ORDER BY NumArticles DESC LIMIT 10 """))
The results will be displayed directly in Zeppelin :
**Conclusion **: This project is now over! We have loaded several GB of zipped files in S3, built a resilient architecture using AWS, Cassandra and ZooKeeper, and finally manipulated and transferred the data to make fast, simple queries on large data sets.