

The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. We’ll see how to configure Cassandra on an AWS EC2 cluster and create a resilient architecture that is big-data ready.
SSH Connection to the nodes
In the architecture we considered, we essentially focused on deploying Cassandra on slave nodes. The steps detailed below can also be used for deploying Cassandra on your Masters.
The first step is to establish an SSH connection with your Slave nodes. Recall :
ssh -i "<path to your keyPair directory>/Cluster_test_Key_Pair.pem" ubuntu@<copy the public DNS>
All the steps below should be made for all the slave nodes.
Install Java SDK 8
Ones your instances are up and running and the SSH tunnel is established, we need to install Java SDK. Java 8 is indeed required to run Cassandra. Luckily, the installation process is quite simple.
Run the following command :
sudo apt install openjdk-8-jre-headless
Once done, we need to define some exports that will allow us to launch Cassandra easily. Open VI to edit the bashrc file :
vi ~/.bashrc
Then, add the following lines to the file (you might have to type the letter “i” to insert newlines) :
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
To quit and save changes, press ‘ESC’ and then write :wq and press ‘ENTER’.
Once you’re back on the terminal, execute the following line: source ~/.bashrc
Install Cassandra
a. From Apache Cassandra’s website, copy the download link (version of January 2019) :

b. Install Apache-Cassandra on your instances
From your terminal, go to : /ubuntu/home/
Them, execute :
wget http://wwwftp.ciril.fr/pub/apache/cassandra/3.11.3/apache-cassandra-3.11.3-bin.tar.gz
If a new version of Cassandra has been released, make sure to replace the link above by the latest version.
You should see something similar :

c. The files are compressed. The next step is to uncompress them and extract the software :
tar -xv apache-cassandra-3.11.3-bin.tar.gz
Then, remove the .tar.gz file :
rm apache-cassandra-3.11.3-bin.tar.gz

d. Replicate the steps above on each slave
Configuration of your 5 nodes cluster
We will need to modify 2 files :
cassandra.yamlcassandra-rackdc.properties
Those two files are located in the conf directory :
cd apache-cassandra-3.11.3/conf/
a. Modify the cassandra.yaml file :
Open the file :
vi cassandra.yaml
Change the following fields :
cluster_name: give the name you want (e.g Cluster1)listen_address: Give it a private IP address specific to this noderpc_address: Give it again this private IP address specific to this nodeseed_provider: A private IP address common to all instancesendpoint_snitch: Set it toEc2Snitch
Save and quit. Here’s a quick example :
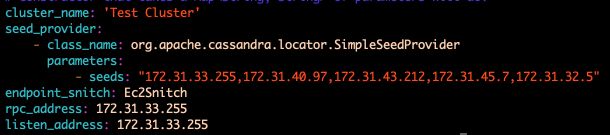
Repeat those steps on the 5 Slave nodes.
b. Modify the cassandra-rackdc.properties file :
We will consider the simplest framework here: we won’t specify any rack name or data center name. Just comment on the two lines that are not commented :
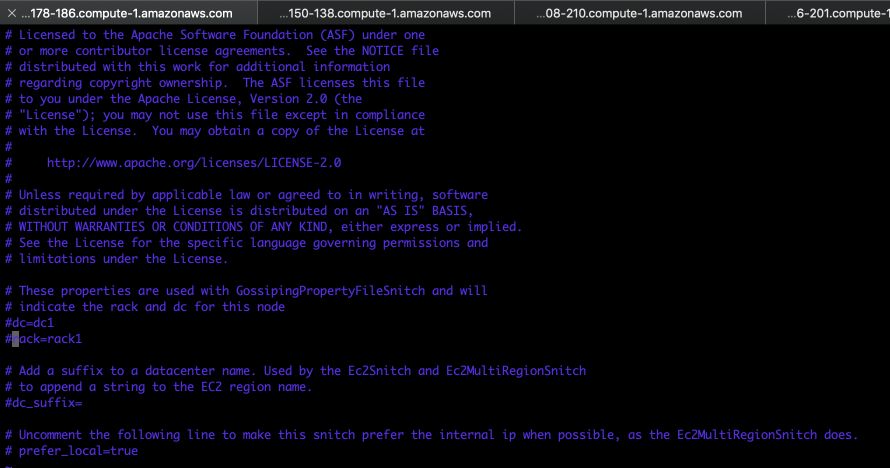
The configuration is now ready!
Try the connection between every Cassandra node
Go in the bin directory :
$ cd ./bin
For each node, execute the following command :
./cassandra
Some lines contain the keyword “Handshaking” which means that the nodes communicate.
There is a command to directly describe the connections of your cluster :
./nodetool describecluster
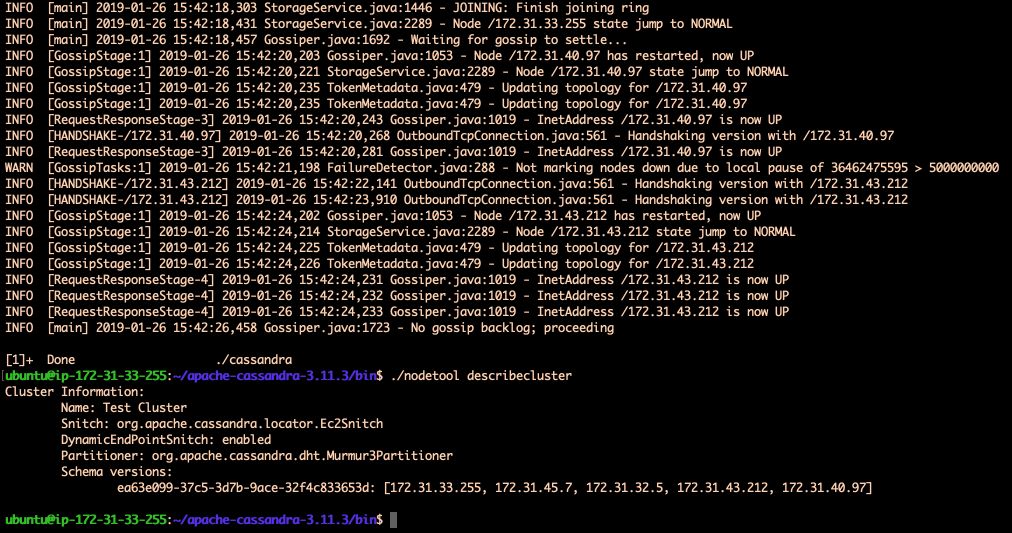
Your Slave nodes with Apache-Cassandra are now configured!
*Conclusion *: The next step is to install and configure Zookeeper for the resilience of Spark!