
The GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world. With new files uploaded every 15 minutes, GDELT databases contain more than 700 Gb of zipped data for the single year 2018.

The project
In this series of articles, I am going to present you a recent school project we worked on: Building a resilient architecture for storing a large amount of data from the GDELT project, and building fast responding queries.
The GitHub of this project can be found here : https://github.com/maelfabien/Cassandra-GDELT-Queries
To be able to work with a large amount of data, we have chosen to work with the following architecture :
- NoSQL Database: Cassandra
- AWS: EMR to transfer the data to Cassandra, and EC2 for the resiliency for the requests
- Visualization: A Zeppelin Notebook
The data
The following links describe the data in the GDELT table :
- Description of the data Mentions and Events : http://data.gdeltproject.org/documentation/GDELT-Event_Codebook-V2.0.pdf
- Description of the Graph of Events GKG : http://data.gdeltproject.org/documentation/GDELT-Global_Knowledge_Graph_Codebook-V2.1.pdf
The tables are the following :
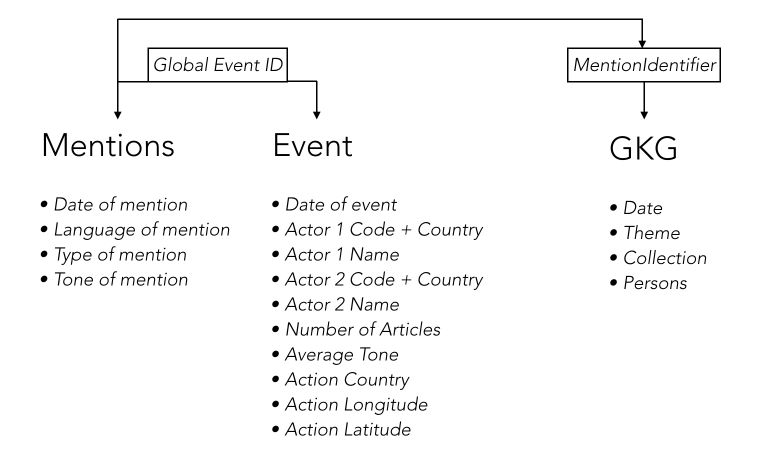
An event is defined as an action that an actor (Actor1) takes on another actor (Actor2). Mention is an article or any source that talks about an event. The GKG database reflects the events that took place in the world, ordered by theme, type of event and location.
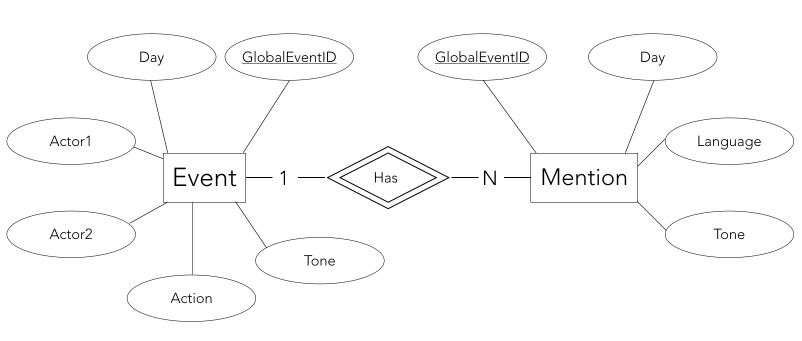
The conceptual model of the data is the following :
Architecture
The architecture we have chosen is the following :
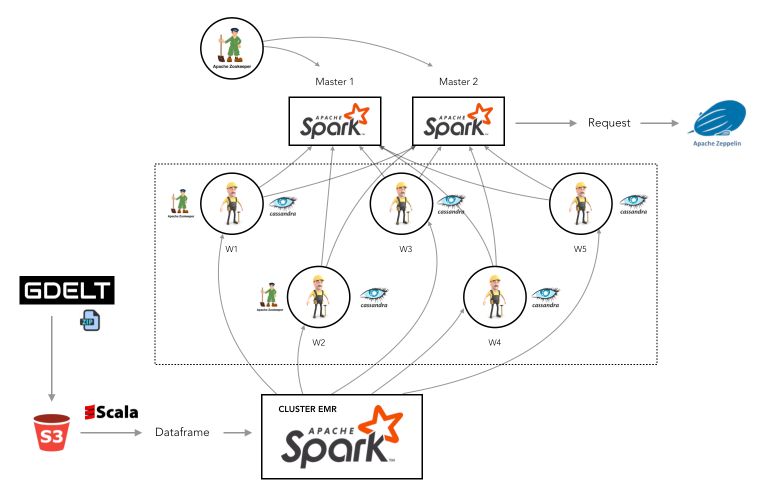
Our architecture is composed of one cluster EMR (1 master and 5 slaves) and one cluster EC2 (8 instances).
In our 8 EC2 instances we have :
- 2 Masters nodes with apache-Spark-2.3.2 and apache-Zeppelin-0.8.0
- 5 Slaves nodes with apache-Spark-2.3.2 and apache-cassandra-3.11.2, including zookeeper installed on 2 of these nodes.
The last one is a node created for the resilience of the Master. We Installed zookeeper in it. The architecture will be further described in a future article.
The data is stored as a set of zipped CSV Files. The overall size for the year 2018 reaches 700 Gb. To process such a huge amount of data, the approach we chose is the following :
- download all the CSV zipped files and load them to an S3 bucket
- using Spark-Scala, download all the data in the S3 bucket and load them as data frames in a Zeppelin Notebook
- clean the data and split them into several data frames
- load the different data frames in Cassandra
- make requests in CQL or using spark-cassandra connector directly in Zeppelin
The next articles aim at describing how to build a resilient database architecture that would allow simple and fast queries on a large amount of data.