
Emotion Recognition WebApp
We developped a multimodal emotion recognition platform to analyze the emotions of job candidates, in partnership with the French Employment Agency.
We analyze facial, vocal and textual emotions, using mostly deep learning based approaches.
Real-Time Multimodal Emotion Recognition
In a nutshell
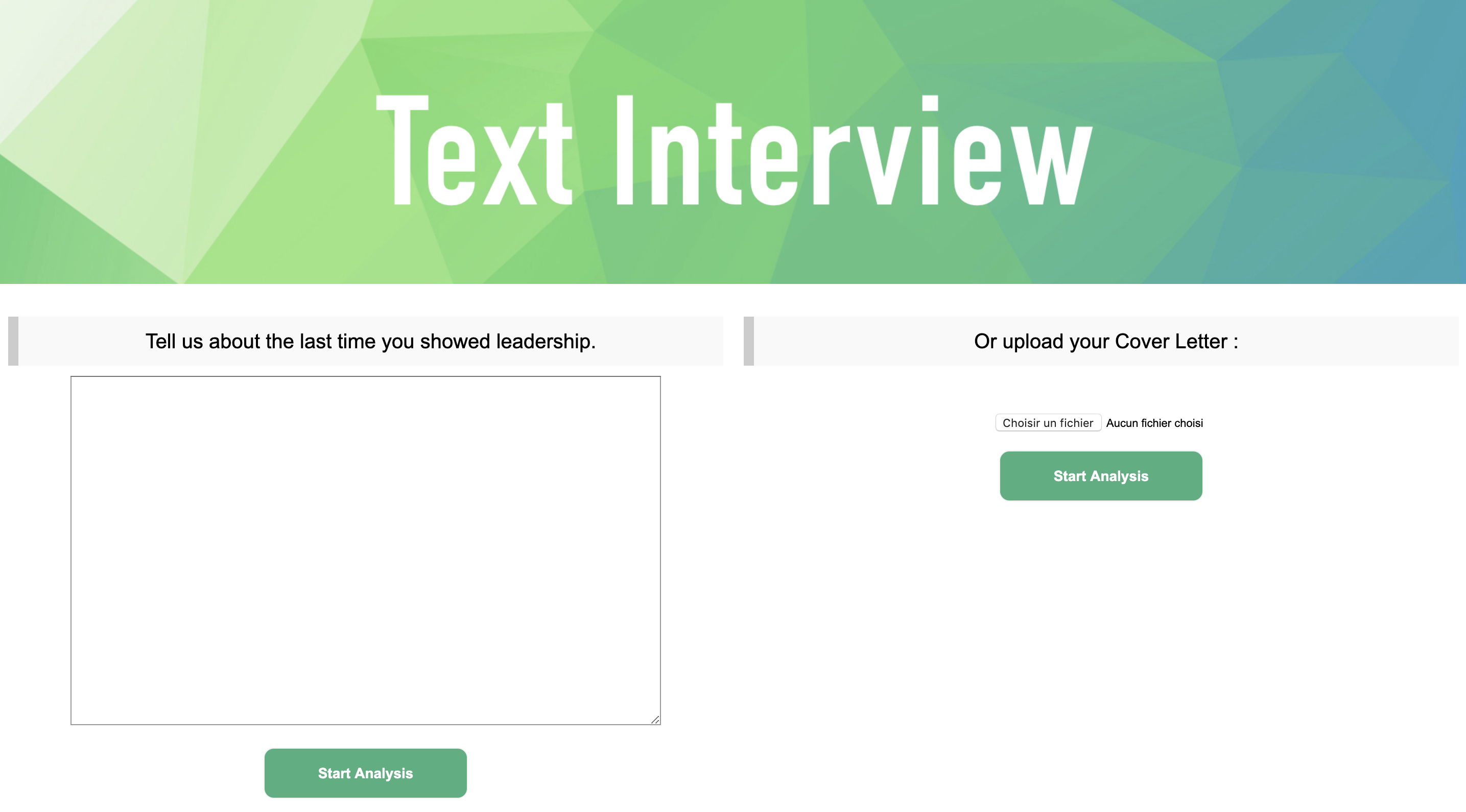
We deployed a web app using Flask :

We have also written a paper on our work
In this project, we are exploring state of the art models in multimodal sentiment analysis. We have chosen to explore text, sound and video inputs and develop an ensemble model that gathers the information from all these sources and displays it in a clear and interpretable way.
Contributors : Raphael Lederman, Anatoli De Bradke, Stéphane Reynal, Maël Fabien
The Github of the project can be found here :
Technologies

I. Context
Affective computing is a field of Machine Learning and Computer Science that studies the recognition and the processing of human affects. Multimodal Emotion Recognition is a relatively new discipline that aims to include text inputs, as well as sound and video. This field has been rising with the development of social network that gave researchers access to a vast amount of data.
II. Data Sources
We have chosen to diversify the data sources we used depending on the type of data considered. All data sets used are free of charge and can be directly downloaded.
- For the text input, we are using the Stream-of-consciousness dataset that was gathered in a study by Pennebaker and King [1999]. It consists of a total of 2,468 daily writing submissions from 34 psychology students (29 women and 5 men whose ages ranged from 18 to 67 with a mean of 26.4). The writing submissions were in the form of a course unrated assignment. For each assignment, students were expected to write a minimum of 20 minutes per day about a specific topic. The data was collected during a 2-week summer course between 1993 to 1996. Each student completed their daily writing for 10 consecutive days. Students’ personality scores were assessed by answering the Big Five Inventory (BFI) [John et al., 1991]. The BFI is a 44-item self-report questionnaire that provides a score for each of the five personality traits. Each item consists of short phrases and is rated using a 5-point scale that ranges from 1 (disagree strongly) to 5 (agree strongly). An instance in the data source consists of an ID, the actual essay, and five classification labels of the Big Five personality traits. Labels were originally in the form of either yes (‘y’) or no (‘n’) to indicate scoring high or low for a given trait.
- For audio data sets, we are using the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). This database contains 7356 files (total size: 24.8 GB). The database contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions, and song contains calm, happy, sad, angry, and fearful emotions. Each expression is produced at two levels of emotional intensity(normal, strong), with an additional neutral expression. All conditions are avail-able in three modality formats: Audio-only (16bit, 48kHz .wav), Audio-Video(720p H.264, AAC 48kHz, .mp4), and Video-only (no sound).” here
- For the video data sets, we are using the popular FER2013 Kaggle Challenge data set. The data consists of 48x48 pixel grayscale images of faces. The faces have been automatically registered so that the face is more or less centered and occupies about the same amount of space in each image. The data set remains quite challenging to use, since there are empty pictures, or wrongly classified images. here
III. Download
| Modality | Data | Processed Data (for training) | Pre-trained Model | Colab Notebook | Other |
|---|---|---|---|---|---|
| Text | here | X-train y-train X-test y-test | Weights Model | — | — |
| Audio | here | X-train y-train X-test y-test | Weights Model | Colab Notebook | — |
| Video | here | X-train y-train X-test y-test | Weights Model | Colab Notebook | Face Detect Model |
IV. Methodology
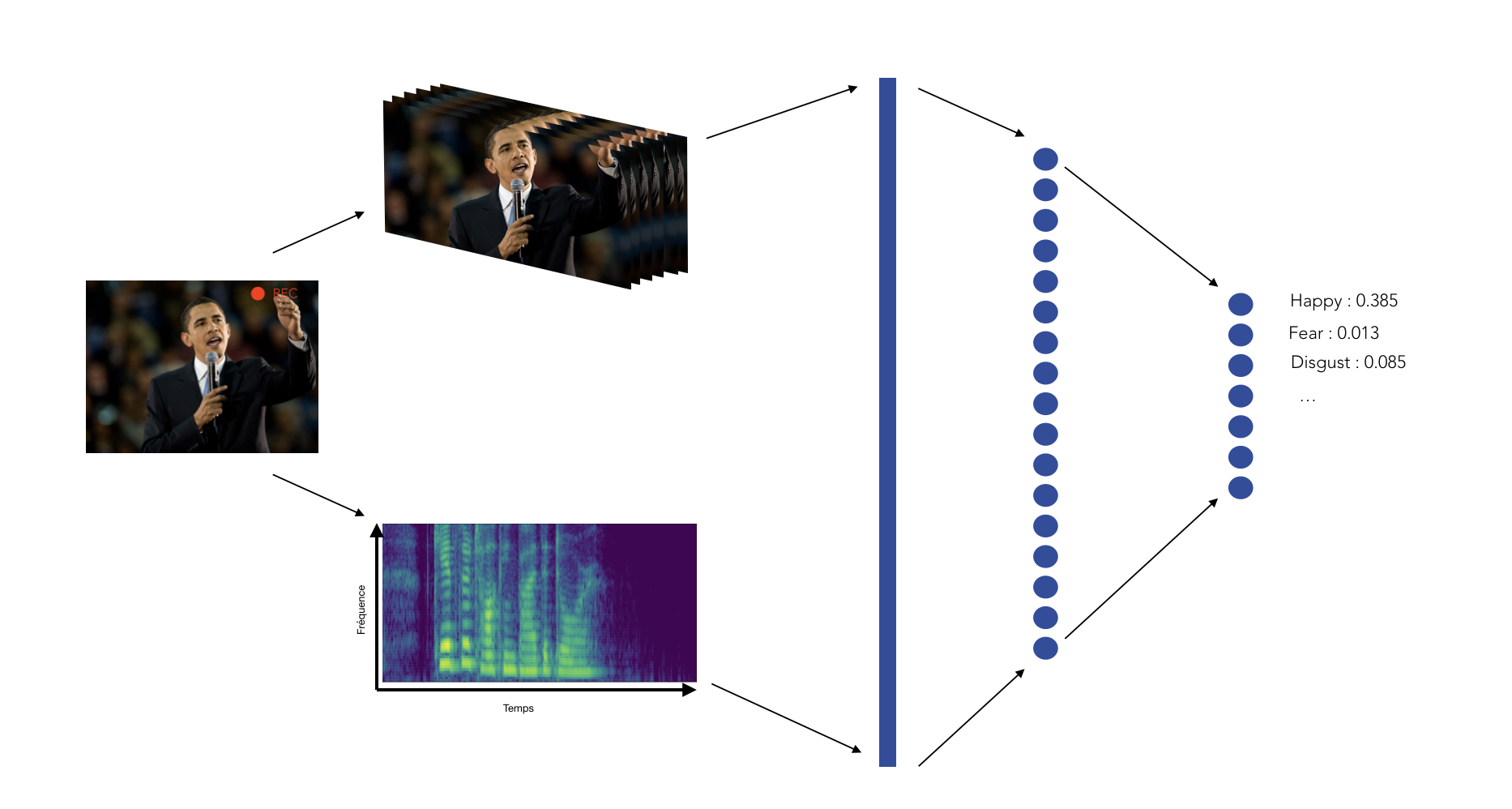
Our aim is to develop a model able to provide a live sentiment analysis with a visual user interface.Therefore, we have decided to separate two types of inputs :
- Textual input, such as answers to questions that would be asked to a person from the platform
- Video input from a live webcam or stored from an MP4 or WAV file, from which we split the audio and the images
a. Text Analysis
Pipeline
The text-based personality recognition pipeline has the following structure :
- Text data retrieving
- Custom natural language preprocessing :
- Tokenization of the document
- Cleaning and standardization of formulations using regular expressions
- Deletion of the punctuation
- Lowercasing the tokens
- Removal of predefined stopwords
- Application of part-of-speech tags on the remaining tokens
- Lemmatization of tokens using part-of-speech tags for more accuracy.
- Padding the sequences of tokens of each document to constrain the shape of the input vectors.
- 300-dimension Word2Vec trainable embedding
- Prediction using our pre-trained model
Model
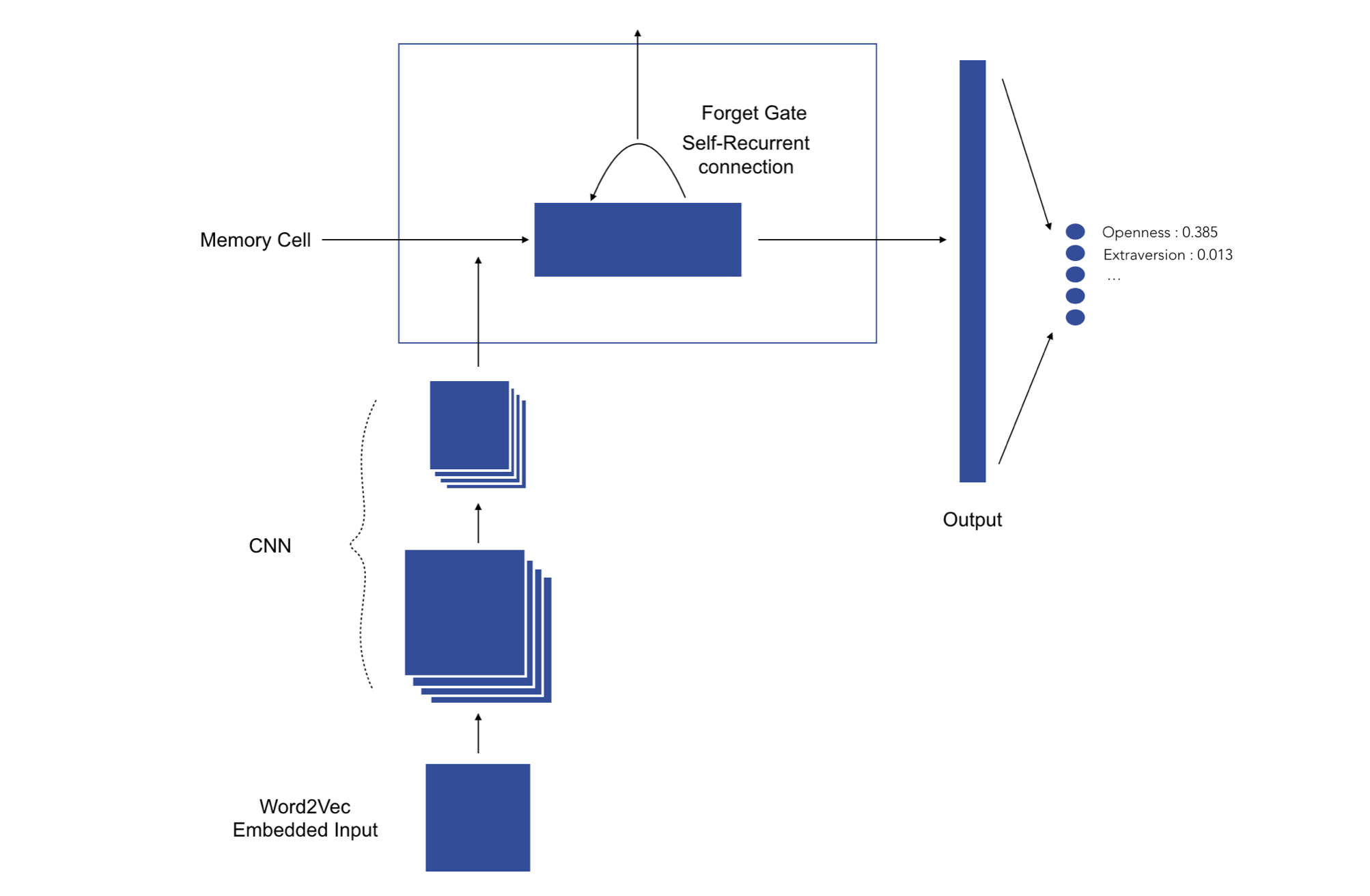
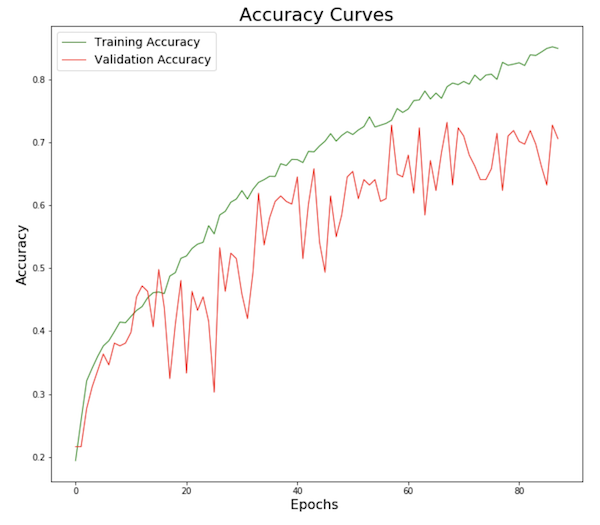
We have chosen a neural network architecture based on both one-dimensional convolutional neural networks and recurrent neural networks. The one-dimensional convolution layer plays a role comparable to feature extraction : it allows finding patterns in text data. The Long-Short Term Memory cell is then used in order to leverage on the sequential nature of natural language : unlike regular neural network where inputs are assumed to be independent of each other, these architectures progressively accumulate and capture information through the sequences. LSTMs have the property of selectively remembering patterns for long durations of time. Our final model first includes 3 consecutive blocks consisting of the following four layers : one-dimensional convolution layer - max pooling - spatial dropout - batch normalization. The numbers of convolution filters are respectively 128, 256 and 512 for each block, kernel size is 8, max pooling size is 2 and dropout rate is 0.3. Following the three blocks, we chose to stack 3 LSTM cells with 180 outputs each. Finally, a fully connected layer of 128 nodes is added before the last classification layer.
b. Audio Analysis
Pipeline
The speech emotion recognition pipeline was built the following way :
- Voice recording
- Audio signal discretization
- Log-mel-spectrogram extraction
- Split spectrogram using a rolling window
- Make a prediction using our pre-trained model
Model
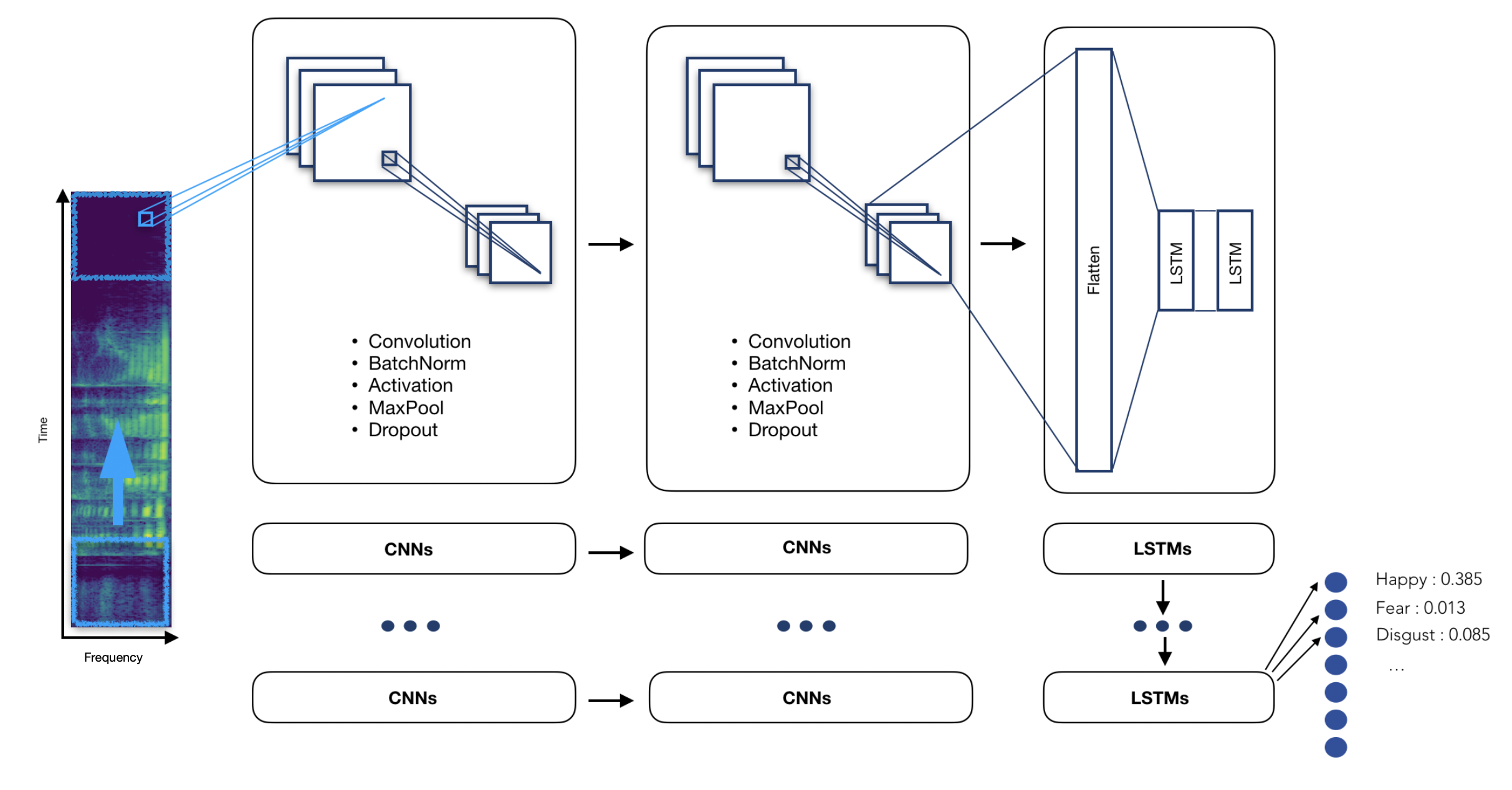
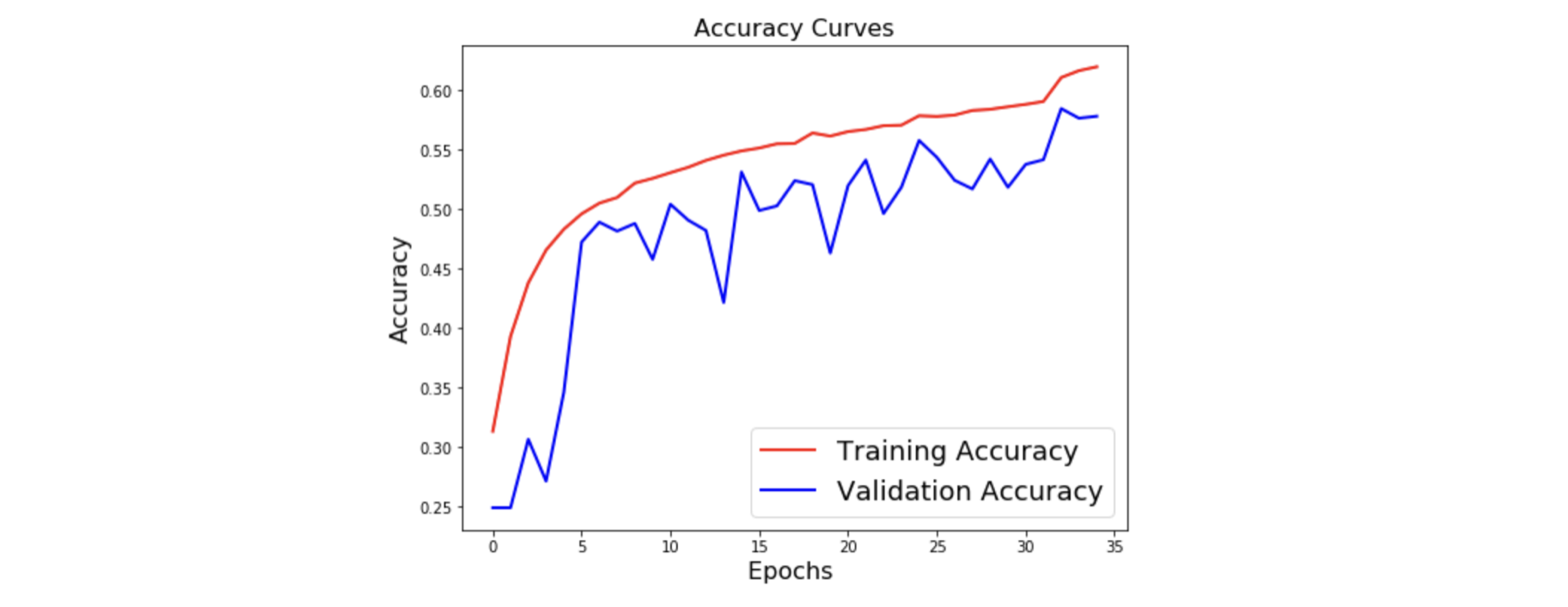
The model we have chosen is a Time Distributed Convolutional Neural Network.
The main idea of a Time Distributed Convolutional Neural Network is to apply a rolling window (fixed size and time-step) all along the log-mel-spectrogram. Each of these windows will be the entry of a convolutional neural network, composed by four Local Feature Learning Blocks (LFLBs) and the output of each of these convolutional networks will be fed into a recurrent neural network composed by 2 cells LSTM (Long Short Term Memory) to learn the long-term contextual dependencies. Finally, a fully connected layer with softmax activation is used to predict the emotion detected in the voice.
To limit overfitting, we tuned the model with :
- Audio data augmentation
- Early stopping
- And kept the best model
c. Video Analysis
Pipeline
The video processing pipeline was built the following way :
- Launch the webcam
- Identify the face by Histogram of Oriented Gradients
- Zoom on the face
- Dimension the face to
48 * 48pixels - Make a prediction on the face using our pre-trained model
- Also identify the number of blinks on the facial landmarks on each picture
Model
The model we have chosen is an XCeption model, since it outperformed the other approaches we developed so far. We tuned the model with :
- Data augmentation
- Early stopping
- Decreasing learning rate on plateau
- L2-Regularization
- Class weight balancing
- And kept the best model
As you might have understood, the aim was to limit overfitting as much as possible in order to obtain a robust model.
- To know more on how we prevented overfitting, check this article
- To know more on the XCeption model, check this article
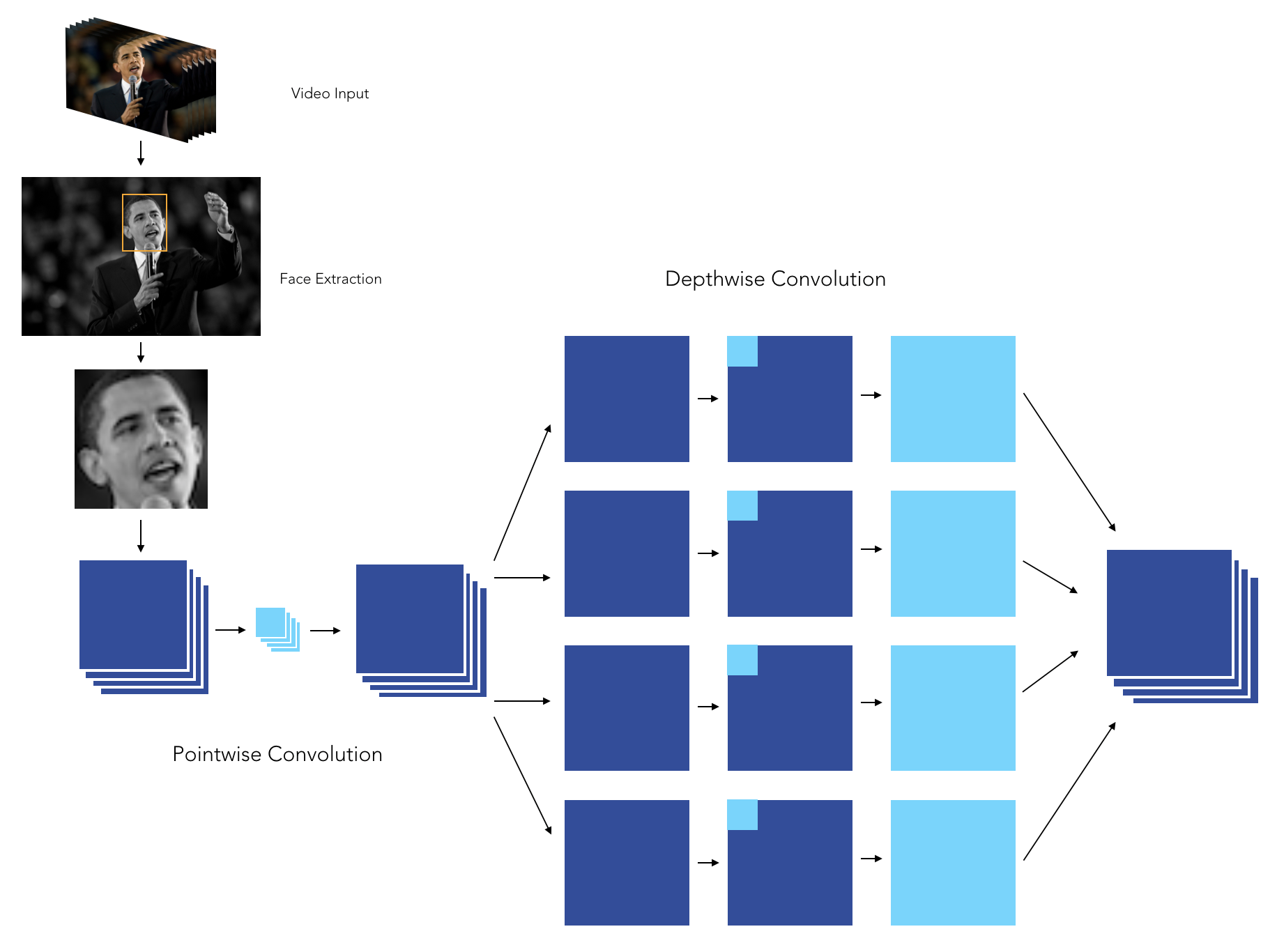
The XCeption architecture is based on DepthWise Separable convolutions that allow to train much fewer parameters, and therefore reduce training time on Colab’s GPUs to less than 90 minutes.
When it comes to applying CNNs in real life application, being able to explain the results is a great challenge. We can indeed plot class activation maps, which display the pixels that have been activated by the last convolution layer. We notice how the pixels are being activated differently depending on the emotion being labeled. The happiness seems to depend on the pixels linked to the eyes and mouth, whereas the sadness or the anger seem for example to be more related to the eyebrows.

d. Ensemble Model
The ensemble model has not been implemented on this version.
V. How to use it ?
There are several resources available :
- the working notebooks can be found in the Text/Video/Audio sections
- the final notebooks can be accessed through the Google Colab link in the table at the beginning
To use the web app :
- Clone the project locally
- Go in the WebApp folder
- Run
$ pip install -r requirements.txt - Launch
python app.py
VI. Research Paper
If you are interested in the research paper, here it is :
VII. Contributors

Anatoli-deBRADKE 💻 |

maelfabien 💻 |

RaphaelLederman 💻 |

STF-R 💻 |