
Voice Gender Identification
Can we detect the gender of a voice using ML methods? I recently came across this article which I found quite interesting in the way it addresses Gender Identification from vocal recordings.
Voice gender identification relies on three important steps:
- Extracting from the training set MFCC features (13 per time window usually)
- Train two Gaussian Mixture Models (GMMs) on the feature matrices created (N_records x 13), one for each genre
- In prediction, compute the likelihood of each gender using the trained GMMs, and pick the most likely gender
The Github repository for this article can be found here.
The aim of this project is to build a web application using Streamlit in which a user is able to test the trained algorithm on his or her own voice.
Let’s build it
Data and imports
⚠️ The dataset has been extracted from AudioSet and can be downloaded from here directly.
Start by importing the libraries that we will need to build this application:
# Data manipulation
import numpy as np
import matplotlib.pyplot as plt
# Feature extraction
import scipy
import librosa
import python_speech_features as mfcc
import os
from scipy.io.wavfile import read
# Model training
from sklearn.mixture import GaussianMixture as GMM
from sklearn import preprocessing
import pickle
# Live recording
import sounddevice as sd
import soundfile as sf
If you have not yet understood or seen the concept of Mel Frequency Cepstral Coefficients (MFCC), I recommend that you take a look at the article I wrote on the topic of Sound Feature Extraction.
Feature Extraction
The concept behind this approach to gender detection is really simple. We first create a feature matrix from the training audio recordings. MFCCs are extracted on really small time windows (±20ms), and when you run an MFCC feature extraction using python_speech_features or Librosa, it automatically creates a matrix for the whole recording.
Knowing that, extracting the MFCC of a audio file is really easy:
def get_MFCC(sr,audio):
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, appendEnergy = False)
features = preprocessing.scale(features)
return features
I placed the training data in a folder called AudioSet, in which I have two sub-folders: male_clips and female_clips. We can extract the features of the training set simply by running the function above on all files in the training folder. The problem is however that for the moment, both the train and the test set are in the folder. We must, therefore, split these files in two, and run get_MFCC iteratively.
def get_features(source):
# Split files
files = [os.path.join(source,f) for f in os.listdir(source) if f.endswith('.wav')]
len_train = int(len(files)*0.8)
train_files = files[:len_train]
test_files = files[len_train:]
# Train features
features_train = []
for f in train_files:
sr, audio = read(f)
vector = get_MFCC(sr,audio)
if len(features_train) == 0:
features_train = vector
else:
features_train = np.vstack((features_train, vector))
# Test features
features_test = []
for f in test_files:
sr, audio = read(f)
vector = get_MFCC(sr,audio)
if len(features_test) == 0:
features_test = vector
else:
features_test = np.vstack((features_test, vector))
return features_train, features_test
GMM model training
“A Gaussian Mixture Model (GMM) is a parametric probability density function represented as a weighted sum of Gaussian component densities. (source)
GMMs are commonly used as a parametric model of the probability distribution of continuous measurements or features in a biometric system, such as vocal-tract related spectral features in a speaker recognition system. GMM parameters are estimated from training data using the iterative Expectation-Maximization (EM) algorithm or Maximum A Posteriori(MAP) estimation from a well-trained prior model.”
To apply it to the folder containing the Male recordings, simply use this function, extract the train features and train the Gaussian Mixture Model.
source = "AudioSet/male_clips"
features_train_male, features_test_male = get_features(source)
gmm_male = GMM(n_components = 8, max_iter = 200, covariance_type = 'diag', n_init = 3)
gmm_male.fit(features_train_male)
We can repeat the process for Females:
source = "AudioSet/female_clips"
features_train_female, features_test_female = get_features(source)
gmm_female = GMM(n_components = 8, max_iter=200, covariance_type='diag', n_init = 3)
gmm_female.fit(features_train_female)
Are these features really differentiable for males and females?
We can plot the distribution over the MFCC features for random samples of males and females:
plt.figure(figsize=(15,10))
for i in range(1, 430000, 1000):
plt.plot(features_train_male[i], c='b', linewidth=0.5, alpha=0.5)
plt.plot(features_train_female[i], c='r', linewidth=0.5, alpha=0.5)
plt.plot(features_male[i+1], c='b', label="Male", linewidth=0.5, alpha=0.5)
plt.plot(features_female[i+1], c='r', label="Female", linewidth=0.5, alpha=0.5)
plt.legend()
plt.title("MFCC features for Males and Females")
plt.show()
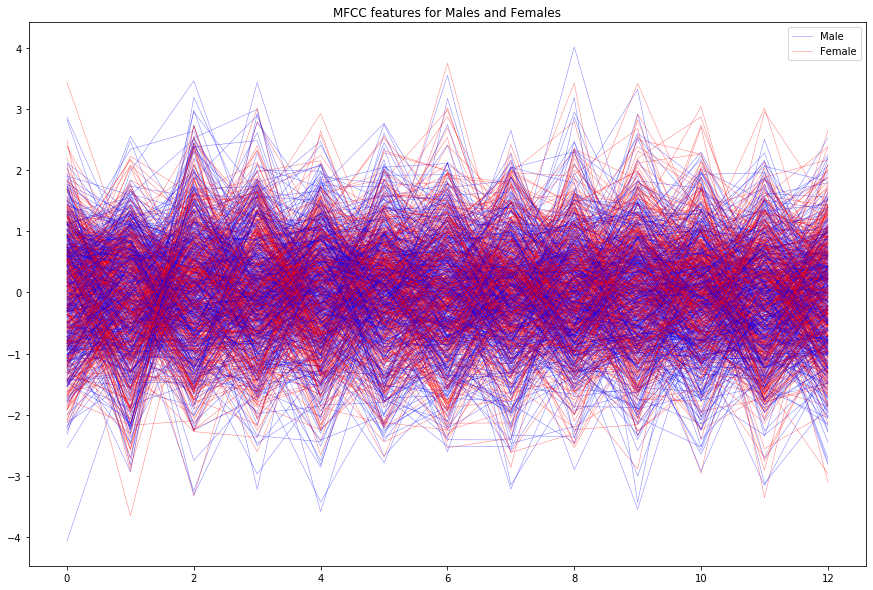
There seem to be slight differences in the features extracted, but the rest of the analysis will tell us more about the separability of these distributions.
Model Evaluation
It is now time to evaluate the accuracy of the model on the test features that we kept untouched for the moment. The idea is simply that for a given recording, we estimate the likelihood of each time frame and sum it for the whole recording. Therefore, if the likelihood of a male voice is greater, we return 0 as an answer, and 1 otherwise.
output = []
for f in features_test_male:
log_likelihood_male = np.array(gmm_male.score([f])).sum()
log_likelihood_female = np.array(gmm_female.score([f])).sum()
if log_likelihood_male > log_likelihood_female:
output.append(0)
else:
output.append(1)
The accuracy for the male test set can be computed as:
accuracy_male = (1 - sum(output)/len(output))
accuracy_male
0.63148
Similarly, the accuracy for the females reaches 0.63808.
Overall, the accuracy is not that high for such a task, and we might need to improve the approach in the next article.
Save models
We now suppose that our model is ready to move to production and we re-train it on the whole dataset and save the models:
def get_features(source):
files = [os.path.join(source,f) for f in os.listdir(source) if f.endswith('.wav')]
features = []
for f in files:
sr,audio = read(f)
vector = get_MFCC(sr,audio)
if len(features) == 0:
features = vector
else:
features = np.vstack((features, vector))
return features
source_male = "test_data/AudioSet/male_clips"
features_male = get_features(source_male)
gmm_male = GMM(n_components = 8, max_iter=200, covariance_type='diag', n_init = 3)
gmm_male.fit(features_male)
source_female = "test_data/AudioSet/female_clips"
features_female = get_features(source_female)
gmm_female = GMM(n_components = 8, max_iter=200, covariance_type='diag', n_init = 3)
gmm_female.fit(features_female)
# Save models
pickle.dump(gmm_male, open("male.gmm", "wb" ))
pickle.dump(gmm_female, open("female.gmm", "wb" ))
Live Prediction
The next step, of course, is to build a live predictor that records 3-5 seconds of an audio sample and classifies it. We use sounddevice for this task, and particularly the rec option.
def record_and_predict(sr=16000, channels=1, duration=3, filename='pred_record.wav'):
recording = sd.rec(int(duration * sr), samplerate=sr, channels=channels).reshape(-1)
sd.wait()
features = get_MFCC(sr,recording)
scores = None
log_likelihood_male = np.array(gmm_male.score(features)).sum()
log_likelihood_female = np.array(gmm_female.score(features)).sum()
if log_likelihood_male >= log_likelihood_female:
return("Male")
else:
return("Female")
To test it in your notebook, simply run :
record_and_predict()
Leave a comment and tell me how good it works! :)
Here’s what I noticed while using it. The accuracy on the test remains to improve (63%). When a user plays with his or her voice and tries to imitate the other gender, the GMM gets fooled and predicts the wrong gender. This is also due to the training data that it has seen so far which were extracted from AudioSet and Youtube.
Web application
Okay, playing with a notebook is quite easy. But we now need to build a dedicated application for this service. Hopefully, this became really easy with Streamlit, a light framework to build interactive applications.
I won’t dive too much in how Streamlit works (this deserves a dedicated article, coming soon :) ), but here’s the code of the application that you should place in app.py:
import streamlit as st
# Data manipulation
import numpy as np
import matplotlib.pyplot as plt
# Feature extraction
import scipy
import librosa
import python_speech_features as mfcc
import os
from scipy.io.wavfile import read
# Model training
from sklearn.mixture import GaussianMixture as GMM
from sklearn import preprocessing
import pickle
# Live recording
import sounddevice as sd
import soundfile as sf
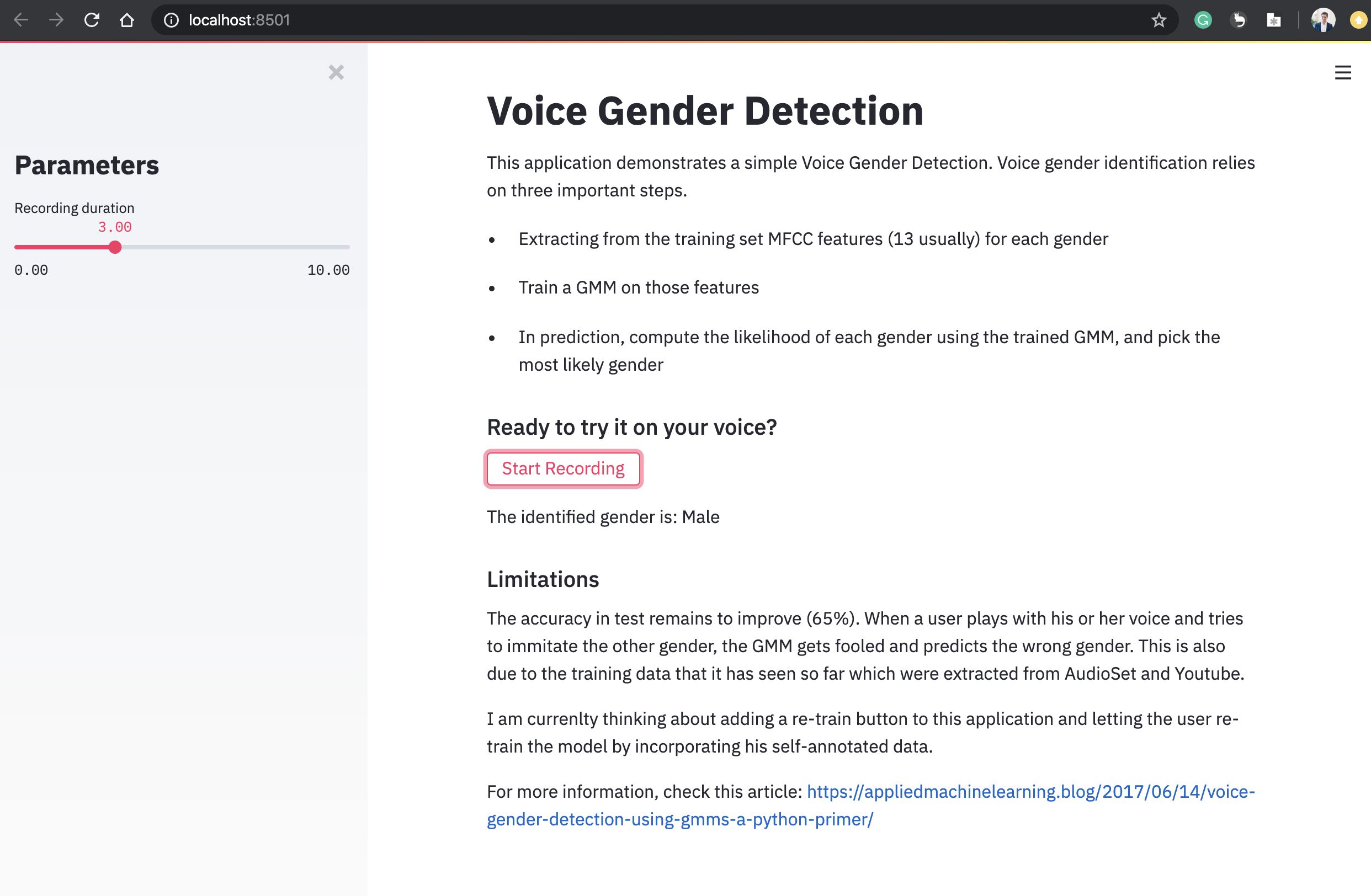
st.title("Voice Gender Detection")
st.write("This application demonstrates a simple Voice Gender Detection. Voice gender identification relies on three important steps.")
st.write("- Extracting from the training set MFCC features (13 usually) for each gender")
st.write("- Train a GMM on those features")
st.write("- In prediction, compute the likelihood of each gender using the trained GMM, and pick the most likely gender")
st.subheader("Ready to try it on your voice?")
st.sidebar.title("Parameters")
duration = st.sidebar.slider("Recording duration", 0.0, 10.0, 3.0)
def get_MFCC(sr,audio):
"""
Extracts the MFCC audio features from a file
"""
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, appendEnergy = False)
features = preprocessing.scale(features)
return features
def record_and_predict(gmm_male, gmm_female, sr=16000, channels=1, duration=3, filename='pred_record.wav'):
"""
Records live voice and returns the identified gender
"""
recording = sd.rec(int(duration * sr), samplerate=sr, channels=channels).reshape(-1)
sd.wait()
features = get_MFCC(sr,recording)
scores = None
log_likelihood_male = np.array(gmm_male.score(features)).sum()
log_likelihood_female = np.array(gmm_female.score(features)).sum()
if log_likelihood_male >= log_likelihood_female:
return("Male")
else:
return("Female")
gmm_male = pickle.load(open('male.gmm','rb'))
gmm_female = pickle.load(open('female.gmm','rb'))
if st.button("Start Recording"):
with st.spinner("Recording..."):
gender = record_and_predict(gmm_male, gmm_female, duration=duration)
st.write("The identified gender is: " + gender)
To launch the app, you must run the command line streamlit run app.py:
Conclusion : I hope that you enjoyed this article and found the approach useful. It has some severe limitations in terms of accuracy and how the user can trick