
After the quick introduction to Kaldi, we’ll move on to an example. I’m mostly reading about and working on speaker verficiation, rather than ASR so far, and I’ll run a x-vector speaker verifciation example.
Speaker Verification Pipeline
Go to the voxceleb folder, read the README, and go to v2. v1 uses GMM-UBM, i-vector and PLDA method. v2 uses DNN speaker embeddings (x-vector), which is currently SOTA, reason why we’ll run it.
What’s in it
The v2 folder contains several folders and files:
README.txt cmd.sh conf local path.sh run.sh sid steps utils
Here is the organisation of a typical Kaldi egs directory, as well illustrated in this Kaldi tutorial.
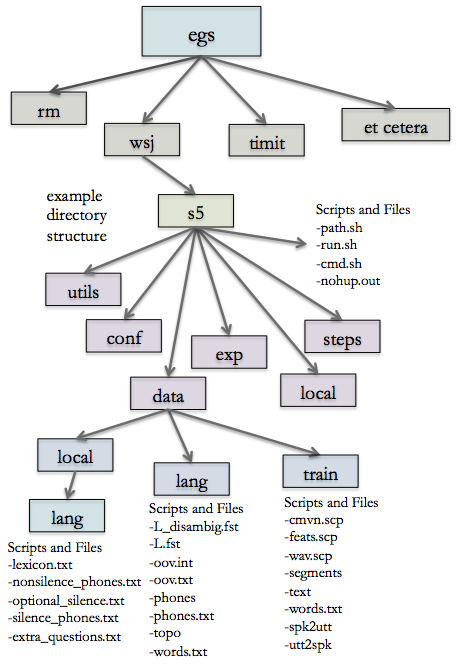
These folders contain:
- scripts ready to launch, such as
run.shthat launches the whole example andpath.shwhich makes sure that there is a proper configuration file cmd.sh, a script to specify the type of computation you’re choosingconfwhich is a folder that contains configuration settings for MFCC feature extraction and energy-based voice activity detection (VAD), e.g setting the threshold under which you don’t detect a voicelocalwhich contains code to setup the dataset in the correct format and shape the features for the x-vector pipelinesidis really important and contains code to compute the VAD, extract the i-vector, the x-vector, training the UBM…stepscontains lower level scripts such as feature extraction, functions to re-format the training data and other utilities
The easy way out is to launch run.sh. This is the high-level script that runs everything mentioned. Rather than running it, we’ll break it down into several steps.
The data
The example does not come with data, you need to place it in the repository. TODO
We are now going to break down the run.sh script. This script was written by Daniel Garcia-Romero, Daniel Povey, David Snyder and Ewald Enzinger (Johns Hopkins University). I am either adding comments above the code, or in-between the lines.
Set the paths
The first step is to set the correct path to the training files. The Musan data are used for data augmentation in the X-vector generation.
. ./cmd.sh
. ./path.sh
set -e
mfccdir=`pwd`/mfcc
vaddir=`pwd`/mfcc
# The trials file is downloaded by local/make_voxceleb1_v2.pl.
voxceleb1_trials=data/voxceleb1_test/trials
voxceleb1_root=/export/corpora/VoxCeleb1
voxceleb2_root=/export/corpora/VoxCeleb2
nnet_dir=exp/xvector_nnet_1a
musan_root=/export/corpora/JHU/musan
Build the datasets
We must now format the training and testing data:
stage=0
# Control if it is the first stage
if [ $stage -le 0 ]; then
# Apply the formating to the train and test data
local/make_voxceleb2.pl $voxceleb2_root dev data/voxceleb2_train
local/make_voxceleb2.pl $voxceleb2_root test data/voxceleb2_test
# The evaluation set becomes Voxceleb1 test data
local/make_voxceleb1_v2.pl $voxceleb1_root dev data/voxceleb1_train
local/make_voxceleb1_v2.pl $voxceleb1_root test data/voxceleb1_test
# We'll train on all of VoxCeleb2, plus the training portion of VoxCeleb1.
# This should give 7,323 speakers and 1,276,888 utterances.
# We combine the datasets
utils/combine_data.sh data/train data/voxceleb2_train data/voxceleb2_test data/voxceleb1_train
fi
Build the features
We now have a training set ready with 7323 speakers and 1.276 million utterances. What we should do is extract the features for the whole training set. The process is in 2 steps. We extract features for the train and test set, and compute the voice activity detection decision.
if [ $stage -le 1 ]; then
# Make MFCCs and compute the energy-based VAD for each dataset
for name in train voxceleb1_test; do
# Compute the MFCC
steps/make_mfcc.sh --write-utt2num-frames true --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \
data/${name} exp/make_mfcc $mfccdir
utils/fix_data_dir.sh data/${name}
# Compute the VAD
sid/compute_vad_decision.sh --nj 40 --cmd "$train_cmd" \
data/${name} exp/make_vad $vaddir
utils/fix_data_dir.sh data/${name}
done
fi
Data augmentation
X-vector is based on a robust embedding, and the major guarantee for the robustness is the data augmentation process. We can augment the initial dataset using several techniques:
- add reverberation to the speech
- add background music
- add background noise
- add babble noise
Note, there are plenty of ways to augment data. One could also speed up the sammple, combine all augmentations on a single utternace…
if [ $stage -le 2 ]; then
frame_shift=0.01
awk -v frame_shift=$frame_shift '{print $1, $2*frame_shift;}' data/train/utt2num_frames > data/train/reco2dur
# Download the package that includes the real RIRs, simulated RIRs, isotropic noises and point-source noises
if [ ! -d "RIRS_NOISES" ]; then
wget --no-check-certificate http://www.openslr.org/resources/28/rirs_noises.zip
unzip rirs_noises.zip
fi
# Make a version with reverberated speech
rvb_opts=()
rvb_opts+=(--rir-set-parameters "0.5, RIRS_NOISES/simulated_rirs/smallroom/rir_list")
rvb_opts+=(--rir-set-parameters "0.5, RIRS_NOISES/simulated_rirs/mediumroom/rir_list")
# Make a reverberated version of the VoxCeleb2 list. No additive noise.
steps/data/reverberate_data_dir.py \
"${rvb_opts[@]}" \
--speech-rvb-probability 1 \
--pointsource-noise-addition-probability 0 \
--isotropic-noise-addition-probability 0 \
--num-replications 1 \
--source-sampling-rate 16000 \
data/train data/train_reverb
cp data/train/vad.scp data/train_reverb/
utils/copy_data_dir.sh --utt-suffix "-reverb" data/train_reverb data/train_reverb.new
rm -rf data/train_reverb
mv data/train_reverb.new data/train_reverb
# Prepare the MUSAN corpus, which consists of music, speech, and noise
# suitable for augmentation.
steps/data/make_musan.sh --sampling-rate 16000 $musan_root data
# Get the duration of the MUSAN recordings. This will be used by the
# script augment_data_dir.py.
for name in speech noise music; do
utils/data/get_utt2dur.sh data/musan_${name}
mv data/musan_${name}/utt2dur data/musan_${name}/reco2dur
done
# Augment with musan_noise
steps/data/augment_data_dir.py --utt-suffix "noise" --fg-interval 1 --fg-snrs "15:10:5:0" --fg-noise-dir "data/musan_noise" data/train data/train_noise
# Augment with musan_music
steps/data/augment_data_dir.py --utt-suffix "music" --bg-snrs "15:10:8:5" --num-bg-noises "1" --bg-noise-dir "data/musan_music" data/train data/train_music
# Augment with musan_speech
steps/data/augment_data_dir.py --utt-suffix "babble" --bg-snrs "20:17:15:13" --num-bg-noises "3:4:5:6:7" --bg-noise-dir "data/musan_speech" data/train data/train_babble
# Combine reverb, noise, music, and babble into one directory.
utils/combine_data.sh data/train_aug data/train_reverb data/train_noise data/train_music data/train_babble
fi
Alright, this long script was useful to augment the dataset. We now must compute the MFCC features on the augmented dataset. This will approximately double the training set size. Note that this process is really different from what data augmentation in Computer Vision would look like. Indeed, in CV, we usually way more than double the number of training data, and apply the augmentation on-the-fly.
if [ $stage -le 3 ]; then
# Take a random subset of the augmentations
utils/subset_data_dir.sh data/train_aug 1000000 data/train_aug_1m
utils/fix_data_dir.sh data/train_aug_1m
# Make MFCCs for the augmented data. Note that we do not compute a new
# vad.scp file here. Instead, we use the vad.scp from the clean version of
# the list.
steps/make_mfcc.sh --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \
data/train_aug_1m exp/make_mfcc $mfccdir
# Combine the clean and augmented VoxCeleb2 list. This is now roughly
# double the size of the original clean list.
utils/combine_data.sh data/train_combined data/train_aug_1m data/train
fi
Normalization
We then apply a cepstral mean and variance normalization (CMVN) on the features, as it is required as an input for the x-vector.
# Now we prepare the features to generate examples for xvector training.
if [ $stage -le 4 ]; then
# This script applies CMVN and removes nonspeech frames. Note that this is somewhat
# wasteful, as it roughly doubles the amount of training data on disk. After
# creating training examples, this can be removed.
local/nnet3/xvector/prepare_feats_for_egs.sh --nj 40 --cmd "$train_cmd" \
data/train_combined data/train_combined_no_sil exp/train_combined_no_sil
utils/fix_data_dir.sh data/train_combined_no_sil
fi
Filter training data
Among training data, you’ll encounter some that are:
- too short once silence has been removed (under 5s.)
- don’t have enough utterance per speaker (under 8)
We need to remove those training data.
if [ $stage -le 5 ]; then
# Now, we need to remove features that are too short after removing silence
# frames. We want atleast 5s (500 frames) per utterance.
min_len=400
mv data/train_combined_no_sil/utt2num_frames data/train_combined_no_sil/utt2num_frames.bak
awk -v min_len=${min_len} '$2 > min_len {print $1, $2}' data/train_combined_no_sil/utt2num_frames.bak > data/train_combined_no_sil/utt2num_frames
utils/filter_scp.pl data/train_combined_no_sil/utt2num_frames data/train_combined_no_sil/utt2spk > data/train_combined_no_sil/utt2spk.new
mv data/train_combined_no_sil/utt2spk.new data/train_combined_no_sil/utt2spk
utils/fix_data_dir.sh data/train_combined_no_sil
# We also want several utterances per speaker. Now we'll throw out speakers
# with fewer than 8 utterances.
min_num_utts=8
awk '{print $1, NF-1}' data/train_combined_no_sil/spk2utt > data/train_combined_no_sil/spk2num
awk -v min_num_utts=${min_num_utts} '$2 >= min_num_utts {print $1, $2}' data/train_combined_no_sil/spk2num | utils/filter_scp.pl - data/train_combined_no_sil/spk2utt > data/train_combined_no_sil/spk2utt.new
mv data/train_combined_no_sil/spk2utt.new data/train_combined_no_sil/spk2utt
utils/spk2utt_to_utt2spk.pl data/train_combined_no_sil/spk2utt > data/train_combined_no_sil/utt2spk
utils/filter_scp.pl data/train_combined_no_sil/utt2spk data/train_combined_no_sil/utt2num_frames > data/train_combined_no_sil/utt2num_frames.new
mv data/train_combined_no_sil/utt2num_frames.new data/train_combined_no_sil/utt2num_frames
# Now we're ready to create training examples.
utils/fix_data_dir.sh data/train_combined_no_sil
fi
Training the DNN
Steps 6 to 8 are grouped in the training of the DNN. The aim of the training is to learn an embedding.
# Stages 6 through 8 are handled in run_xvector.sh
local/nnet3/xvector/run_xvector.sh --stage $stage --train-stage -1 \
--data data/train_combined_no_sil --nnet-dir $nnet_dir \
--egs-dir $nnet_dir/egs
Extract the x-vector
By extracting the last hidden layer, before the prediction, we have an embedding called an x-vector, representing the information extacted from the voice of the speaker. We run the script extract_xvectors.sh to extract it in the training and test set.
if [ $stage -le 9 ]; then
# Extract x-vectors for centering, LDA, and PLDA training.
sid/nnet3/xvector/extract_xvectors.sh --cmd "$train_cmd --mem 4G" --nj 80 \
$nnet_dir data/train \
$nnet_dir/xvectors_train
# Extract x-vectors used in the evaluation.
sid/nnet3/xvector/extract_xvectors.sh --cmd "$train_cmd --mem 4G" --nj 40 \
$nnet_dir data/voxceleb1_test \
$nnet_dir/xvectors_voxceleb1_test
fi
Mean vector, LDA and PLDA
We then compute the mean vector to center the evaluation x-vectors. We then reduce the dimension of the x-vectors to 200 using LDA. Finally, the PLDA acts as a classifier. We train it here.
if [ $stage -le 10 ]; then
# Compute the mean vector for centering the evaluation xvectors.
$train_cmd $nnet_dir/xvectors_train/log/compute_mean.log \
ivector-mean scp:$nnet_dir/xvectors_train/xvector.scp \
$nnet_dir/xvectors_train/mean.vec || exit 1;
# This script uses LDA to decrease the dimensionality prior to PLDA.
lda_dim=200
$train_cmd $nnet_dir/xvectors_train/log/lda.log \
ivector-compute-lda --total-covariance-factor=0.0 --dim=$lda_dim \
"ark:ivector-subtract-global-mean scp:$nnet_dir/xvectors_train/xvector.scp ark:- |" \
ark:data/train/utt2spk $nnet_dir/xvectors_train/transform.mat || exit 1;
# Train the PLDA model.
$train_cmd $nnet_dir/xvectors_train/log/plda.log \
ivector-compute-plda ark:data/train/spk2utt \
"ark:ivector-subtract-global-mean scp:$nnet_dir/xvectors_train/xvector.scp ark:- | transform-vec $nnet_dir/xvectors_train/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
$nnet_dir/xvectors_train/plda || exit 1;
fi
Make predictions and assess performance
All models are trained, we can now make predictions on the test set of Voxceleb1. This script will also generate and display performance metrics (Equal Error Rate and min DCF).
if [ $stage -le 11 ]; then
$train_cmd exp/scores/log/voxceleb1_test_scoring.log \
ivector-plda-scoring --normalize-length=true \
"ivector-copy-plda --smoothing=0.0 $nnet_dir/xvectors_train/plda - |" \
"ark:ivector-subtract-global-mean $nnet_dir/xvectors_train/mean.vec scp:$nnet_dir/xvectors_voxceleb1_test/xvector.scp ark:- | transform-vec $nnet_dir/xvectors_train/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"ark:ivector-subtract-global-mean $nnet_dir/xvectors_train/mean.vec scp:$nnet_dir/xvectors_voxceleb1_test/xvector.scp ark:- | transform-vec $nnet_dir/xvectors_train/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"cat '$voxceleb1_trials' | cut -d\ --fields=1,2 |" exp/scores_voxceleb1_test || exit 1;
fi
if [ $stage -le 12 ]; then
eer=`compute-eer <(local/prepare_for_eer.py $voxceleb1_trials exp/scores_voxceleb1_test) 2> /dev/null`
mindcf1=`sid/compute_min_dcf.py --p-target 0.01 exp/scores_voxceleb1_test $voxceleb1_trials 2> /dev/null`
mindcf2=`sid/compute_min_dcf.py --p-target 0.001 exp/scores_voxceleb1_test $voxceleb1_trials 2> /dev/null`
echo "EER: $eer%"
echo "minDCF(p-target=0.01): $mindcf1"
echo "minDCF(p-target=0.001): $mindcf2"
# EER: 3.128%
# minDCF(p-target=0.01): 0.3258
# minDCF(p-target=0.001): 0.5003
fi