
Explore a dataset on Google BigQuery
Storing and querying massive datasets can be time-consuming and expensive without the right hardware and infrastructure. Google BigQuery is an enterprise data warehouse that solves this problem by enabling super-fast SQL queries using the processing power of Google’s infrastructure.
The aim of this lab is to explore public data using Big Query, create queries and upload our own data.
Public Data
From the GCP console, start by clicking on Big Query in the side menu :
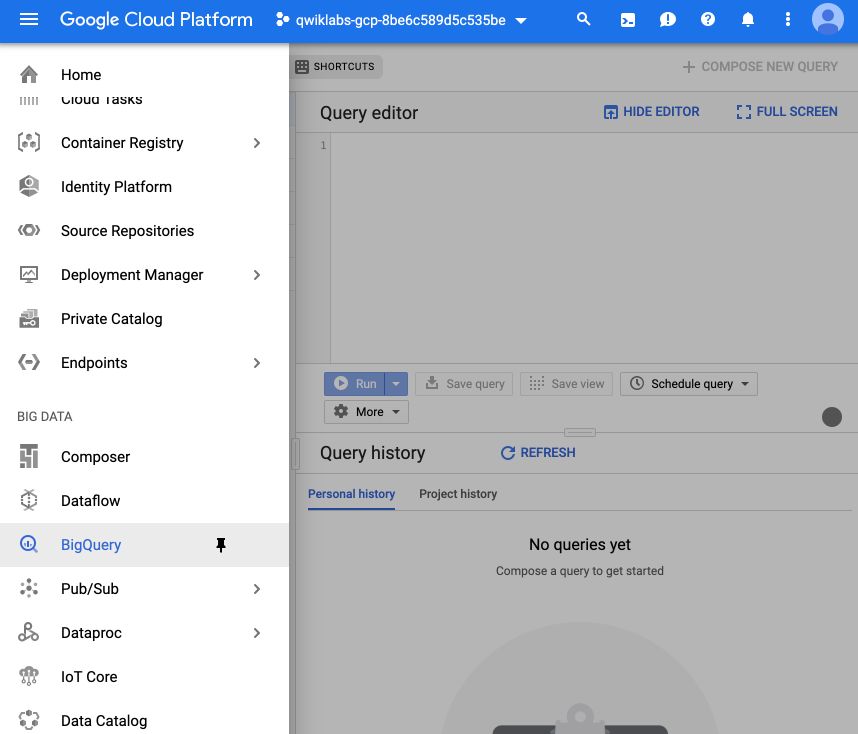
Then, select “Explore public dataset” :
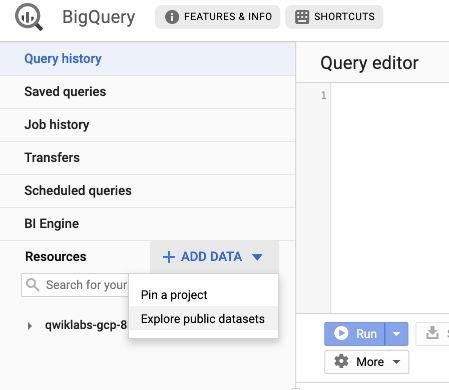
Type “USA Names” in the search bar, and select the following dataset :
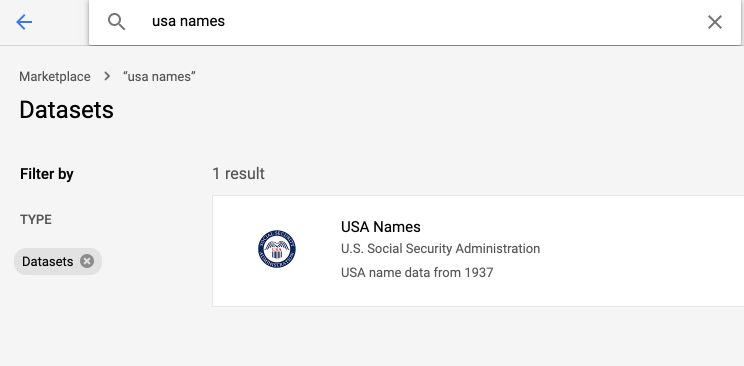
Click on “View Dataset” :
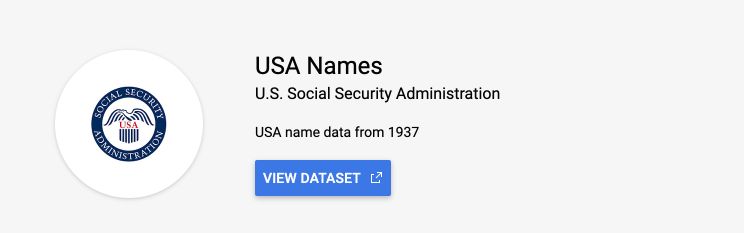
The dataset will now appear in your side menu :
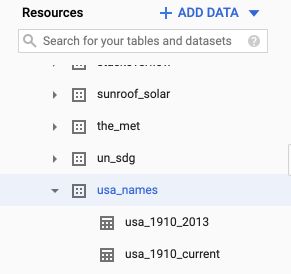
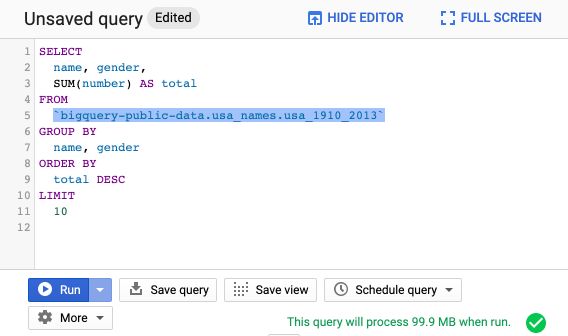
We can use the query editor to write SQL queries in Big Query :
SELECT name, gender,
SUM(number) AS total
FROM `bigquery-public-data.usa_names.usa_1910_2013`
GROUP BY name, gender
ORDER BY total DESC
LIMIT 10
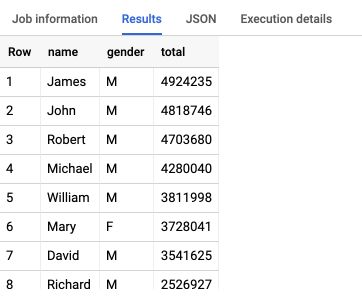
The result table is displayed in the following way :
Your own data
Alright, we can build the same approach using our own datasets. Download the baby names dataset from the following link : http://www.ssa.gov/OACT/babynames/names.zip. Put the files on your desktop (or wherever you want). Open a file and observe the structure.
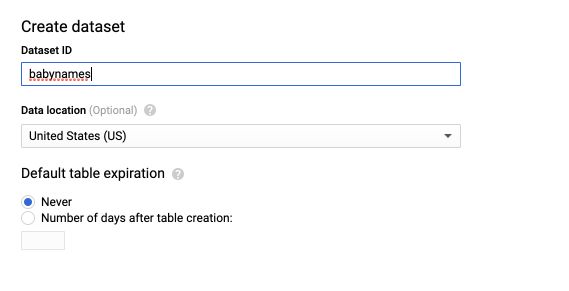
We will now create a dataset in BigQuery. In the resources tab, click on your project’s name. Then, click on “Create Dataset” in the central page.
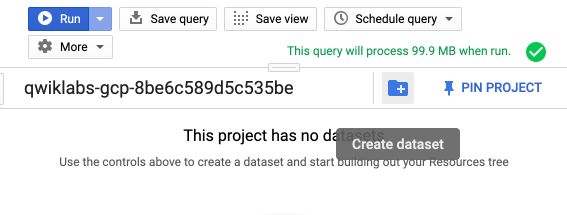
Give your dataset a name, and a region.
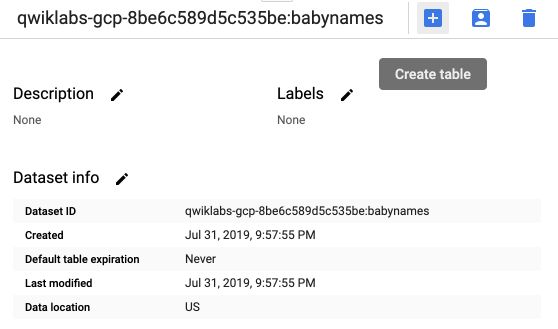
Then, click on “Create Table” :
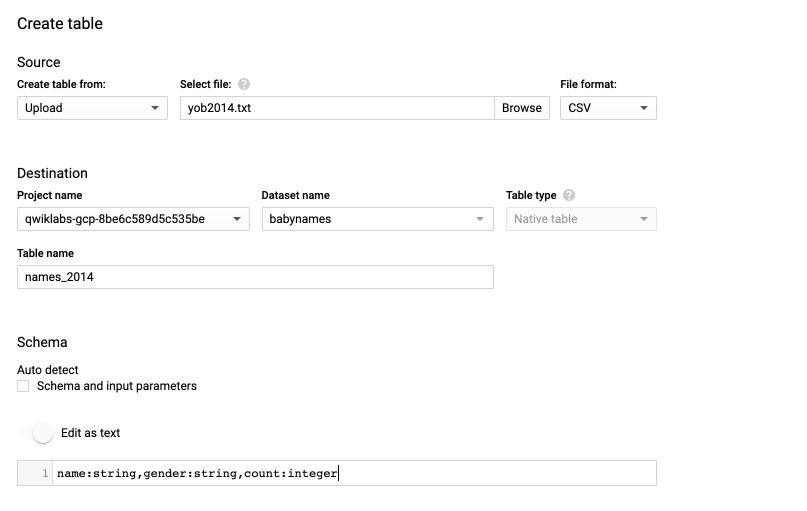
Give your table a name, select the file (for example the year 2014) and the file format (CSV).
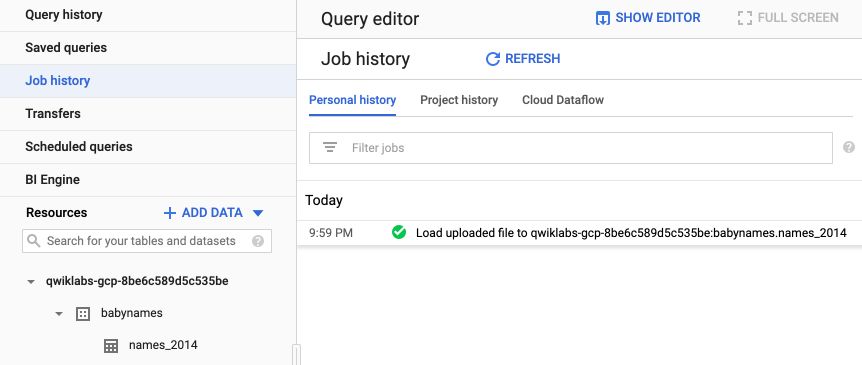
The upload should appear in your Job History on the side menu.
Once ready, click on the table’s name from the resources menu, and preview the columns.
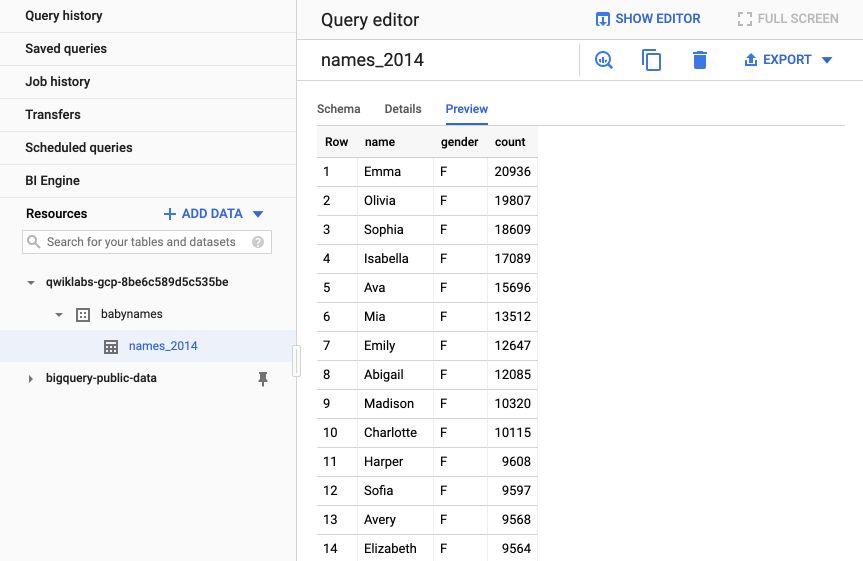
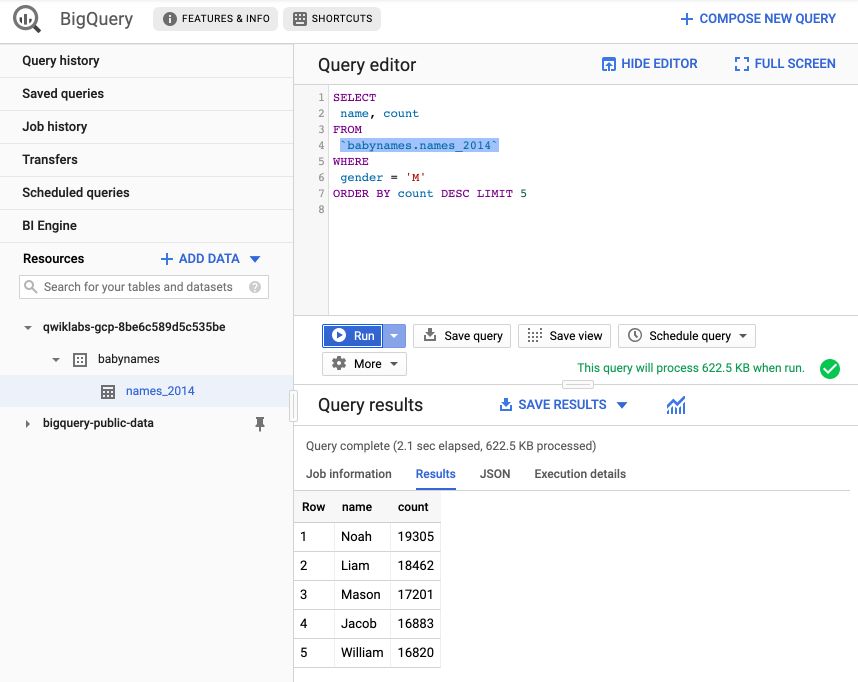
We can now create a query to retrieve the 5 most famous males names :
SELECT name, count
FROM `babynames.names_2014`
WHERE gender = 'M'
ORDER BY count DESC LIMIT 5
If you click on run, you should see the following result!
 s
s