
Build a Language Recognition app
In this project, we will build a language recognition app using Markov Chains and likelihood decoding algorithm. If you have not seen my previous articles on this topic, I invite you to check them :)
Language Recognition
We aim to build a small web app able to recognize the language of an input text. We will :
- Build a transition probabilities matrix from Wikipedia’s articles
- Find the most “likely” language by multiplying the transition probabilities for a given sequence
- Identify the highest result to return the language
Build the transition probability matrix
Start by importing the following packages :
import numpy as np
import matplotlib.pyplot as plt
# Parsing
import requests
from bs4 import BeautifulSoup
import re
Then, we’ll pick one of the longest articles from Wikipedia: South African Labor Law, and learn transition probabilities from it. Transition probabilities are simply the probabilities, from a given letter (say s) to move to another letter (say o).
url = 'https://en.wikipedia.org/wiki/South_African_labour_law'
res = requests.get(url)
html_page = res.content
We can then parse the content :
soup = BeautifulSoup(html_page, 'html.parser')
text = soup.find_all(text=True)
We will use the following code to clean the content as much as possible :
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'\n'
]
for t in text:
if t.parent.name not in blacklist:
output += '{} '.format(t)
The raw text contains many HTML tags, and elements specific to Wikipedia. We need to clean the text a bit :
def preprocess_text(text) :
text = text.replace('\n', '').replace('[ edit ]', '').replace("\'", "'")
text = ''.join(c.lower() for c in text if not c.isdigit())
text = re.sub('[^A-Za-z]+', ' ', text)
return text
And apply the function to the clean text :
text = preprocess_text(output)
Then, define two dictionnaries we’ll need later on :
dic={1 : ' ',
2 : 'a',
3 : 'b',
4: 'c',
5 : 'd',
6 : 'e',
7: 'f',
8 : 'g',
9 : 'h',
10: 'i',
11: 'j',
12 : 'k',
13 : 'l',
14: 'm',
15 : 'n',
16 : 'o',
17: 'p',
18 : 'q',
19 : 'r' ,
20: 's',
21 : 't',
22 : 'u',
23: 'v',
24 : 'w',
25 : 'x' ,
26: 'y',
27 : 'z'
}
dic_2 = {' ' : 0,
'a' : 1,
'b' : 2,
'c' : 3,
'd' : 4,
'e' : 5,
'f' : 6,
'g' : 7,
'h' : 8,
'i' : 9,
'j' : 10,
'k' : 11,
'l' : 12,
'm' : 13,
'n' : 14,
'o' : 15,
'p' : 16,
'q' : 17,
'r' : 18,
's' : 19,
't' : 20,
'u' : 21,
'v' : 22,
'w' : 23,
'x' : 24,
'y' : 25,
'z' : 26
}
Alright, we now need to go through the whole text, and compute the number of time we went from one letter to another. I have kept the implementation really simple for explainability purposes. There are several ways to improve this part :
a = np.zeros(27)
b = np.zeros(27)
c = np.zeros(27)
d = np.zeros(27)
e = np.zeros(27)
f = np.zeros(27)
g = np.zeros(27)
h = np.zeros(27)
i = np.zeros(27)
j = np.zeros(27)
k = np.zeros(27)
l = np.zeros(27)
m = np.zeros(27)
n = np.zeros(27)
o = np.zeros(27)
p = np.zeros(27)
q = np.zeros(27)
r = np.zeros(27)
s = np.zeros(27)
t = np.zeros(27)
u = np.zeros(27)
v = np.zeros(27)
w = np.zeros(27)
x = np.zeros(27)
y = np.zeros(27)
z = np.zeros(27)
space = np.zeros(27)
prev = ' '
for char in text:
if prev == ' ':
space[dic_2[char]] += 1
elif prev == 'a' :
a[dic_2[char]] += 1
elif prev == 'b':
b[dic_2[char]] += 1
elif prev == 'c':
c[dic_2[char]] += 1
elif prev == 'd':
d[dic_2[char]] += 1
elif prev == 'e':
e[dic_2[char]] += 1
elif prev == 'f':
f[dic_2[char]] += 1
elif prev == 'g':
g[dic_2[char]] += 1
elif prev == 'h':
h[dic_2[char]] += 1
elif prev == 'i':
i[dic_2[char]] += 1
elif prev == 'j':
j[dic_2[char]] += 1
elif prev == 'k':
k[dic_2[char]] += 1
elif prev == 'l':
l[dic_2[char]] += 1
elif prev == 'm':
m[dic_2[char]] += 1
elif prev == 'n':
n[dic_2[char]] += 1
elif prev == 'o':
o[dic_2[char]] += 1
elif prev == 'p':
p[dic_2[char]] += 1
elif prev == 'q':
q[dic_2[char]] += 1
elif prev == 'r':
r[dic_2[char]] += 1
elif prev == 's':
s[dic_2[char]] += 1
elif prev == 't':
t[dic_2[char]] += 1
elif prev == 'u':
u[dic_2[char]] += 1
elif prev == 'v':
v[dic_2[char]] += 1
elif prev == 'w':
w[dic_2[char]] += 1
elif prev == 'x':
x[dic_2[char]] += 1
elif prev == 'y':
y[dic_2[char]] += 1
elif prev == 'z':
z[dic_2[char]] += 1
prev = char
At that point, we have raw number which we need to transform into probabilities :
a = a / np.sum(a)
b = b / np.sum(b)
c = c / np.sum(c)
d = d / np.sum(d)
e = e / np.sum(e)
f = f / np.sum(f)
g = g / np.sum(g)
h = h / np.sum(h)
i = i / np.sum(i)
j = j / np.sum(j)
k = k / np.sum(k)
l = l / np.sum(l)
m = m / np.sum(m)
n = n / np.sum(n)
o = o / np.sum(o)
p = p / np.sum(p)
q = q / np.sum(q)
r = r / np.sum(r)
s = s / np.sum(s)
t = t / np.sum(t)
u = u / np.sum(u)
v = v / np.sum(v)
w = w / np.sum(w)
x = x / np.sum(x)
y = y / np.sum(y)
z = z / np.sum(z)
space = space / np.sum(space)
To retrieve the final matrix, we can declare :
trans_eng = np.matrix([space, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z])
I have summarized this into a function. Here is the whole code needed :
global dic
global dic_2
dic={1 : ' ',
2 : 'a',
3 : 'b',
4: 'c',
5 : 'd',
6 : 'e',
7: 'f',
8 : 'g',
9 : 'h',
10: 'i',
11: 'j',
12 : 'k',
13 : 'l',
14: 'm',
15 : 'n',
16 : 'o',
17: 'p',
18 : 'q',
19 : 'r' ,
20: 's',
21 : 't',
22 : 'u',
23: 'v',
24 : 'w',
25 : 'x' ,
26: 'y',
27 : 'z'
}
dic_2 = {' ' : 0,
'a' : 1,
'b' : 2,
'c' : 3,
'd' : 4,
'e' : 5,
'f' : 6,
'g' : 7,
'h' : 8,
'i' : 9,
'j' : 10,
'k' : 11,
'l' : 12,
'm' : 13,
'n' : 14,
'o' : 15,
'p' : 16,
'q' : 17,
'r' : 18,
's' : 19,
't' : 20,
'u' : 21,
'v' : 22,
'w' : 23,
'x' : 24,
'y' : 25,
'z' : 26
}
def preprocess_text(text) :
text = text.replace('\n', '').replace('[ edit ]', '').replace("\'", "'")
text = ''.join(c.lower() for c in text if not c.isdigit())
text = re.sub('[^A-Za-z]+', ' ', text)
return text
def compute_transition(url_input):
url = url_input
res = requests.get(url)
html_page = res.content
soup = BeautifulSoup(html_page, 'html.parser')
text = soup.find_all(text=True)
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'\n'
]
for t in text:
if t.parent.name not in blacklist:
output += '{} '.format(t)
text = preprocess_text(output)
a = np.zeros(27)
b = np.zeros(27)
c = np.zeros(27)
d = np.zeros(27)
e = np.zeros(27)
f = np.zeros(27)
g = np.zeros(27)
h = np.zeros(27)
i = np.zeros(27)
j = np.zeros(27)
k = np.zeros(27)
l = np.zeros(27)
m = np.zeros(27)
n = np.zeros(27)
o = np.zeros(27)
p = np.zeros(27)
q = np.zeros(27)
r = np.zeros(27)
s = np.zeros(27)
t = np.zeros(27)
u = np.zeros(27)
v = np.zeros(27)
w = np.zeros(27)
x = np.zeros(27)
y = np.zeros(27)
z = np.zeros(27)
space = np.zeros(27)
prev = ' '
for char in text:
if prev == ' ':
space[dic_2[char]] += 1
elif prev == 'a' :
a[dic_2[char]] += 1
elif prev == 'b':
b[dic_2[char]] += 1
elif prev == 'c':
c[dic_2[char]] += 1
elif prev == 'd':
d[dic_2[char]] += 1
elif prev == 'e':
e[dic_2[char]] += 1
elif prev == 'f':
f[dic_2[char]] += 1
elif prev == 'g':
g[dic_2[char]] += 1
elif prev == 'h':
h[dic_2[char]] += 1
elif prev == 'i':
i[dic_2[char]] += 1
elif prev == 'j':
j[dic_2[char]] += 1
elif prev == 'k':
k[dic_2[char]] += 1
elif prev == 'l':
l[dic_2[char]] += 1
elif prev == 'm':
m[dic_2[char]] += 1
elif prev == 'n':
n[dic_2[char]] += 1
elif prev == 'o':
o[dic_2[char]] += 1
elif prev == 'p':
p[dic_2[char]] += 1
elif prev == 'q':
q[dic_2[char]] += 1
elif prev == 'r':
r[dic_2[char]] += 1
elif prev == 's':
s[dic_2[char]] += 1
elif prev == 't':
t[dic_2[char]] += 1
elif prev == 'u':
u[dic_2[char]] += 1
elif prev == 'v':
v[dic_2[char]] += 1
elif prev == 'w':
w[dic_2[char]] += 1
elif prev == 'x':
x[dic_2[char]] += 1
elif prev == 'y':
y[dic_2[char]] += 1
elif prev == 'z':
z[dic_2[char]] += 1
prev = char
a = a / np.sum(a)
b = b / np.sum(b)
c = c / np.sum(c)
d = d / np.sum(d)
e = e / np.sum(e)
f = f / np.sum(f)
g = g / np.sum(g)
h = h / np.sum(h)
i = i / np.sum(i)
j = j / np.sum(j)
k = k / np.sum(k)
l = l / np.sum(l)
m = m / np.sum(m)
n = n / np.sum(n)
o = o / np.sum(o)
p = p / np.sum(p)
q = q / np.sum(q)
r = r / np.sum(r)
s = s / np.sum(s)
t = t / np.sum(t)
u = u / np.sum(u)
v = v / np.sum(v)
w = w / np.sum(w)
x = x / np.sum(x)
y = y / np.sum(y)
z = z / np.sum(z)
space = space / np.sum(space)
return np.matrix([space, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z])
We can then pick long articles in English, French and Italian for example :
trans_eng = compute_transition('https://en.wikipedia.org/wiki/South_African_labour_law')
trans_fr = compute_transition('https://fr.wikipedia.org/wiki/Histoire_du_m%C3%A9tier_de_plombier')
trans_it = compute_transition('https://it.wikipedia.org/wiki/Storia_d%27Italia')
The transition matrices are now computed! Let’s move to the language recognition part.
Identify the language
We will now try to identify the language based on the transition likelihood. All we need to do is, for each language, roll back identify the transition probability from one letter to another, and return the most likely language.
def rec_language(dic, dic_2, bi_eng, bi_fr, bi_it, seq) :
seq = preprocess_text(seq)
key_0 = 0
trans_eng = 1
trans_fra = 1
trans_it = 1
for letter in seq :
# If unknown character missed by pre-processing
try :
key_1 = dic_2[letter]
trans_eng = trans_eng * bi_eng[key_0, key_1]
trans_fra = trans_fra * bi_fr[key_0, key_1]
trans_it = trans_it * bi_it[key_0, key_1]
key_0 = dic_2[letter]
except :
continue
if trans_eng > trans_fra and trans_eng > trans_it :
print("It's English !")
elif trans_fra > trans_eng and trans_fra > trans_it :
print("It's French !")
else :
print("It's Italian !")
We can now try it in some sentences! First, a french sentence :
rec_language(dic, dic_2, trans_eng, trans_fr, trans_it, "Quel beau temps aujourd'hui !")
Returns :
It's French !
Then, in English :
rec_language(dic, dic_2, trans_eng, trans_fr, trans_it, 'What a nice weather today !')
Returns :
It's English !
And in italian :
rec_language(dic, dic_2, trans_eng, trans_fr, trans_it, 'Che bello tempo fa oggi !')
Returns :
It's Italian !
Potential improvements
We fetched the transition probabilities from single articles in Wikipedia. To develop a more robust solution, we should consider a large input corpus.
The text pre-processing is not perfect, and we should add some more features to it.
Finally, we tested only 3 languages, but we could generalize the solution we have developed to other languages.
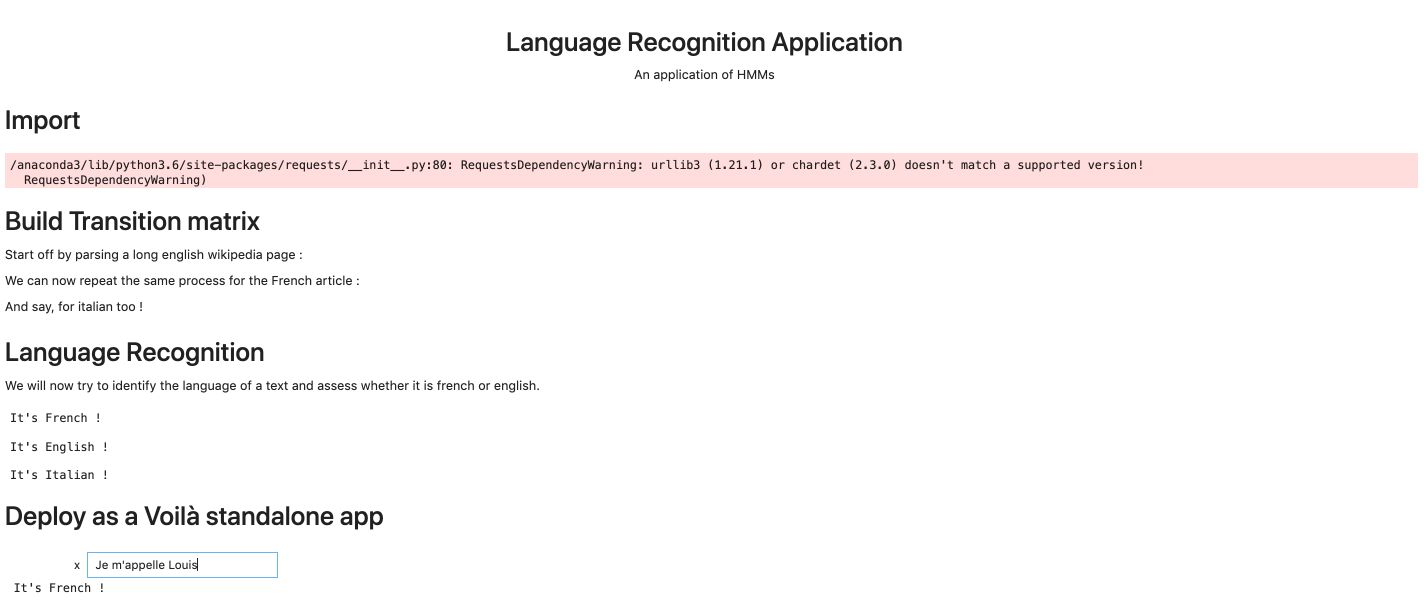
Standalone App with Voilà
You might have heard of Voilà that lets you run your Jupyter Notebooks as standalone apps. Let’s try this out!
Start by installing Voilà :
pip install voila
Then, in the notebook, create an interactive widget :
from ipywidgets import widgets
from ipywidgets import interact, interactive, fixed, interact_manual
def reco_interactive(x):
return rec_language(dic, dic_2, trans_eng, trans_fr, trans_it, x)
And run the interactive cell :
interact(reco_interactive, x='Hi there!');
You should see something like this :

Then, to create an app from it, simply run from your terminal, in the notebook’s folder :
voila notebook.ipynb
You’ll have access to a webpage where the interactive widget works as a standalone app!
Conclusion : Although text embedding and deep learning seem to be everywhere nowadays, simple approaches like likelihood Decoding algorithm and Markov Chains can bring value if we’re looking for a light, fast and explainable solution (think about including this in a smartphone’s software for example). I hope this was useful, and don’t hesitate to comment if you have any question.