
MFCCs have long been the standard hand-crafted features used as inputs for the majority of speech-related tasks. Nowadays, most X-vectors for speaker identification and speaker verification systems still rely on MFCCs, voice activity detection (VAD) and cepstral mean and variance normalization (CMVN). MFCCs are used in speaker recognition, in conjunction with Gaussian mixture models, i-vectors, x-vectors, and more recently ResNet and DenseNet speaker embeddings.
Lately, some end-to-end models that directly embed the raw waveform and perform downstream tasks arised. These approaches, although encouraging, only reached limited performances.
At Interspeech 2020, a paper by Weiwei Lin and Man-Wai Mak caught my attention. The paper claims to learn speaker emebeddings from raw waveforms using a simple DNN architecture, with a similar approach to Wav2Vec.
Let’s dive into the paper :)
Model Architecture
Feature encoding
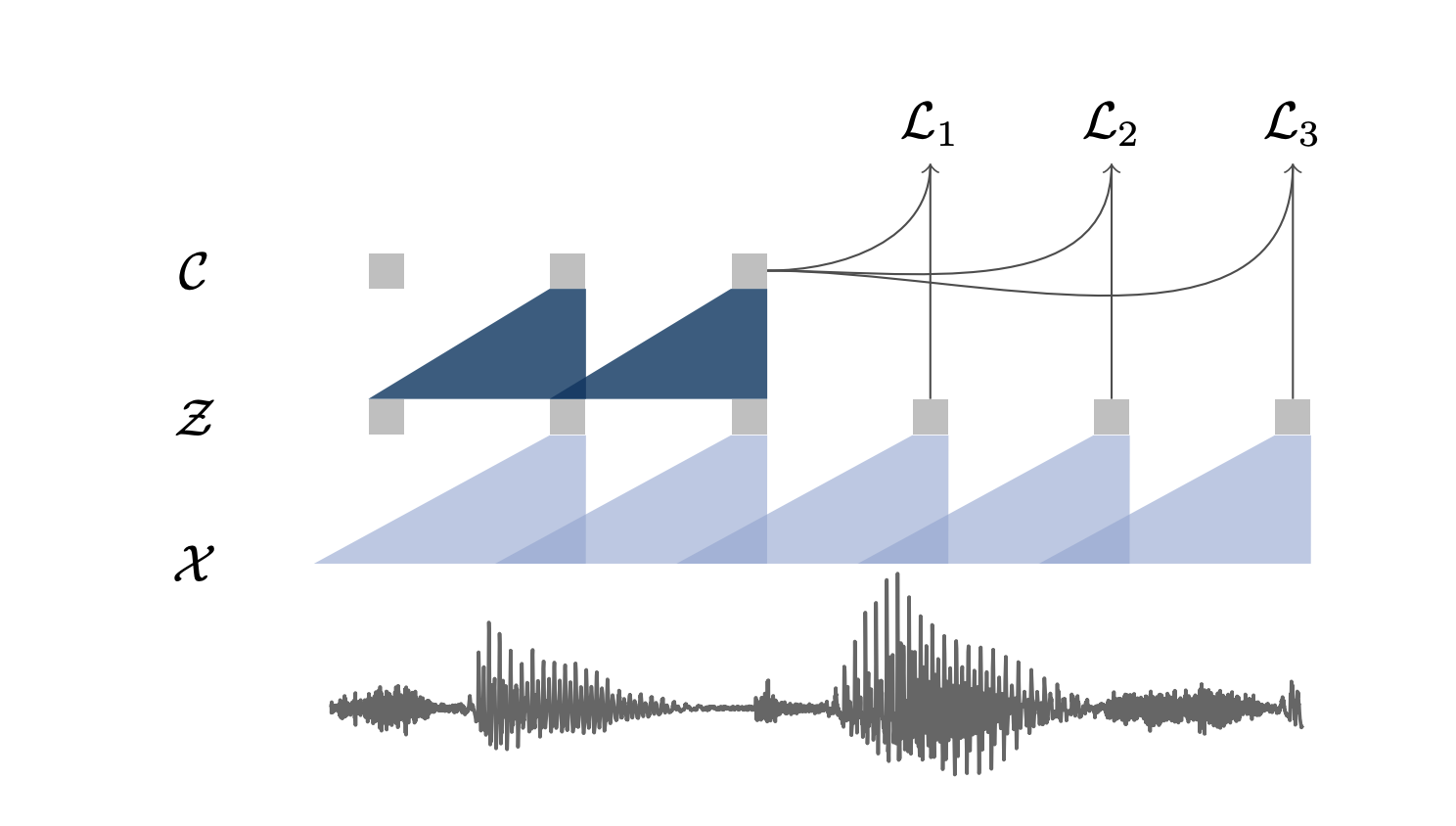
Why don’t we directly input waveforms to an X-vector system? Well, because the frames it processes are 25 to 30 ms long, and the effective receptive field of the X-vector would be too small.
One architecture that has often been used in speech is Convolutional Neural Networks. Using CNNs with large strides and kernel sizes as an encoder network has proven to be efficient in Wav2Vec. Here, the authors use 5 convolutional layers with kernel sizes (10, 8, 4, 4, 4) and strides (5, 4, 2, 2, 2). This encodes 30ms of speech and 10ms frame shift.
Temporal gating
Final word
I hope this wav2vec series summary was useful. Feel free to leave a comment
All references: