
In the world, more than 6’000 languages exist, 3’000 of them currently being endangered. In Europe, 24 official languages are spoken. Google Cloud Speech API covers 60 languages and 50 accents/dialects, and Siri covers 20 languages and 20 accents/dialects.
Many of the low-resourced languages have:
- limited web presence, hence lack resources on text corpora and pronunciation
- lack of linguistic expertise
Speech Recognition of under-resources languages
There are several steps to manage and under-resources language:
- train multilingual acoustic and language models
- transfer knowledge between languages
- construct pronunciation lexica
- deal with language specific characteristics
Multi / cross-lingual acoustic models
We can use NN hidden layers to learn a multilingual representation, shared between languages, and add an output layer for monolingual language specific.
There are several ways to do this:
- use a hat-swap architecture, which is a network with an output layer for each language but shared hidden layers
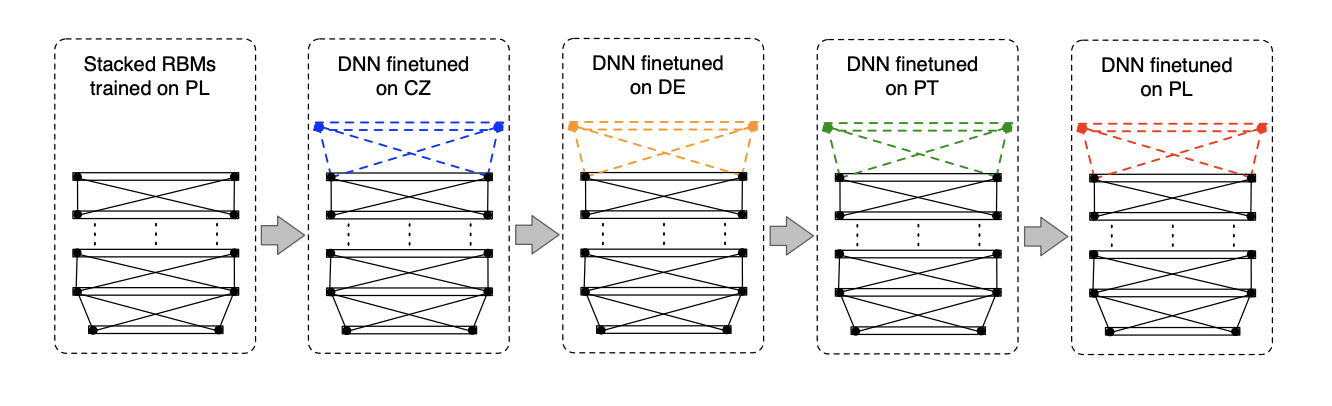
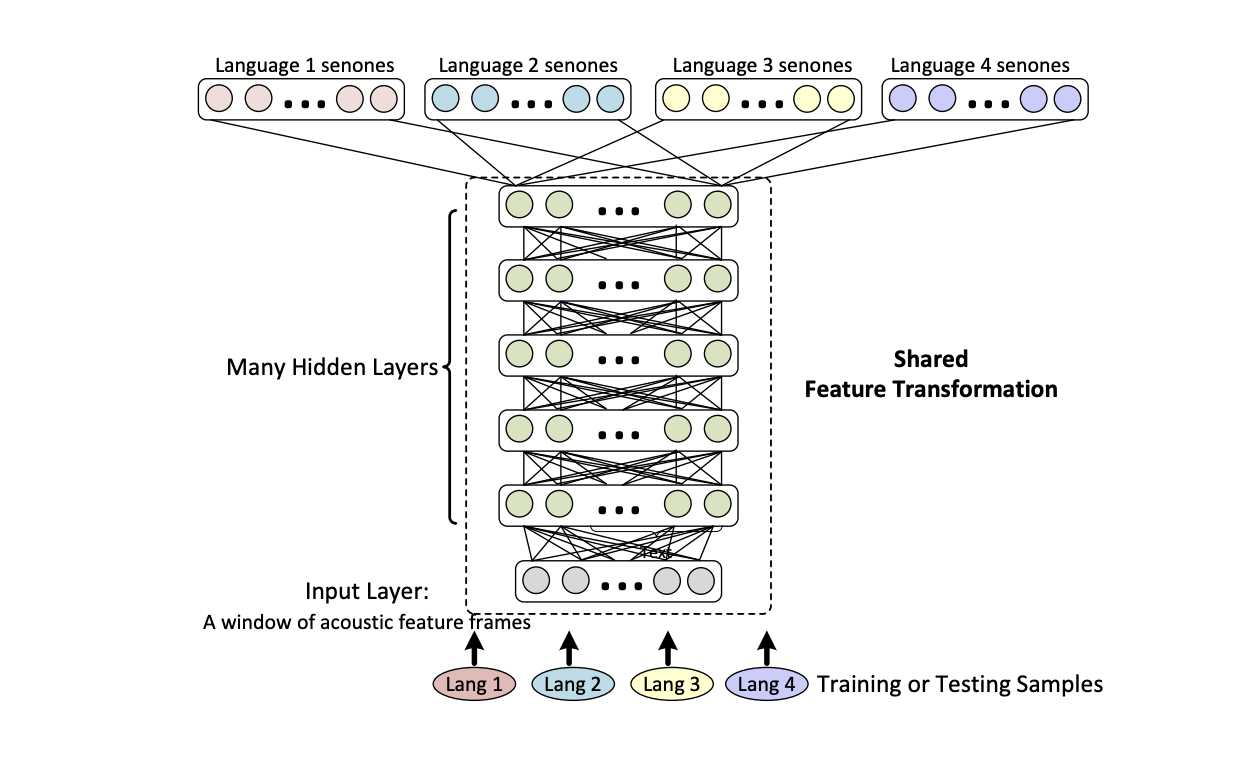
- use a multilingual phone set and build a common hybrid HMM-DNN system with a separate output layer per language, a parallel version of the hat-swap
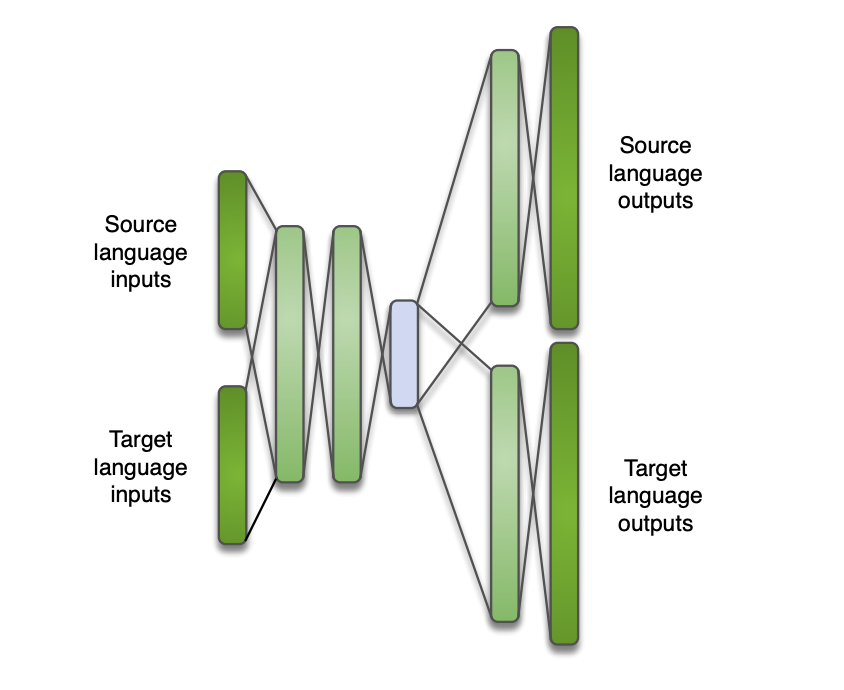
- use a multilingual bottleneck, a bottleneck hidden layer (trained as multilingual) as features of a HMM-GMM or a HMM-DNN system
Graphemes
A way to overcome lacks of phone-based pronunciations is to use graphemes (letters) rather than phones. The only problem is that there is not always a direct link between graphemes and sounds, for example in English.
Morphology
Many languages are harder than English, have larger vocabulary sizes, and:
- are compound (e.g German): words can be decomposed into constituent parts
- are inflected languages (e.g Arabic or Slavic)
- are inflected and compound (e.g Finnish)
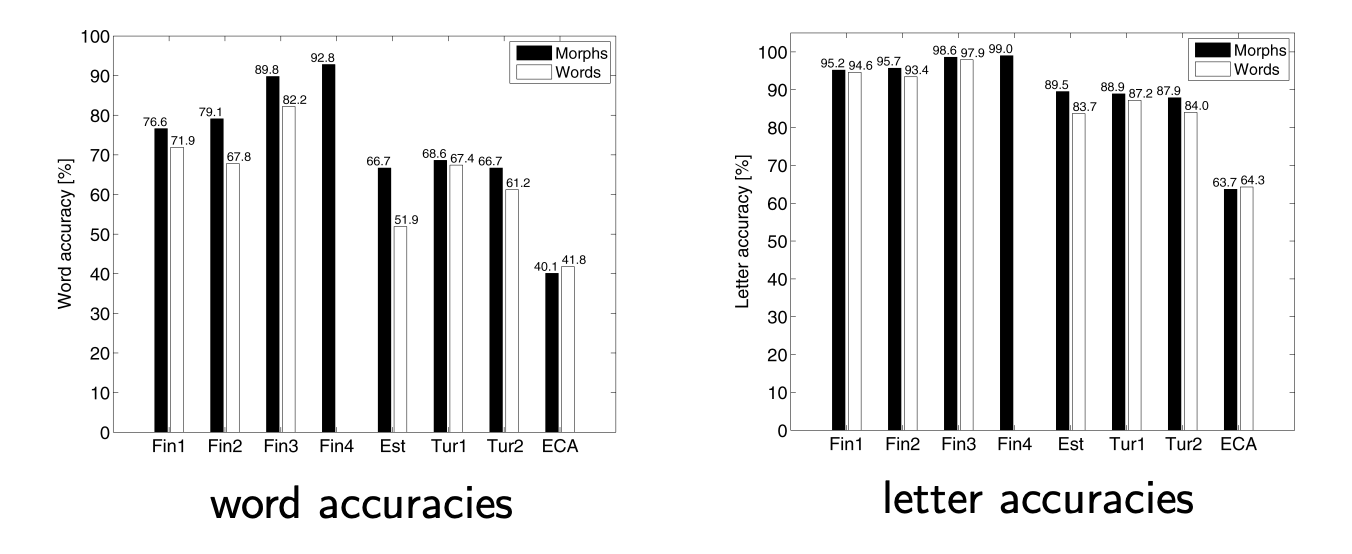
We can therefore model at the morph level in order to reduce the Out-Of-Vocabulary rate (OOV).
Segmenting speech and text into morphs requires a lot of linguistic work. However, some automatic approaches try to cluster words (wuch as Morfessor) based on the frequency of sub-strings of letters in a word list. It may however require larger context.
Conclusion
If you want to improve this article or have a question, feel free to leave a comment below :)
References: