
One of the main challenges, when dealing with text, is to build an efficient preprocessing pipeline.
I. What is preprocessing?
Preprocessing in Natural Language Processing (NLP) is the process by which we try to “standardize” the text we want to analyze.
A challenge that arises pretty quickly when you try to build an efficient preprocessing NLP pipeline is the diversity of the texts you might deal with :
- tweets that would be highly informal
- cover letters from candidates in an HR company
- Slack messages within a team
- Even code sometimes if you try to analyze Github comments for example
The diversity makes the whole thing tricky. Usually, a given pipeline is developed for a certain kind of text. The pipeline should give us a “clean” text version.
Another challenge that arises when dealing with text preprocessing is the language. The English language remains quite simple to preprocess. German or french use for example much more special characters like “é, à, ö, ï”.
You might now wonder what are the main steps of preprocessing?
- A first step is to remove words that are made of special characters (if needed in your case):
@,#, /,!.\'+-= - In English, some words are short versions of actuals words, e.g “I’m” for “I am”. To treat them as separate words, you’ll need to split them.
- We then would like to remove specific syntax linked to our text extraction, e.g “\n” every time there is a new line
- Remove the stop words, which are mainstream words like “the, I, would”…
- Once this step is done, we are ready to tokenize the text, i.e split by word
- To make sure that the words “Shoe” and “shoe” are later understood as the same, lower case the tokens
- Lemmatize the tokens to extract the “root” of each word.
The process can be illustrated in the following way :

Tokenization
Given a sequence of characters, tokenization aims to cut the sentence into pieces, called tokens. Tokenization consists of splitting large chunks of text into sentences, and sentences into a list of single words also called tokens. This step also referred to as segmentation or lexical analysis, is necessary to perform further processing.
Consider a really simple example :
My name is Paul.
There are different ways to tokenize this :
- either we consider all tokens indifferently:
(My, name, is, Paul, .)(Notice that we keep the dot) - either consider that each token must be a word:
(My, name, is, Paul) - or by removing stop words before tokenizing:
(name, Paul)
There are many tricky cases when it comes to tokenizing :
- Compound words, i.e. at the end of a sentence in a book, separated by a dash. You might want to keep these words together.
- Dates, which are not easy to process:
01.03.2019. Should you extract the date textually before? As often, it depends on your needs. - Contractions such as “I’m” or “aren’t” should also be considered, since they typically contain 2 pieces of information
- Named entities such as “Los Angeles” which should be considered as the same word in tokenization
There is no unique good tokenization technique. The methods mentioned above all make mistakes.
Some extensions include :
- Heuristic-based methods, containing a large vocabulary, but hardly handle unknown words
- Using Machine Learning models (Hidden Markov Models, Conditional Random Fields, Recurrent Neural Networks…)
Part of Speech (PoS) tagging
PoS tagging is the task that attributes grammatical categories to a given token. The aim is to detect Nouns, Verbs, Adjectives, Adverbs…
This might be useful to detect :
- noun phrases
- phrases
- end of sentences
- …
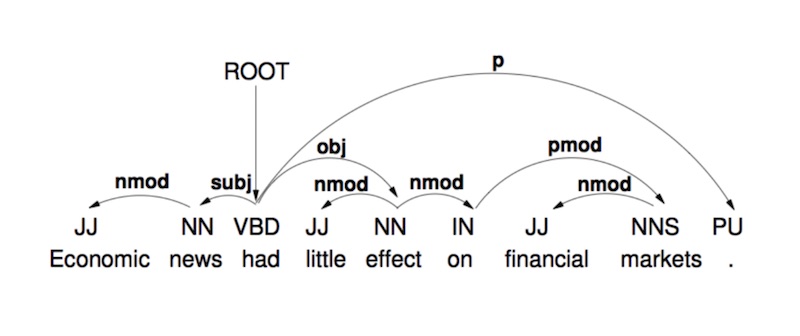
The 2 main types of methods for this task are :
- based on linguistic expertise, but it’s hardly scaling to new vocabulary and noisy inputs and it’s time-consuming
- using Machine Learning on large labeled corpus :
- using HMMs to learn transition probabilities from a grammatical category to another
- using a more general approach with CRFs
This is used in the context of disambiguation for example, and it increases the accuracy for the next step.
Filtering words, Stemming and Lemmatizing
As described above, when filtering words, we might be interested in removing :
- punctuation
- dates
- stop words
- hapax (specific words in the corpus)
We also want to reduce the size of the vocabulary by gathering inflectional forms and derivationally related forms :
- The inflectional form is a change in a word that shows a change in the way it is used in the sentence
- The morphological derivation is the process of forming a new word from an existing one by adding prefix or suffix for example.
We gather the forms of words around :
- their stems, a process that chops off the ends of words (e.g Porter’s algorithm)
- their lemmas, considered as the base, or dictionary form of a word
The goal of both stemming and lemmatization is to reduce derivationally related forms of a word to a common base form. Stemming works usually well in German, but the choice between stemming and lemmatization depends on the language considered.
II. In Python
We are now ready to implement this in Python! First, import some packages :
from nltk import wordpunct_tokenize, WordNetLemmatizer, sent_tokenize, pos_tag
from nltk.corpus import stopwords as sw, wordnet as wn
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import string
We’ll be using NLTK as our reference package for these tasks.
1. Preprocessing per document
We can define the preprocessing pipeline that will process each document as a single entity and apply the preprocessing on it :
def preprocess(document, max_features = 150, max_sentence_len = 300):
"""
Returns a normalized, lemmatized list of tokens
from a list of document, applying word/punctuation
tokenization, and finally part of speech tagging. It uses the part of
speech tags to look up the lemma in WordNet, and returns the lowercase
version of all the words, removing stopwords and punctuation.
"""
def lemmatize(token, tag):
"""
Converts the tag to a WordNet POS tag, then uses that
tag to perform an accurate WordNet lemmatization.
"""
tag = {
'N': wn.NOUN,
'V': wn.VERB,
'R': wn.ADV,
'J': wn.ADJ
}.get(tag[0], wn.NOUN)
return WordNetLemmatizer().lemmatize(token, tag)
def vectorize(doc, max_features, max_sentence_len):
"""
Converts a document into a sequence of indices of length max_sentence_len retaining only max_features unique words
"""
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(doc)
doc = tokenizer.texts_to_sequences(doc)
doc_pad = pad_sequences(doc, padding = 'pre', truncating = 'pre', maxlen = max_sentence_len)
return np.squeeze(doc_pad), tokenizer.word_index
cleaned_document = []
vocab = []
# For each document inside the corpus
for sent in document:
sent = re.sub(r"[^A-Za-z0-9^,!.\/'+-=]", " ", sent)
sent = re.sub(r"what's", "what is ", sent)
sent = re.sub(r"\'", " ", sent)
sent = re.sub(r"@", " ", sent)
sent = re.sub(r"\'ve", " have ", sent)
sent = re.sub(r"can't", "cannot ", sent)
sent = re.sub(r"n't", " not ", sent)
sent = re.sub(r"i'm", "i am ", sent)
sent = re.sub(r"\'re", " are ", sent)
sent = re.sub(r"\'d", " would ", sent)
sent = re.sub(r"\'ll", " will ", sent)
sent = re.sub(r"(\d+)(k)", r"\g<1>000", sent)
sent = sent.replace("\n", " ")
lemmatized_tokens = []
# Break the sentence into part of speech tagged tokens
for token, tag in pos_tag(wordpunct_tokenize(sent)):
# Apply preprocessing to the tokens
token = token.lower()
token = token.strip()
token = token.strip('_')
token = token.strip('*')
# If punctuation ignore token and continue
if all(char in set(string.punctuation) for char in token): #token in set(sw.words('english')) or
continue
# Lemmatize the token
lemma = lemmatize(token, tag)
lemmatized_tokens.append(lemma)
vocab.append(lemma)
cleaned_document.append(lemmatized_tokens)
vocab = sorted(list(set(vocab)))
return cleaned_document, vocab
df, vocab = preprocess(list(df))
2. Preprocessing per sentence
If you aim to do an embedding per sentence, without taking into account the structure of the documents within the corpus, then, this pipeline might be more appropriate :
def preprocess(document, max_features = 150, max_sentence_len = 300):
"""
Returns a normalized, lemmatized list of tokens from a document by
applying segmentation (breaking into sentences), then word/punctuation
tokenization, and finally part of speech tagging. It uses the part of
speech tags to look up the lemma in WordNet, and returns the lowercase
version of all the words, removing stopwords and punctuation.
"""
def lemmatize(token, tag):
"""
Converts the tag to a WordNet POS tag, then uses that
tag to perform an accurate WordNet lemmatization.
"""
tag = {
'N': wn.NOUN,
'V': wn.VERB,
'R': wn.ADV,
'J': wn.ADJ
}.get(tag[0], wn.NOUN)
return WordNetLemmatizer().lemmatize(token, tag)
def vectorize(doc, max_features, max_sentence_len):
"""
Converts a document into a sequence of indices of length max_sentence_len retaining only max_features unique words
"""
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(doc)
doc = tokenizer.texts_to_sequences(doc)
doc_pad = pad_sequences(doc, padding = 'pre', truncating = 'pre', maxlen = max_sentence_len)
return np.squeeze(doc_pad), tokenizer.word_index
cleaned_document = []
vocab = []
# Clean the text using a few regular expressions
document = re.sub(r"[^A-Za-z0-9^,!.\/'+-=]", " ", document)
document = re.sub(r"what's", "what is ", document)
document = re.sub(r"\'", " ", document)
document = re.sub(r"@", " ", document)
document = re.sub(r"\'ve", " have ", document)
document = re.sub(r"can't", "cannot ", document)
document = re.sub(r"n't", " not ", document)
document = re.sub(r"i'm", "i am ", document)
document = re.sub(r"\'re", " are ", document)
document = re.sub(r"\'d", " would ", document)
document = re.sub(r"\'ll", " will ", document)
document = re.sub(r"(\d+)(k)", r"\g<1>000", document)
document = document.replace("\n", " ")
# Break the document into sentences
for sent in sent_tokenize(document):
lemmatized_tokens = []
# Break the sentence into part of speech tagged tokens
for token, tag in pos_tag(wordpunct_tokenize(sent)):
# Apply preprocessing to the tokens
token = token.lower()
token = token.strip()
token = token.strip('_')
token = token.strip('*')
# If punctuation ignore token and continue
if all(char in set(string.punctuation) for char in token): #token in set(sw.words('english')) or
continue
# Lemmatize the token
lemma = lemmatize(token, tag)
lemmatized_tokens.append(lemma)
vocab.append(lemma)
cleaned_document.append(lemmatized_tokens)
vocab = sorted(list(set(vocab)))
return cleaned_document, vocab
And apply this function on a string version of the whole corpus :
df, vocab = preprocess(str(list(df)))
Conclusion : I hope this quick introduction to preprocessing in NLP was helpful. Don’t hesitate to drop a comment if you have a comment.