
In previous articles such as the hit song classifier, or the painter prediction, we observed how the performance of a data science task could be improved when we enrich our data. There are many reasons why you could and should think about your data enrichment, and many places you could get data from.
Collecting new data to enrich your current one might be expensive or time-consuming. But it does not always have to be this way. In this article, we will review the most common data acquisition sources and how they can help you solve your problems.
Internal sources
Most businesses have issues identifying the data they need, and even more issues identifying the data they could and should collect. However, collecting, sharing and using is probably the most efficient pipeline.
Collecting Data
Why?
Some departments are not aware of the data they could collect. I have seen insurance companies not collecting sensor data from cars’ rental since they have a fixed pricing strategy and did not really care about the micro-view. However, this kind of data is priceless for future business opportunities:
- monitor your business in real-time
- develop your own rental service
- autonomous vehicles (estimate the length of use, the distance, risk factors…)
- …
How?
This raises a technical concern: are you able to handle this data? Can you store them? Can you clean them, process them, and run queries and analytics on it? This can typically be a factor that limits the data acquisition.
If the data comes from sensors, you could easily collect a few points per second. Within a few months of use, it would represent several PetaBytes of data. Relational databases and Python analytics could reach their limits here.
What?
Most of the time, a good data acquisition strategy requires domain knowledge. I recently came across a good illustration of this concept. Doctors can have a hard time identifying early anorexia of patients as a mental disease since some patients want to keep losing weight and avoid being taken in charge at the hospital. This can obviously affect the effectiveness of the treatment of the patients. If you run studies on this disease, you might want doctors and patients to fill forms that would include the bias of sick patients not willing to be helped.
But computer vision can definitely help on this task. Indeed, researchers are currently studying the point of gaze (i.e where you look on a screen) of sick and healthy patients when displaying pictures of persons on a computer, through the computer’s webcam.
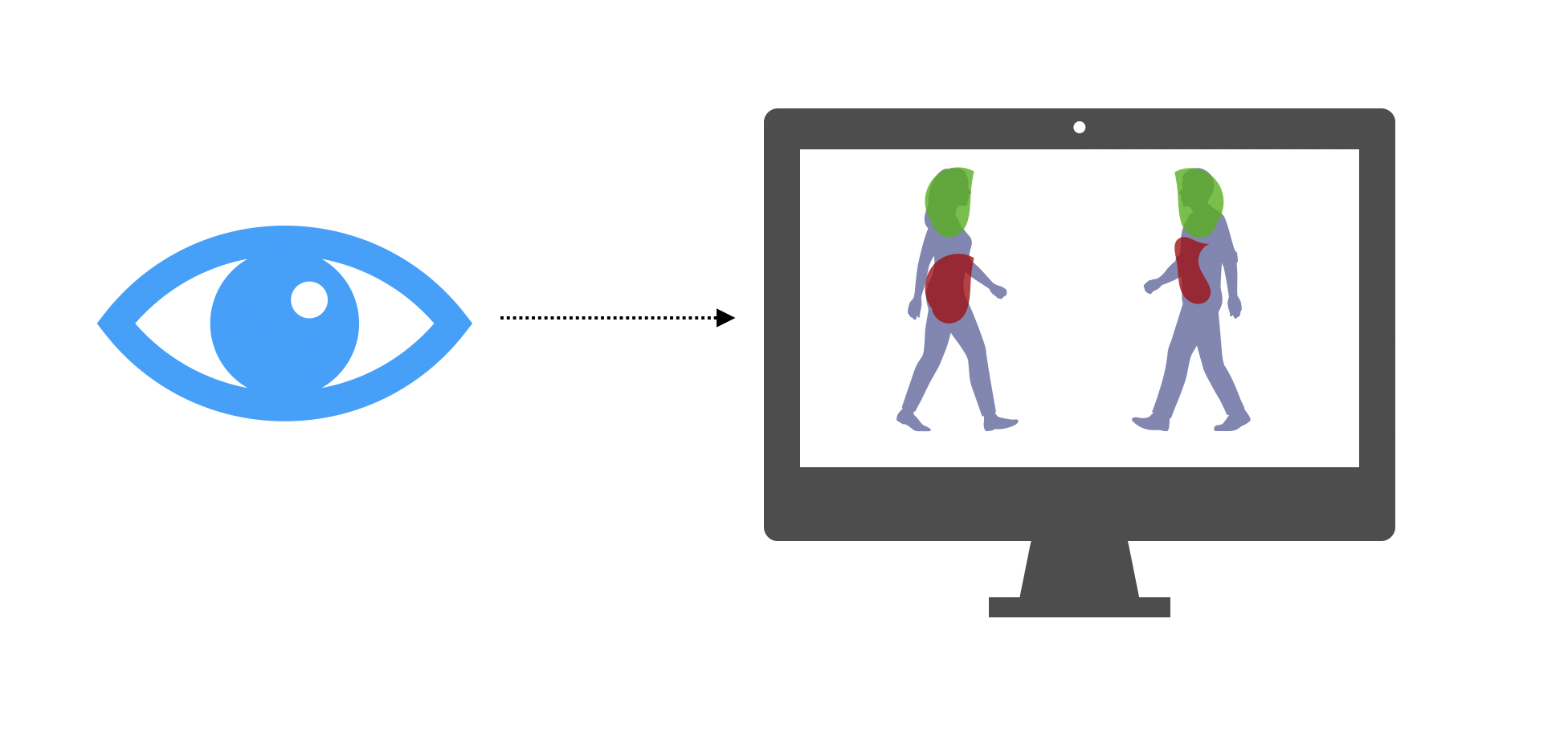
They noticed that sick patients focus their attention on other parts of the image than healthy ones. Anorexia detection could be largely improved by training a model on this new data source. You definitely need medical expertise to know that this data is less biased, and relevant to collect.
Sharing Data
Sharing data across departments of a company is not always an easy thing. The marketing department might have interesting data that it could share with you, and that could help your model or your analysis. Companies need to promote a data-first education: data is a valuable asset for the company, and all departments should be aware of that. A good data management strategy can enhance your business, and help you solve future problems easier and faster.
Using your data
Using your collected data correctly is one of the key challenges. Feature engineering and domain knowledge are the essences of your Machine Learning solutions. One could have thousands of features and billions of observations, but if you don’t select the relevant features, handle multicollinearity, create new features (e.g ratios between features), then the whole enrichment is pointless.
External sources
The solution is not always internal. There are several types of external data sources which can help.
Open Data
The notion of Open Data gathers all sources of data that are publically available. Tools such as “Google Dataset Search” help you browse these datasets.
The French government has, for example, decided to publish most of its data as open data (Geospatial data, population, car accidents…) with the hope of seeing some startups rise from this. We also trained our painter classifier using open data published by an online art collection.
Although open data sound promising, the quality of the data might not always perfect, and the quantity of information available is often limited. It is also time-consuming to identify the right dataset to use.
Scraping
Scraping, or web crawling, is the process by which we fetch the content of a webpage and copy the relevant information in a database. It remains today a common data acquisition strategy. Some websites are trying to prevent scraping, especially if the website contains valuable information (Craigslist, eBay, Amazon…).
In the hit song classifier, we scrapped Wikipedia to get the Billboard 100 from the past 9 years. There are great and powerful tools such as BeautifulSoup that help us do this in Python.
APIs
Application Programming Interfaces (APIs) are a great way to access data from external companies. We used in a previous article Spotify’s API to enrich a song dataset. APIs are generally quite easy to use, but have several limitations :
- the pricing plan might change over time. This is what happened with Google Maps’ API whose price has increased so much that some business had to stop using it.
- the quantity of data you can retrieve is limited. Twitter, for example, will limit the number of tweets you can retrieve each minute.
Mechanical Turk
Services such as Amazon Mechanical Turk or Prolific allow you to “conduct simple data validation and research”, get answers on surveys, label your data… It remains quite cheap since it relies on lots of external workers making those “micro-tasks”.
However, the objectivity of the workers should never be what you aim for, and “workers” on the platform are mostly motivated by the financial aspect of the task.
Buying data
Finally, some market places or social networks offer data to enrich your database. The cost might quite often be a limitation.
Conclusion
We covered the most common data sources for your data acquisition strategy. The perfect strategy relies on appropriate data acquisition (internal and/or external), and a good feature engineering. This is why we created Explorium (INSERT MARKETING MESSAGE HERE).