
How to install Spark?
We’ll explore 2 ways to install Spark :
- using Jupyter Notebooks
- using the Scala API
- using the Python API (PySpark)
Using Jupyter Notebooks
Programming in Scala in Jupyter notebooks requires installing a package to activate Scala Kernels:
pip install spylon-kernel
python -m spylon_kernel install
Then, simply start a new notebook and select the spylon-kernel.
Using Scala
To install Scala locally, download the Java SE Development Kit “Java SE Development Kit 8u181” from Oracle’s website. Make sure to use version 8, since there are some conflicts with higher vesions.
Then, on Apache Spark website, download the latest version. When I did the first install, version 2.3.1 for Hadoop 2.7 was the last.
Download the release, and save it in your Home repository. To know where it is located, type echo $HOME in your Terminal. It usually is /Users/YourName/.
To make sure that the installation is working, in your terminal, in your Home repository, type `(replace your version) :
cd spark-2.3.1-bin-hadoop2.7/bin
./spark-shell
Your terminal should look like this :
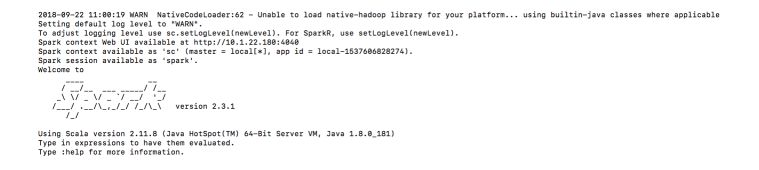
A user interface, called the Spark Shell application UI, should also be accessible on localhost:4040.
Finally, we need to install SBT, an open-source build tool for Scala and Java projects, similar to Java’s Maven and Ant.
Its main features are:
- Native support for compiling Scala code and integrating with many Scala test frameworks
- The continuous compilation, testing, and deployment
- Incremental testing and compilation (only changed sources are re-compiled, only affected tests are re-run, etc.)
- Build descriptions written in Scala using a DSL
- Dependency management using Ivy (which supports Maven-format repositories)
- Integration with the Scala interpreter for rapid iteration and debugging
- Support for mixed Java/Scala projects
Installed in the terminal using :
brew install sbt
To check that the installation is fully working, run :
./spark-shell
You should see a Scala interpreter :
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type: help for more information.
scala>
Using PySpark
For PySpark, simply run :
pip install pyspark
Then, in your terminal, launch: pyspark
Observe that you now have access to a Python interpreter instead of a Scala one.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.3.1
/_/
Using Python version 3.6.5 (default, Apr 26 2018 08:42:37)
SparkSession available as 'spark'.
>>>
Doing this install, your are also able to use PySpark in Jupyter notebooks by running :
import pyspark
Conclusion: I hope this tutorial was helpful. I’d be happy to answer any question you might have in the comments section.