
If you haven’t seen it, I recommend reading first my tutorial on Hadoop MapReduce. In this series of articles, we’ll talk about Spark. Spark is an Apache Software Foundation project that was developed to speed up the Hadoop Computational software process.
![]()
What is Apache Spark?
Spark is an open-source large scale data processing and data analysis tool, coded in Scala, a functional programming language, highly typed, less verbal than Java.
Spark is available through 4 different APIs :
- Scala: Most popular API, in which the language is typed and compiled. Therefore, code errors are checked before launch, which avoids errors after 10 hours of computation for example. Scala’s API is often used in production.
- Python: Second most popular API. The language is however only checked at runtime. This API is mostly used in POCs and R&D environments.
- Java: If the company’s infrastructure is built in Java, this might be the best option.
- R: This API is rarely used, but there’s a community around it.
Spark is compatible with most databases and distributed (or not) file systems :
- S3 (AWS),
- Google Storage
- HDFS
- Cassandra,
- HBase,
- Redshift…
Spark has an active community of over 1000 contributors, producing around 100 commits/week.
Key concepts
The main feature of Spark is that is stores the working dataset on the cluster’s cache memory, to allow faster computing.
Spark leverages task parallelization on multiple workers, just like MapReduce. Spark works the same way :
- On a single machine for tests and small data samples, local, without any cluster manager
- On a cluster for large data volumes
Spark is not a modified version of Hadoop, but Hadoop is a way to implement Spark. Indeed, Spark can be built with Hadoop components in the following ways :
- Spark on top of HDFS
- Spark on top of HDFS and Yarn
- Spark on top of HDFS and in MapReduce
Key components

- Spark Core, the underlying general execution engine for Spark platform. Other functionalities are built upon Spark Core, which provides in-memory computing and referencing datasets in external storage systems.
- Spark SQL: SparkSQL data-frames allow the use of RDD (Resilient Distributed Datasets), providing support for the structured and semi-structured data
- Spark Streaming: Spark Streaming allows pseudo-streaming, i.e. ingesting micro-batch (e.g every 20ms) and performing RDD transformations on those micro-batches.
- MLib: SparkML is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It includes the whole ML framework: pre-processing, cross-validation, algorithms… in a distributed system.
- GraphX: A distributed graph-processing framework on top of Spark, to model user-defined graphs by using Pregel abstraction API.
History
- 2003-4: MapReduce is introduced by Google
- 2006: Hadoop is developed by Yahoo!
- 2009: Spark Research projects start at UC Berkley
- 2010 : Spark Research paper
- 2010: Spark is open-sourced
- 2012 : RDD Research paper
- 2013: Spark joins the Apache Software Foundation
- 2013 : Spark Streaming paper
- 2014 : GraphX paper
- 2015 : SparkSQL paper
- 2016 : MLib paper
- 2017: Deep Learning pipelines in MLib
Why use Spark?
Hadoop applications spend more than 90% of their time doing HDFS read-write operations. Using data frames in cache greatly improves the processing time of Spark. Nowadays, Spark is widely used, and the community is way more active than around Hadoop.
Directly Acyclic Graph (DAG)
Spark offers a Directed Acyclic Graph service (DAG). The DAG :
- Cuts the script in stages: groups of tasks that do not require any data transfer between the nodes of the cluster
- Identifies the stages that can be used in parallel
- Determines where a task should be executed to minimize data transfer
- Optimizes data treatment pipeline
- Optimizes intermediate lost data collection
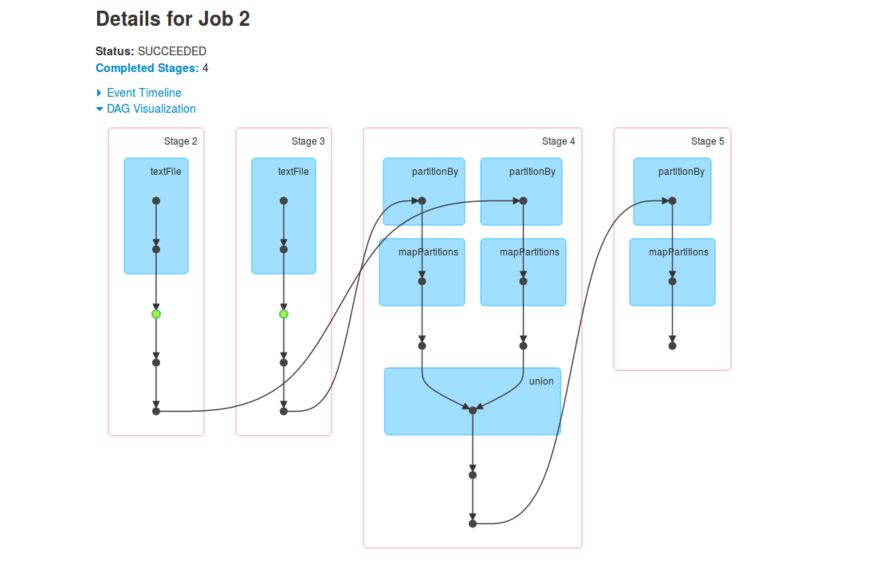
RDD
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable, read-only, distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
There are two ways to create RDDs :
- parallelizing an existing collection in your driver program,
- or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
In Spark, there are several data formats :
- RDD: one of the version versions of Spark data structure. It takes the form of distributed tuples, e.g
[(1,2,3,4), (10,20,30,40), ...]. There is no column structure in RDDs. - DataFrame: DataFrames are layered on top of RDDs. It looks like a Pandas DataFrame, with columns, but is indeed an RDD of rows.
- DataSet: DataSets are layers on top of DataFrames which allow specifying types for columns.
How does Spark work?
There are 2 types of Spark RDD operations :
- Actions are operations that return values (collect, count, take…).
- Transformations are operations that can be chained on your working dataset (filter, drop, map, union).
Only actions are evaluated. This is called lazy evaluation. You can define several transformations, are they’ll all be evaluated when you run the next action. Actions are really expensive, so you should limit the number of actions in your code.
Transformations
The main transformations are :
- map()
- filter()
- count()
- distinct()
- union()
- …
There are 2 types of transformations :
- Narrow transformation: In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of parent RDD.
- Wide transformation: In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD.
Actions
Actions, unlike transformations, do not produce new RDDs but values. Actions might be :
- count() : the number of elements in RDD
- collect() : returns the entire RDDs content
- take(n) : returns n number of elements from RDD
- countByValue()
- reduce()
Key operations
There are some key operations one can do in Spark that are interesting for parallel computation.
Shuffling
Since we work on a multi-node system, shuffling makes an efficient redistribution of our data on the working nodes. By shuffling the data across the cluster nodes, we can execute tasks much faster.
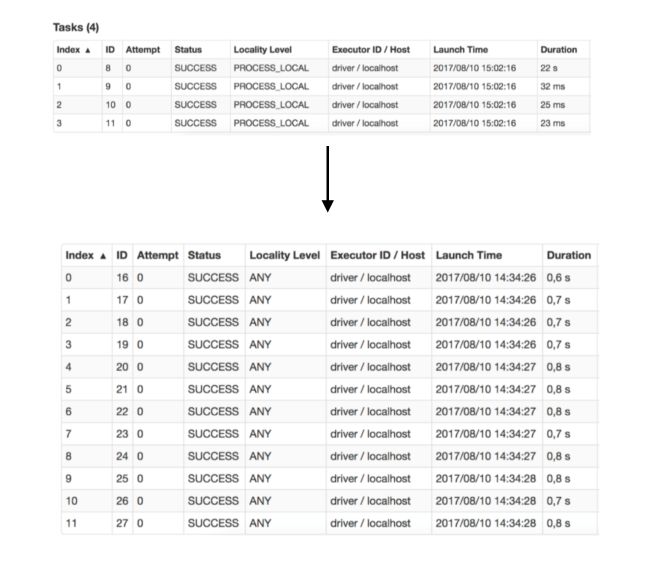
However, this operation requires to write data on disk and is therefore really expensive in terms on time.
Persistence
Persistence is the operation that stores your dataset into fast RAM.
- In some application, and especially in machine learning, we need to access the same data multiple times.
- With .persist() we force Spark to put a data collection into RAM memory.
- If you persist your client’s dataset, each node will put his part of the dataset into cache memory.
Partitioning
The partitioning describes how to split datasets on a cluster. The number of partitions determines the number of tasks that will be created by the scheduler.
When you’re working with a more complex dataset, you may consider using a partition key, just like SQL. This key will determine which part of the dataset goes on which node.
Broadcasting
Broadcasting is a way to force caching a dataset, on every node of the cluster.
Joins
Joins in Spark are similar to joins in SQL (INNER, LEFT, RIGHT, FULL).
Conclusion: All those concepts still need illustration, but it’s the purpose of the next article. I hope this high-level overview was clear and helpful. I’d be happy to answer any question you might have in the comments section.