
The annual volume of data produced worldwide is rising exponentially. Emerging markets and IoT nowadays represent more than half of the data produced in the world, and it keeps rising.
We qualify of Big Data anything too large or too complex for traditional data processing applications.
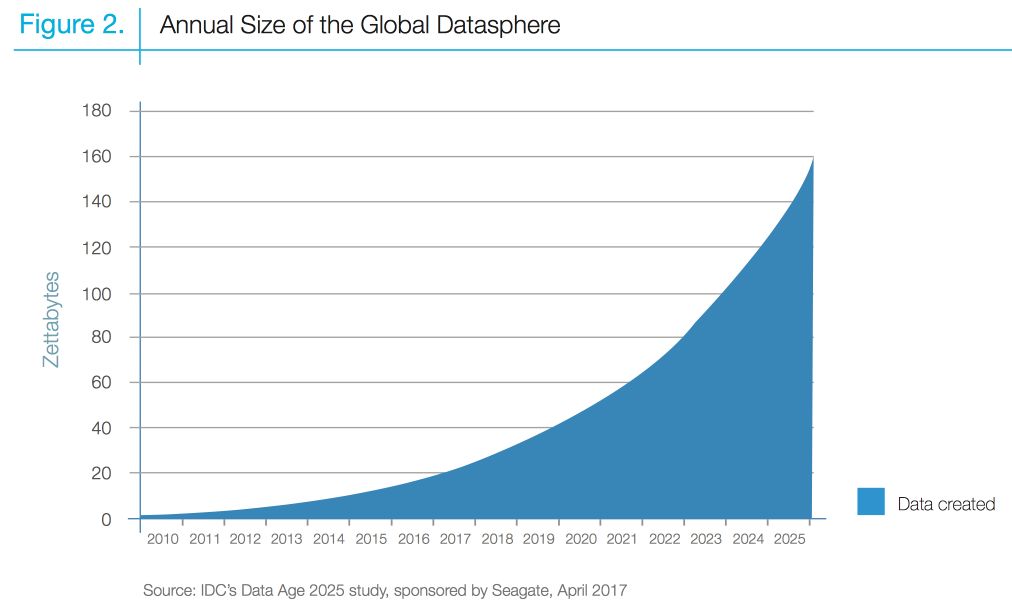
The amount of data produced by us from the beginning of time until 2003 was 5 billion gigabytes. If you pile up the data in the form of disks it may fill an entire football field. The same amount was created in every two days in 2011, and every ten minutes in 2013, and most likely every minute in 2020.
Limits of Vertical Scalability
Challenges arise when we need to capture, store, transform, transfer, analyze and present large volumes of data.
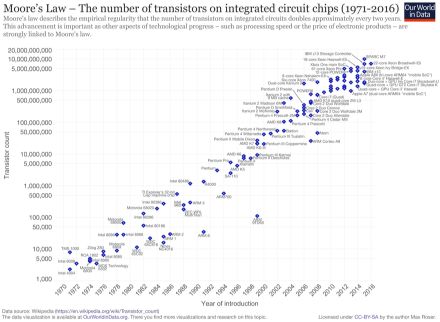
Capacities of hard drives have increased, but the rate at which data can be read have not kept up. We have reached the limits of the vertical scalability, and need to develop horizontal scalability. Moore’s law is the observation that the number of transistors in dense integrated circuit doubles about every two years. It is up to now generally true, but the rate seems to slow down.
This is however technically challenging to do since parallelizing complex computations is not trivial. This is why Google (Jeff Dean) came up with MapReduce in 2004. The original paper can be found here.
MapReduce divides the task we want to do on the data into small parts and assigns them to several computers (a cluster), and aggregates the results from them.
Before moving on, let’s define some simple terminology :
- A Cluster is a group of machines that acts as a single system.
- A Node is a single machine among the cluster.
Hadoop

Main Concept
Hadoop is an ensemble of distributed technologies, written in Java, to store and deal with a large volume of data (>To).
To get the big picture, Hadoop makes use of a whole cluster. For each operation, we use the processing power of all machines.
There are 4 big steps in MapReduce :
- **Map **: apply some arbitrary function to all inputs and output a key-value pair
- **Combine **: start combining the outputs from close outputs
- **Shuffle **: sort outputs by keys
- **Reduce **: Key per key combine outputs with an arbitrary function
What is Hadoop made of?
Hadoop is made of some core services, as described in “Hadoop, The Definitive Guide” by O’Reilly :
- Core: A set of components and interfaces for distributed filesystems and general I/O (serialization, Java RPC, persistent data structures).
- MapReduce: A distributed data processing model and execution environment that runs on large clusters of commodity machines.
- HDFS: A distributed filesystem that runs on large clusters of commodity machines.
- **YARN **: A framework for the application management in a cluster.
And other services :
- Pig: A data flow language and execution environment for exploring very large datasets. Pig runs on HDFS and MapReduce clusters.
- HBase: A distributed, column-oriented database. HBase uses HDFS for its underlying storage and supports both batch-style computations using MapReduce and point queries (random reads).
- **ZooKeeper **: A distributed, highly available coordination service. ZooKeeper provides primitives such as distributed locks that can be used for building distributed applications.
- **Hive **: A distributed data warehouse. Hive manages data stored in HDFS and provides a query language based on SQL (and which is translated by the runtime engine to MapReduce jobs) for querying the data.
Hadoop is used to develop applications that perform statistical analysis on large amounts of data.
History
- 2004: Google publishes the MapReduce paper
- 2006: Hadoop is integrated into Apache
- 2014: Apache launches Spark
- …
Today, Hadoop is a collection of related subprojects that fall under the umbrella of infrastructure for distributed computing. These projects are hosted by the Apache Software Foundation, which provides support for a community of open-source software projects.
Hadoop was created by Doug Cutting and Mike Cafarella in 2005. Doub was working at Yahoo! and wanted to support distribution for the Nutch search engine project, a production-ready tool developed by Apache.
It was developed to support distribution for the Nutch search engine project. Doug, who was working at Yahoo! at the time and is now Chief Architect of Cloudera, named the project after his son’s toy elephant. Cutting’s son was 2 years old at the time and just beginning to talk. He called his beloved stuffed yellow elephant “Hadoop” (with the stress on the first syllable). Now 12, Doug’s son often exclaims, “Why don’t you say my name, and why don’t I get royalties? I deserve to be famous for this!”

What changes with Hadoop?
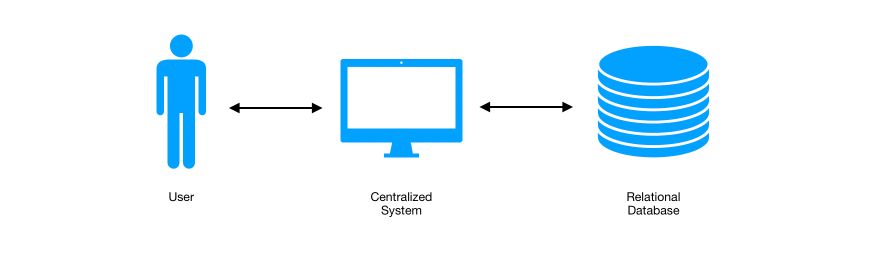
In traditional approaches, the user interacts with a centralized system which queries the databases.
With Hadoop, this paradigm changes. The task is no longer centralized but split into several workers.
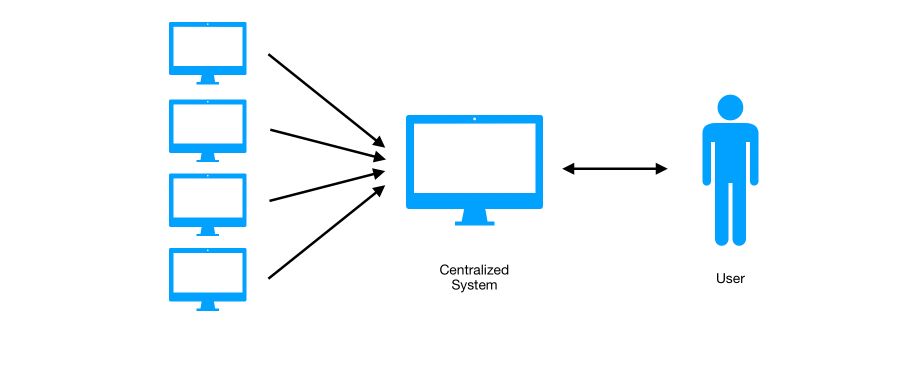
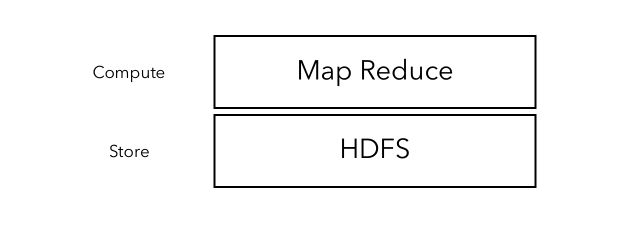
For the big picture, you should remember that HDFS is used to store the data, and MapReduce to perform actions on the data.
How does Hadoop work?
- The input data is divided into uniformly-sized blocks of 128Mb or 64Mb.
- Each file is distributed to a given cluster node, and even to several cluster nodes to handle failure of a node.
- A Master node keeps track of where each file is sent.
- HDFS is plugged on top of the local file system to supervise the processing.
- Hadoop performs a sort between the map and reduces stages.
- It then sends the sorted data to a given machine and displays the result.
Why is Hadoop used ?
Hadoop is used because :
- it can handle a large amount of data quickly
- all the steps mentioned above are automatic
- it is fully open source
- it is compatible with all platforms since written in Java
- we can add servers and remove some dynamically
- it handles failure cases
When to use Hadoop ?
Hadoop should only be used if :
- your local machine can’t handle the computation
- the computation can be parallelized
- you can’t use Spark
- you have no other choice
What are the limits of Hadoop ?
- The shuffle part is really expensive in terms of computations
- The files should be transferred to HDFS, and this is expensive
- The community around Hadoop is not active anymore
- Spark is almost systematically chosen
How to install and use Hadoop?
- From scratch, using a Linux VM and following this tutorial which relies on the GitHub of hadoop
- Using packaged solutions developed by Cloudera, Hortonworks or MapR. Hadoop Distributions pull together all the enhancement projects present in the Apache repository and present them as a unified product so that organizations don’t have to spend time on assembling these elements into a single functional component.
Here is a small summary of the advantages and disadvantages of each solution :

Hortonworks and Cloudera, the two tech giants of Big Data, have merged in October 2018, and are now worth over 3 billions $ combined.
This is all for this first article. In the next article, we’ll cover MapReduce and HDFS.
Conclusion: I hope this high-level overview was clear and helpful. I’d be happy to answer any question you might have in the comments section.