
Nowadays, data in a company come from a variety of sources :
- IoT sensors
- Images
- Transactions
- CSV files
- …
Building efficient data engineering pipelines is challenging, and variety of data does not help. Another element is the volume and the magnitude of data processed. We also need to do our processing in close to real-time. There is a need for velocity in terms of the solution we build. There are also constraints in terms of transaction. We need to handle the late arrival of a message…
Message oriented architectures with Cloud Pub/Sub
In IoT applications, we need to handle :
- data streaming from various processes or devices that do not even talk to each other
- allow other services to subscribing to new messages that we’re publishing out
- scale to handle large volume and not lose any message
- reliability to keep all the messages and remove any duplicate found
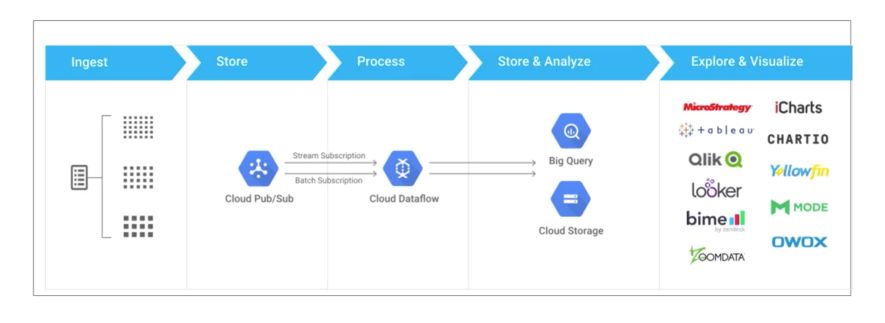
Google Cloud Sub / Pub offers reliable real-time messaging. It’s the publisher-subscriber model. Pub/Sub is a distributed messaging service that can receive messages from a variety of different streams, upstream data systems like gaming events, IoT devices, applications streams, and more.
It ensures the delivery of messages and passes them to subscribing application. Pub/Sub auto-scales, and encrypts the messages.
Upstream data is ingested into Cloud Pub/Sub as the first point of contact with our system. Cloud Pub/Sub reads, stores, and then publishes out any subscribers of this particular topic, for example, Cloud Dataflow.
A central piece of Pub/Sub is the topic. A topic is a bit like a radio antenna. A publisher can send data to a topic, and the topic might have no subscribers or a lot of them.
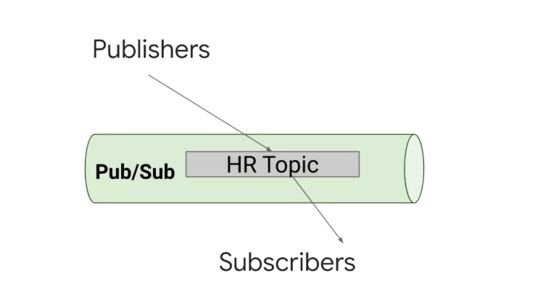
There can be 0, 1 or many publishers and subscribers.
Streaming Data Pipelines
Design Streaming Data Pipelines with Apache Beam
Now that we captured all the messages from different sources with Cloud Sub / Pub, we need to pipe in all that data into our Data Warehouse for analysis.
Data Engineers need to solve two different problems :
- design data pipelines :
- will it work both in batch and streaming?
- does the SDK support my transformations?
- are there existing solutions?
- implement them
Usually, all this is done using Apache Beam. Apache Beam lets us start from existing templates for our pipeline code. It is a portable data processing programming model that can run into a highly distributed fashion.
Apache Beam has 3 advantages :
- it is unified, and a single programming model can be used for both batch and streaming data
- it is portable, and we can execute our pipeline on multiple environments
- it is extensible since we can write new SDK, IO connectors and transformation libraries
Beam pipelines are written in Java, Go or Python. It creates a model representation of our code that is portable across many runners. Runners pass off our model to execution environments. For example, here is an example of a pipeline structure :

Implement Streaming Pipelines on Cloud DataFlow
When implementing a data pipeline, consider these questions :
- How much maintenance overhead is involved? -> Little
- Is the infrastructure reliable? -> Built on Google Infrastructure
- How is scaling handled? -> Autoscale workers
- How can I monitor and alert? -> Integrated with StackDriver
- Am I locked into a vendor? -> Run Apache Beam elsewhere
DataFlow is serverless, since resource provisioning, reliability, monitoring… are managed by Google. So what does DataFlow do exactly?
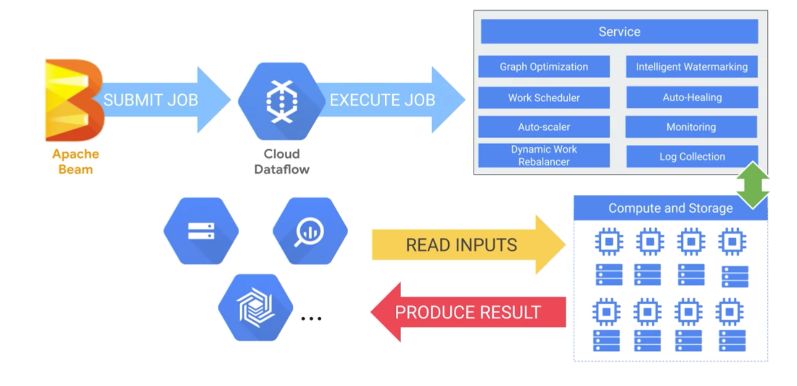
- It receives a job from Apache Beam -It optimizes the execution graph of the model to remove inefficiencies.
- It schedules out work in a distributed fashion to workers and scales as needed.
- It will auto-heal in the event of faults with those workers.
- It will re-balance automatically to best utilize the underlying workers.
- It will connect to a variety of data syncs to produce a result (BigQuery for example)
- Cloud Dataflow is managing all the compute and storage elastically to fit the demand of your streaming data pipeline.
Here is a list of all templates provided to start from :
