
In this lab, we will launch Apache Spark jobs on Could DataProc, to estimate the digits of Pi in a distributed fashion.
From the console on GCP, on the side menu, click on DataProc and Clusters.
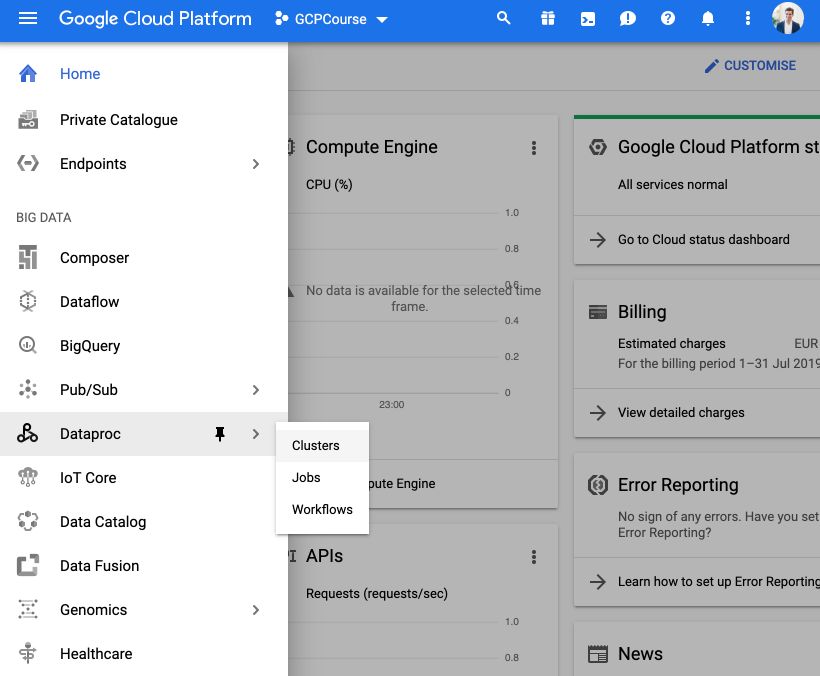
You might be needed to enable API, so just click on the button. Then, you are redirected to a page where you can create clusters. Click on Create Clusters.
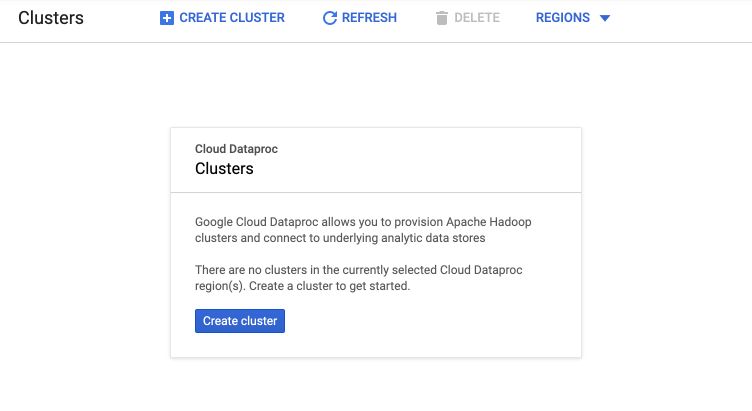
Change the name of the cluster if you want, and leave all the other parameters to default. Then, click on “Create” to create the cluster.
The cluster will now start.
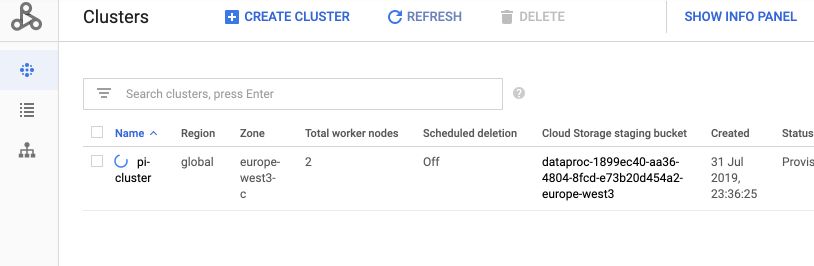
Then, move to the “Jobs” tab.
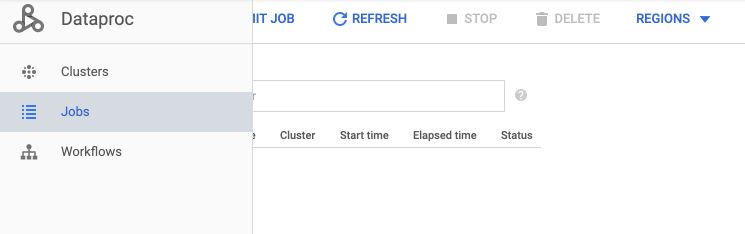
Click on the “Submit a job” button. You can give your job a specific name, and make sure to change the job’s type to Spark rather than Hadoop.
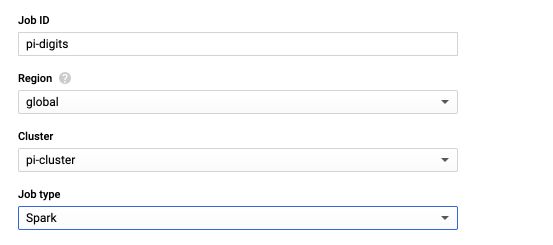
We will be using one of the pre-defined jobs in Spark examples. To do so, in the field “Main class or jar”, simply type :
org.apache.spark.examples.SparkPi
The code for this job can be found on Github. What this essentially does is to run a Monte Carlo simulation of pairs of X and Y coordinates in a unit circle and use the definition of the area to retrieve the Pi estimate.
package org.apache.spark.examples;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.ArrayList;
import java.util.List;
public final class SparkPi {
public static void main(String[] args) throws Exception {
final SparkConf sparkConf = new SparkConf().setAppName("SparkPi");
final JavaSparkContext jsc = new JavaSparkContext(sparkConf);
final int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;
final int n = 100000 * slices;
final List<Integer> l = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
final JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
final int count = dataSet.map(integer -> {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y < 1) ? 1 : 0;
}).reduce((a, b) -> a + b);
System.out.println("Pi is roughly " + 4.0 * count / n);
}
}
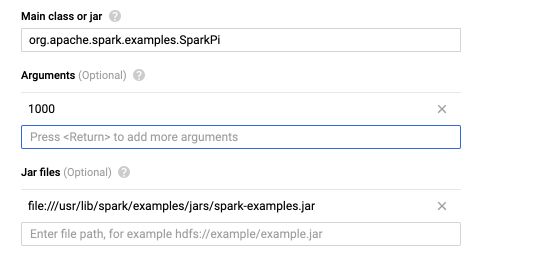
You can set the Jar files field to :
file:///usr/lib/spark/examples/jars/spark-examples.jar
The job takes arguments, which can be set to 1000 here :
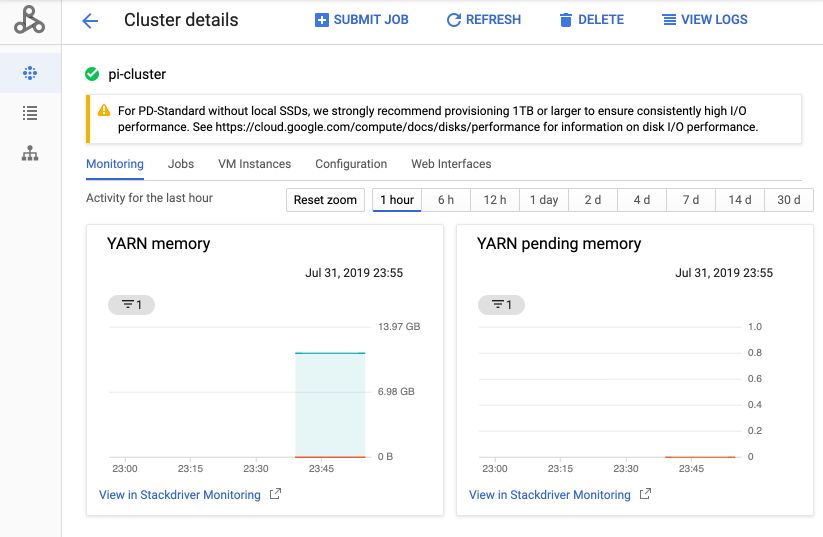
You can then click on “Submit” to submit your job. From the cluster tab, you can click on the name of the cluster and access a cluster monitoring dashboard :
If you click on “Jobs” in the Cluster tabs, you’ll notice the progress of the job we launched. It took 46 seconds in my case.
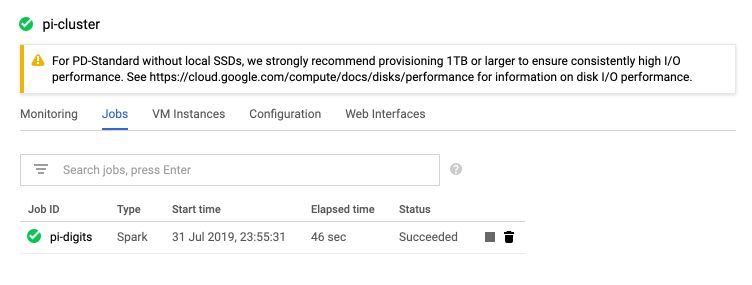
You can click on the name of the job.
You will directly see the output that states :
19/07/31 21:55:46 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1564609038185_0001
Pi is roughly 3.1418519514185195
19/07/31 21:56:12 INFO org.spark_project.jetty.server.AbstractConnector: Stopped Spark@5288ab42{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
Job output is complete
If you don’t need it anymore, make sure to DELETE the cluster.