
In this section, we will review product recommendations using Cloud SQL and Apache Spark.
Recommendation Systems
Business applications
E-commerce is probably the most common recommendation systems that we encounter. Models learn what we may like based on our preferences. We can give implicit or explicit feedback to the model (click, rating…).
Recommendations systems are used for :
- Google search results
- Facebook feed
- Netflix recommendation
- Smart Reply in Gmail
- Photo grouping in Google Photo
- Restaurant recommendation system in Google Maps
- …
Recommendation systems must scale to meet demand.
Machine learning
Suppose that we will try to build a recommender system for housing rental.
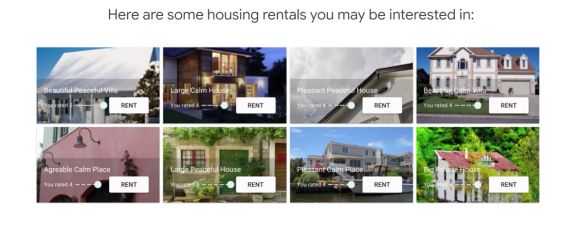
Suppose that we have ratings provided manually by users as training data. These ratings could come from explicit ratings. Maybe we showed the user the house in the past and they’ve clicked four stars after seeing the house details, or the ratings have come from implicit ratings. Maybe they’ve spent a lot of time looking at the website corresponding to this property.
We then train an ML model to predict the user’s rating of every single house in the catalog and return the 5 houses with the highest grades. We have 2 kinds of training data :
- the previous ratings of the specific user
- the ratings other people gave to each house
One of the main issues is sparsity. Some houses might have a lot of reviews, other not. Some users might have a lot of users with similar profiles, others not. We need to cluster users and items at first.
Then, build the predicted rating as: user-preference * item-quality.
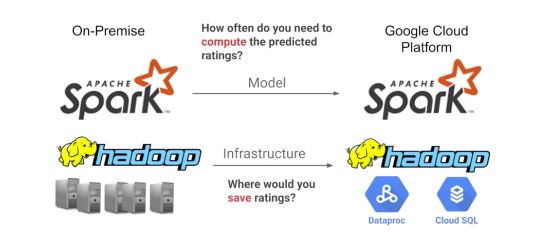
How often and where will we compute the predicted ratings?
- Stream : Continuously train the models
- Batch : Train the model once a day or once a week. This is the selected approach.
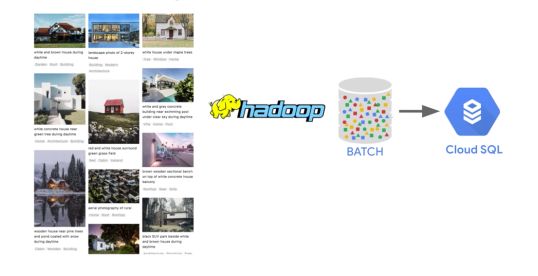
We should consider making the computations in a Hadoop Cluster to compute the rating every user would give to every house. Finally, we can store the predictions in Cloud SQL in a transactional way, or in any relational database management system.
From On-Premise to GCP
Existing on-premise models might require a migration to GCP.
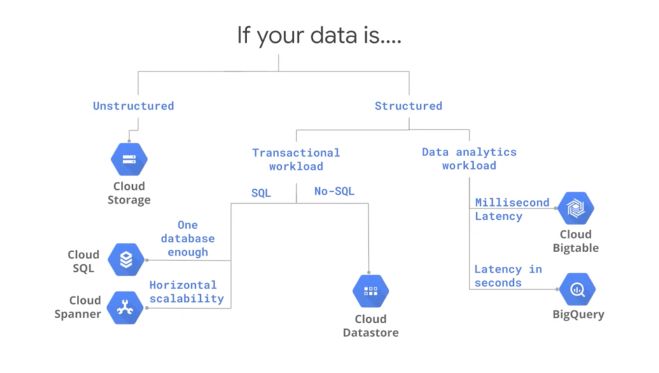
There are several storage solutions offered on GCP :
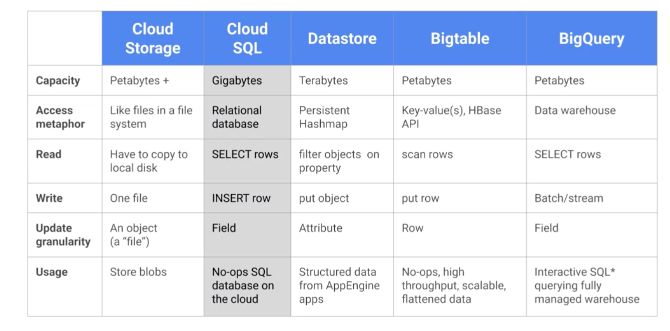
The storage solution to use is an important question :
- use Cloud Storage as a global file system
- use CloudSQL as an RDBMS for transactional data up to a few Gb
- use Datastore as a transactional NoSQL database system
- use Bigtable for low-latency NoSQL data such as sensor data
- use BigQuery as a SQL Data Warehouse to power analytics
We, therefore, use CloudSQL in our example. Cloud SQL has a lot of advantage :
Utilizing and tuning on-premise clusters
When running jobs on your own clusters, there is a high chance that you either :
- underprovision your infrastructure, and your jobs would need more computing power
- overprovision, in which case you are just wasting money
With GCP, Hadoop Clusters can be seen as fungible resources. You run the clusters when you need to run jobs, and turn them off otherwise. With scheduled deletion, you can automate when the clusters need to be shut down. You can set shutdown triggers based on time, completion of a job…
Cloud DataProc AutoScaling provides flexible capacities :
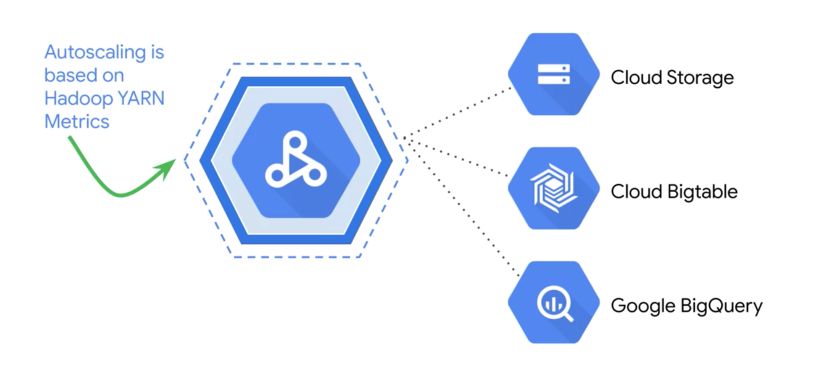
With AutoScaling, you cannot store the data on the cluster, but we use Cloud Storage or BigTable instead.
Moreover, you can incorporate preemptible virtual machines into your cluster architecture. Preemptible VMs are highly affordable, short-lived compute instances that are suitable for batch jobs and fault-tolerant workloads. They last only up to 24 hours and they can be taken away whenever somebody else comes along and offers up new compute needs for them. So if your applications are fault tolerant, and Hadoop applications are, then preemptible instances can reduce your Compute Engine costs significantly.
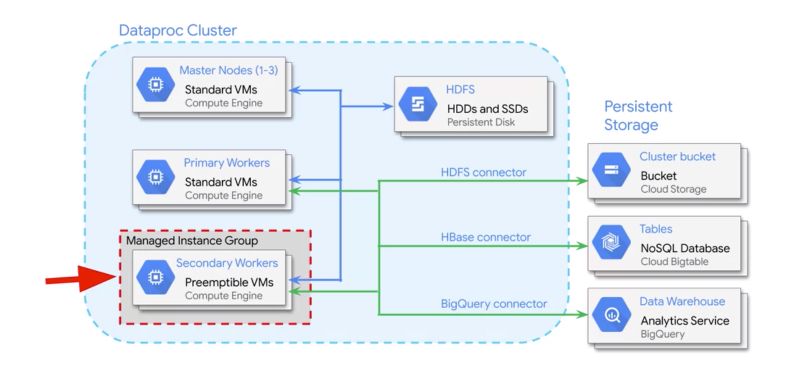
Again, since these machines are temporary, you need to store data off-cluster.
Move storage off-cluster with Google Cloud Storage
Google’s data center network speed enables separation of compute and storage. In other words, we process the data where it is without copying it.
We HDFS only on the cluster for working storage, storage during processing, but we will store all actual input and output data on Google Cloud storage.
Since the input and output data are off the cluster, the cluster can be created for a single job or type of workload and can be shut down when not in use. DataProc relies on Cloud Storage, BigTable and BigQuery for storage.
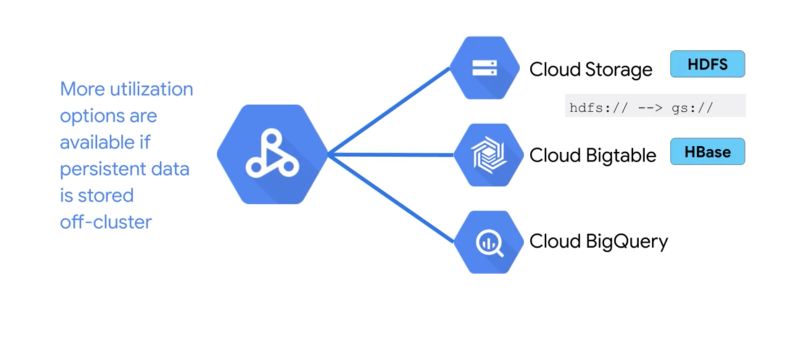
Storage using off-cluster options is usually cheaper since the disks themselves are cheaper, and the computing units can be shut down when not in use.
**Conclusion **: This is the end of the Recommendation System module, part of the week 1 of the GCP Specialization.