
There are many sources of data :
- data that you analyze
- data you collect but don’t analyze
- data you could collect but don’t
- data from 3rd parties
The main reason behind collecting data but not analyzing it is the fact that those data are often unstructured. It could include :
- free form text
- images
- calls from call center
- …
We call unstructured data all the data that are not suited for the specific type of job we want to run on it. GIS data might be structured for Google Maps, but it’s unstructured data for a relational database for example. Unstructured data might have a schema, a partial schema or no schema at all.
About 90% of enterprise data is unstructured. This is the way ML models for unstructured data are deployed on GCP :
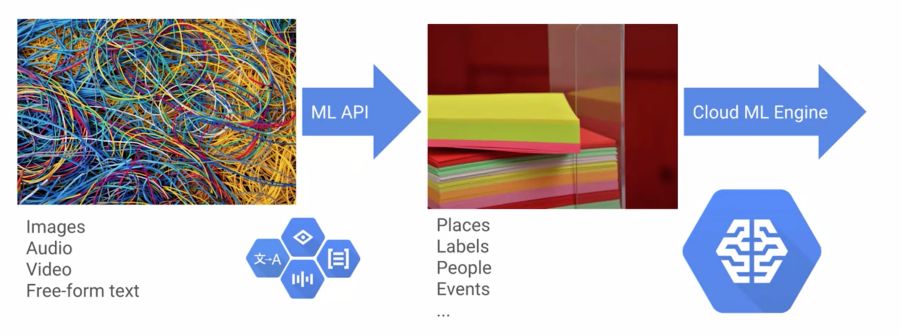
Those models, that are really data-intensive, and might include Cloud Vision or Speech-To-Text are trained by Google, and trained models are then uploaded to Cloud ML Engine using REST API.
Why Cloud DataProc ?
When working with BigData, an efficient Hadoop-based architecture can be built on Cloud DataProc. Cloud DataProc is useful for Tera Bytes or Peta Bytes data levels. But how much is 1 PetaByte of data ?

Some businesses will never need such capacities, and running Spark jobs would be more than enough. On the other hand, here’s also what on PetaByte is :

How do you scale to such large amount of data ?
- Vertical Scaling : more efficient single machines
- Horizontal Scaling : more machines running together
MapReduce arised when Google tried to index every single webpage on the Internet back in 2004. It relies on 3 main steps :
- Map
- Shuffle
- Reduce
Hadoop is the Apache solution of MapReduce. However, Hadoop has a major limitation, since the way design the job needs to be tuned for every job we must run. Apache Spark is a powerful and flexible way to process large datasets. Spark uses declarative programming : you tell the program what you want, and it figures out a way to make it happen. Spark can be used in Python, Java… It also comes with a ML library, called SparkML, and Spark SQL offers a SQL implementation on top of Spark.

A typical Spark and Hadoop deployment involves :
- setting up the hardware and the Operating System software (OSS)
- optimizing the OSS
- debug the OSS
- process data
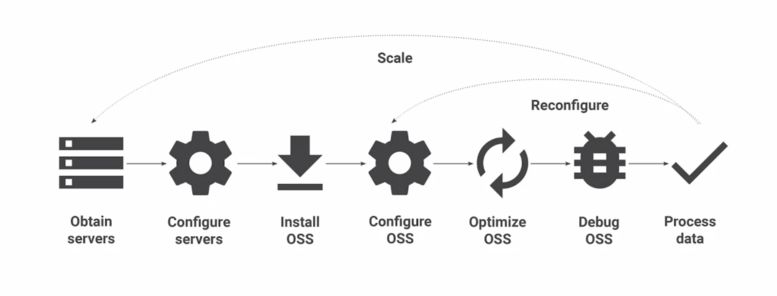
When deploying a Hadoop cluster on-prem, lots of time is spent on administration and operational issues (monitoring, scaling, reliability…). One also needs to scale the cluster according to the utilization we make of it.
DataProc is a manages service to run Hadoop on GCP. The different options to run Hadoop Clusters are the following :

A typical Hadoop Dataproc deployment requires just 90 seconds before the cluster is up S running ! Cloud DataProc also supports Hadoop, Pig, Hive and Spark, and has high-level APIs for job submissions. It also offers connectors to BigTable, BigQuery and Cloud Storage.
Architecture and machine types
DataProc uses Google Cloud machines and :
- Google networking for high performance and encryption
- Cloud Identity And Access Management for extended security
- Cloud Datalab for jupyter-like notebooks
The Cloud Dataproc architecture looks like this :
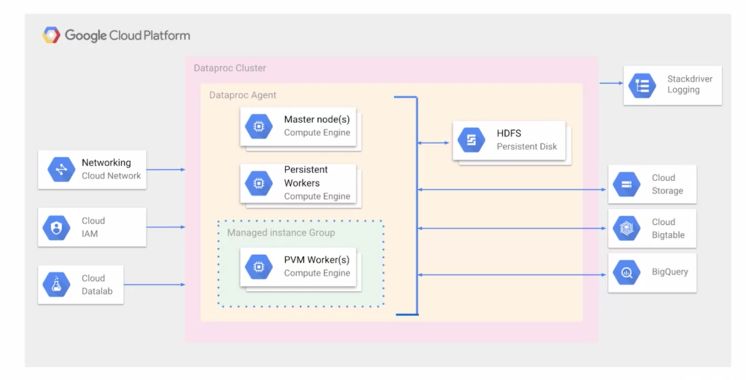
In terms on storage, one can store the processed data :
- on Cluster with HDFS
- off-cluster persistant storage with Cloud Storage
- in Big Query for interactive analysis
- in Cloud BigTable for structured storage
Dataproc is also integrated with Stackdriver logging to simplify monitoring. We can customize the persistent worker nodes to match the needs of our job.
There are several machine types available. In the schema below, each CPU logo represents a virtual CPU, and each memory icon is 3.75Gb :
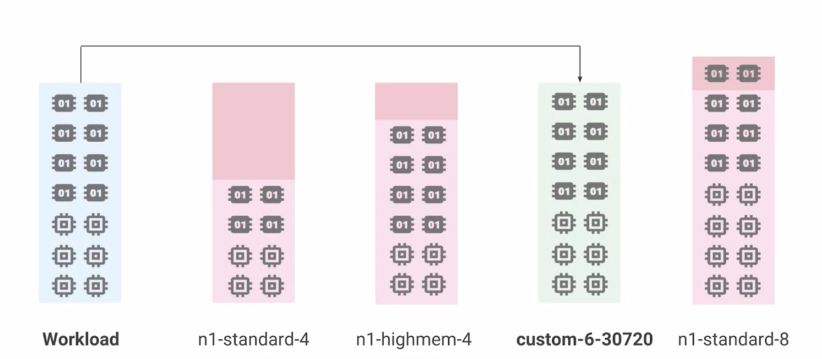
For scaling purposes, we should match the machine type with our workload. We can create custom machines using command line :
gcloud dataproc clusters create test-cluster /
--worker-machine-type custom-6-30720
--master-machine-type custom-6-23040
This command line creates a cluster where the workers have 6 CPUs for an overall 30 Gb (30*1024 = 30720) storage. The master has 6 CPUs and 22.5 Gb.
To reduce the cost of an infrastructure, one can use preemptible VMs : these are VMs that are not used by Google and are available at a discount. However, if Google needs it as a persistent VM for another client, they can take it back with minimal warning. These VMs are around 80% cheaper than standard instances. Since the node can be lost at any time, you can lose processing progress. These VMs can therefore not be used for storage. It shoul be used when you have non-critical processing an huge clusters. Overall, one should keep in mind that having more than 50% of pre-emptible VMs for a job can overall increase costs due to the failing nodes. Preemptible VMs should be a way to complete the cluster to speed up the job and reduce costs. Dataproc manages the joins and leaves of preemptible instances, there is nothing to manage.