
The following series of articles is based on the Data Engineering with Google Cloud Platform specialization on Coursera. This is a 1 months program, that required about 16h of work per week.
Introduction to GCP
History and context
How were computing resources managed over time?
- 1980s: Server on-premises. You own everything, and you manage it.
- 2000s: Data Centers. Rent the space, but pay and manage the hardware. No direct physical access to the computers.
- Now: First Generation Cloud with Virtualized Data Centers. You rent hardware and space, still controlling and configuring virtual machines. Pay only for what you provision.
- Next: Managed Services. Completely elastic storage, processing, ML. Pay for what you use.
Google has built one of the most powerful infrastructures on the planet. On every 5 CPUs being produced worldwide, Google buys one. Google has over 100 points of presence that use private fiber, on all continents. The idea of having so many edge locations is to allow users to access the resources without having to go across the globe, but simply get a cached version of that resource from the edge location.
The main software released by Google in Data Engineering for data processing are :
- Google File System, Colossus
- MapReduce, Dremel, Flume
- BigTable
- Tensorflow
- …
What is GCP?
Most of the time, companies want to move from their local environment to Google Cloud Platform. Therefore, to move to the Cloud, the steps are :
- change where you compute
- improve scalability and reliability, scaling up
- change how you compute, transforming your business
Overall, GCP allows to :
- spend less on ops and administration
- incorporate real-time data into apps and architectures
- apply machine learning broadly and easily
- become a truly data-driven company
There are four fundamental aspects of Google’s core infrastructure and a top layer of products and services that you will interact with most often.
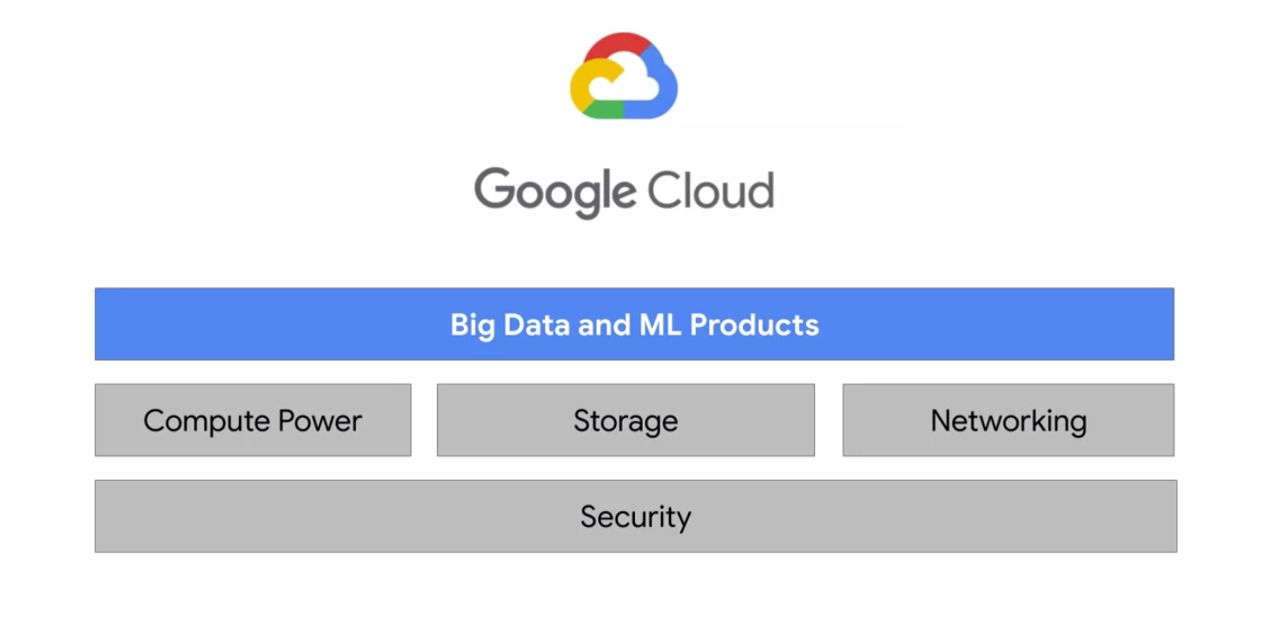
Compute Power for Analytic and ML Workloads
CPUs on the Cloud are provided by a Compute Engine of Virtual Machines. Compute Engine allows high-level access to all underlying Virtual Machines. There is no need to SSH into every single machine for example. It also allows us to increase the number of CPUs on demand for example.
If you select preemptible machines, you get up to 80% of discount on your machine charge, but you agree to give it up if someone comes along that’s willing to pay full price for those machines. For examples, if the jobs you are doing are distributed among other workers, you don’t care if the machine is re-assigned to someone else.
8 Google products serve more than 1 billion users. For a simple Google Photo stabilization video service, we talk about a billion data points (several Megapixels for each image of a video). Over 1.2 billion photos are uploaded every day on Google Photo (13 PetaBytes). On YouTube, it’s more than 400 hours every minute (1 PetaByte).
A phone’s hardware is not sophisticated enough to train an ML model of that size. Google pre-trains models in its data centers and deploys trained models on the devices. Google open sources pre-trained models as building blocks :
Jeff Dean estimates that if everyone used Voice Search for 3 minutes, Google would need to double its infrastructure. Moore’s Law is not catching up the rate, and we reach physical limits. One of the ways to overcome this issue is to develop specialized hardware for a given task. This is what Google is doing with Tensor Processing Units (TPUs), that are specialized for Machine Learning and Deep Learning with more memory and faster processing. For example, eBay uses TPUs for its infrastructure and allows them to speed their processes by a factor of 10.

Google optimized the data center cooling energy by 40% and improved power usage effectiveness (PUE) by 15% recently.
Compute Power for Analytic and ML Workloads
So far, we used storage to host one CSV file, an image, and an HTML file. But how should we store all the data generated? In the Storage Bucket too!
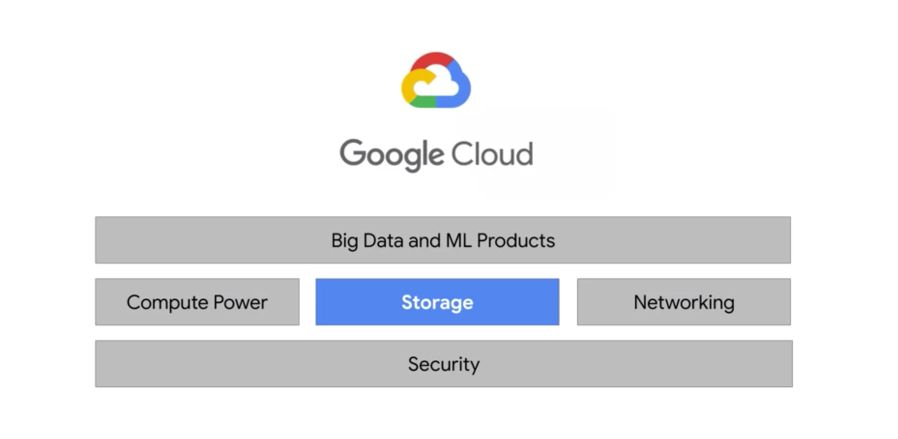
The data needs to be separated from the Compute Engine. There are 2 ways to create buckets :
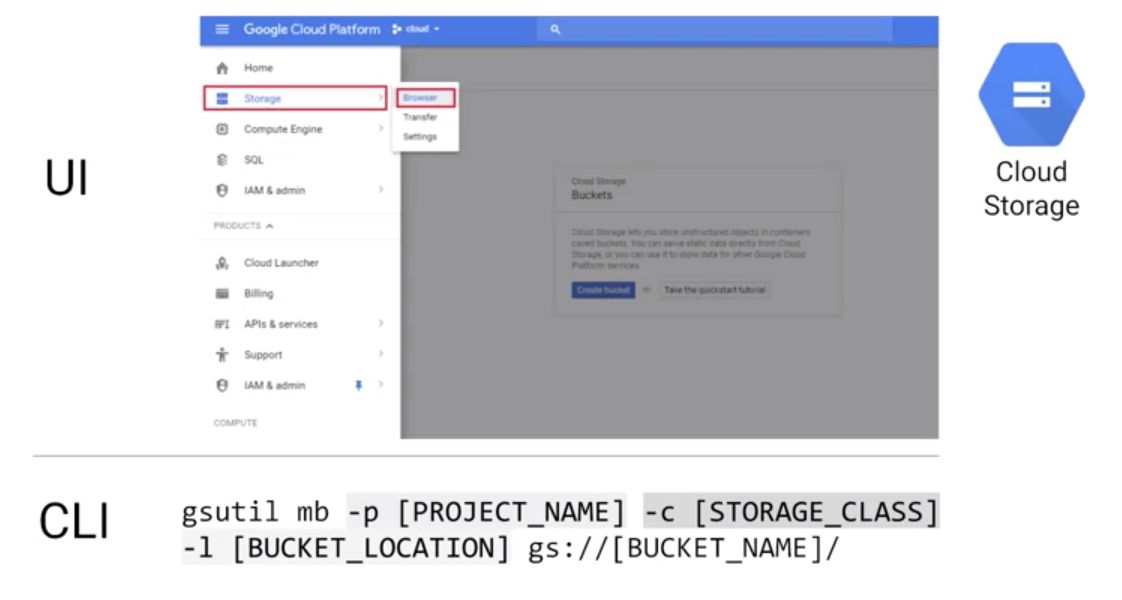
For big-data analytics, we usually choose regional storage or multi-regional storage for geo-redundancy. Nearline and Coldline are respectively used for monthly and yearly access to data. The resource access hierarchy is the following in GCP :
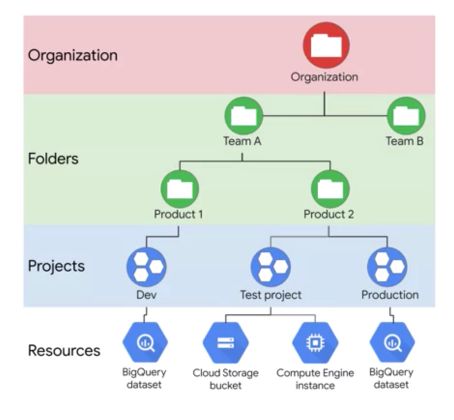
An organization has several folders, each of which contains projects (with unique names), and each project has services attached to it. Organization and folders are however not mandatory, but useful to define rules that apply to a whole organization.
To move a file to a bucket, the gs_util can be used the following way :
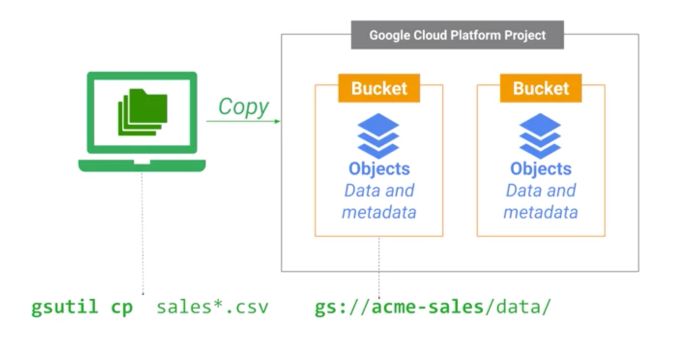
Build on Google’s Global Network

Google has laid thousands of miles of fiber optic cable that crosses oceans with repeaters to amplify optical signals. Google’s data centers around the world are interconnected by this private Google network, which by some publicly available estimates, carries as much as 40 percent of the world’s internet traffic every day.
Thanks to the speed of the data center networks at Google, they are now able to split computation and storage and no longer have both on the same machine. The speed reached 1 Petabyte/s of total bisection bandwidth. This basically means that you can perform computation on data located elsewhere.
You need to serve out the results of your analytics and predictions, perhaps to users who are all around the world. This is where Edge points of presence come in.
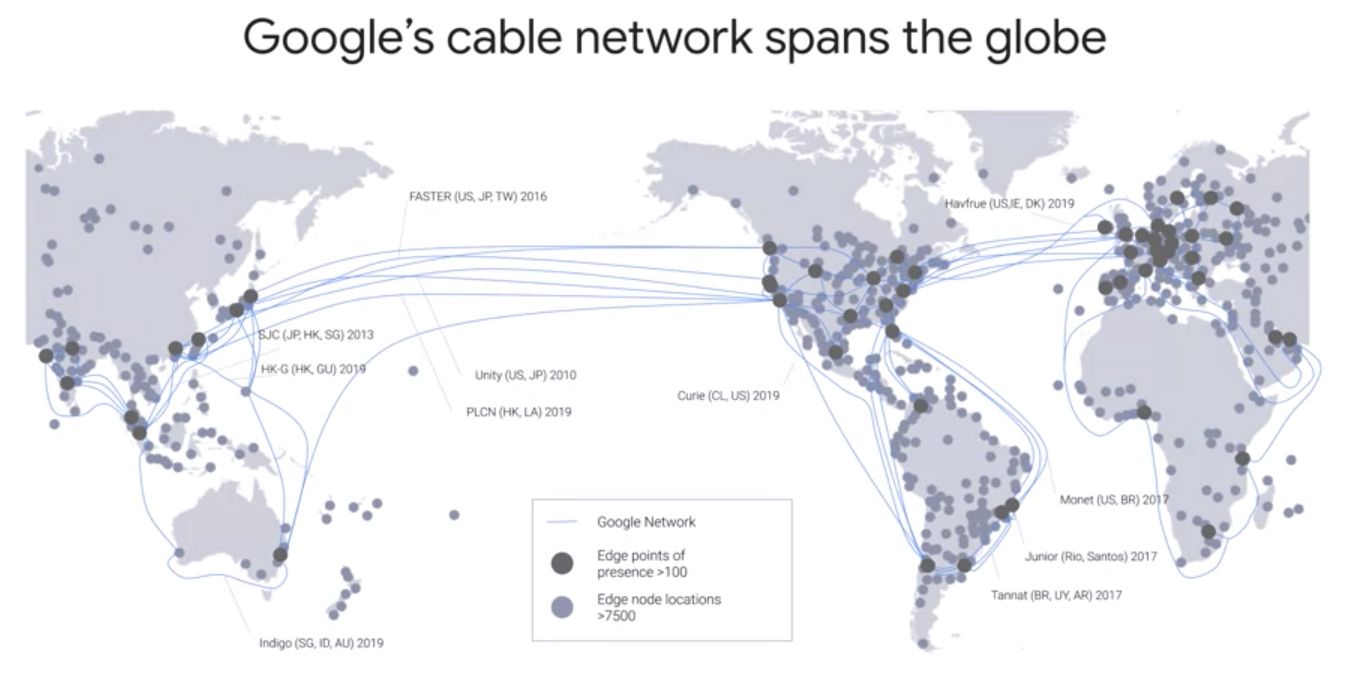
The network, Google’s Network, interconnects with the public Internet at more than 90 internet exchanges and more than 100 points of presence worldwide. When an Internet user sends traffic to a Google resource, Google responds to the user’s request from an Edge network location that will provide the lowest delay or latency. Google’s Edge caching network places content close to end-users to minimize latency. Your applications in GCP, like your machine learning models, can take advantage of this Edge network too.
Security: On-premise vs Cloud-native
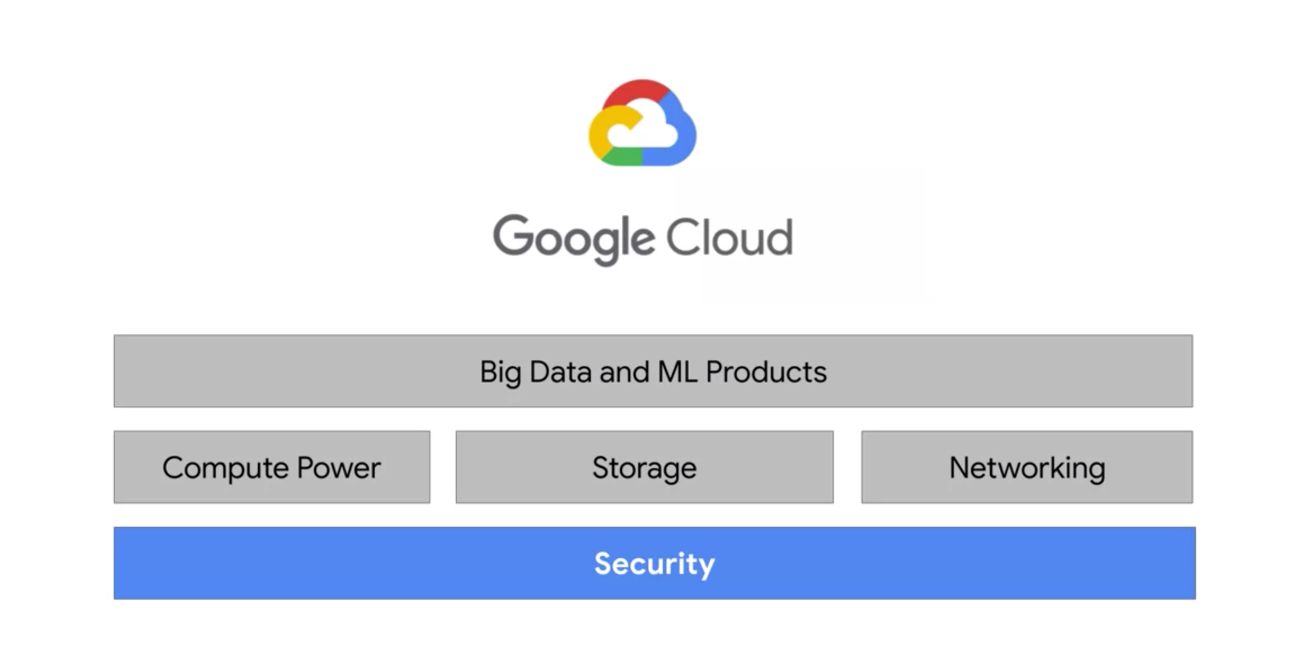
Thanks to its scale, Google can manage a lot of security layers that would be almost impossible to manage (at that level) for an on-premise service. The only part left to secure for the user is the data access policy, but Google provides tools such as IAM to define policies. Communications to Google are encrypted in transit and offer multiple layers of security. Stored data is automatically encrypted at rest and distributed for availability and reliability.
In Big Query, data are key encrypted, and keys are themselves key-encrypted.
Google Cloud Big Data Tools
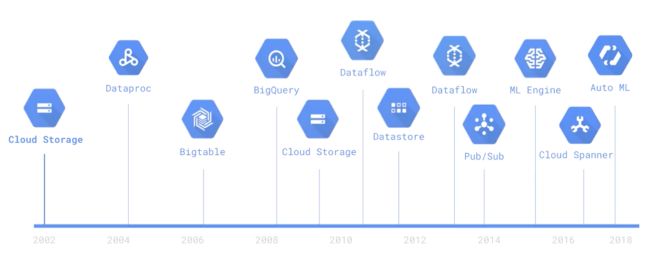
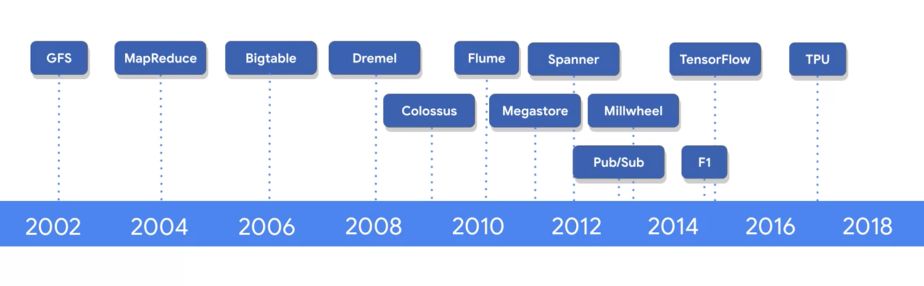
Evolution of Google Cloud Big Data Tools
Google invented new data processing methods as it grew :
- Google File System to handle a large amount of data
- MapReduce to distribute computations over clusters
- Recording and retrieving millions of rows with BigTable
- Dremel to automate MapReduce
- …
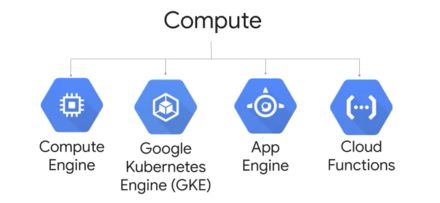
Which service to choose?
GCP offers a range of services in terms of computation, among which :
- Compute Engine to manage services instances on your own
- Google Kubernetes Engine (GKE) allows running containerized applications on clusters of machines.
- App Engine is a way to run code in the Cloud without having to worry about the infrastructure
- Cloud Functions is a serverless application of Functions as a service and executes your code in response to events (e.g a new file)
Similarly, most applications need a database system. There are several options :
- From a compute engine’s VM, set up a fully custom database
- Or use managed services such as Bigtable, Cloud Storage, Cloud SQL, Cloud Spanner or CloudDatastore
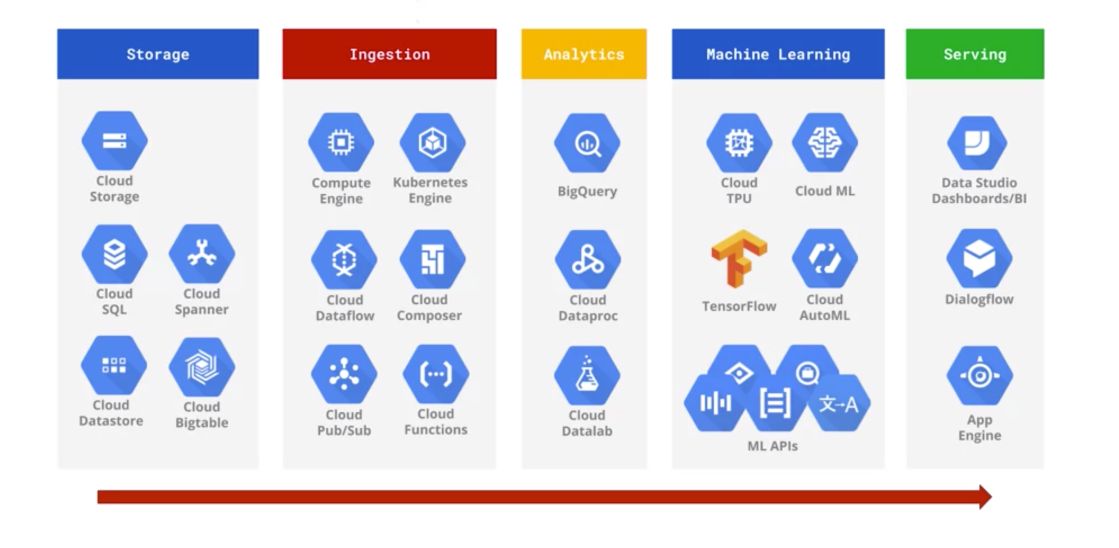
Here is a list of all Big Data and ML products in GCP :
What can you do with GCP?
Here is a series of use cases presented in the certification :
- AutoML Vision to automatically recognize common elements of furnishings and architectures in real estate
- Company email routing based on NLP services using email classification
- Sorting bad potatoes on a food chain
- …
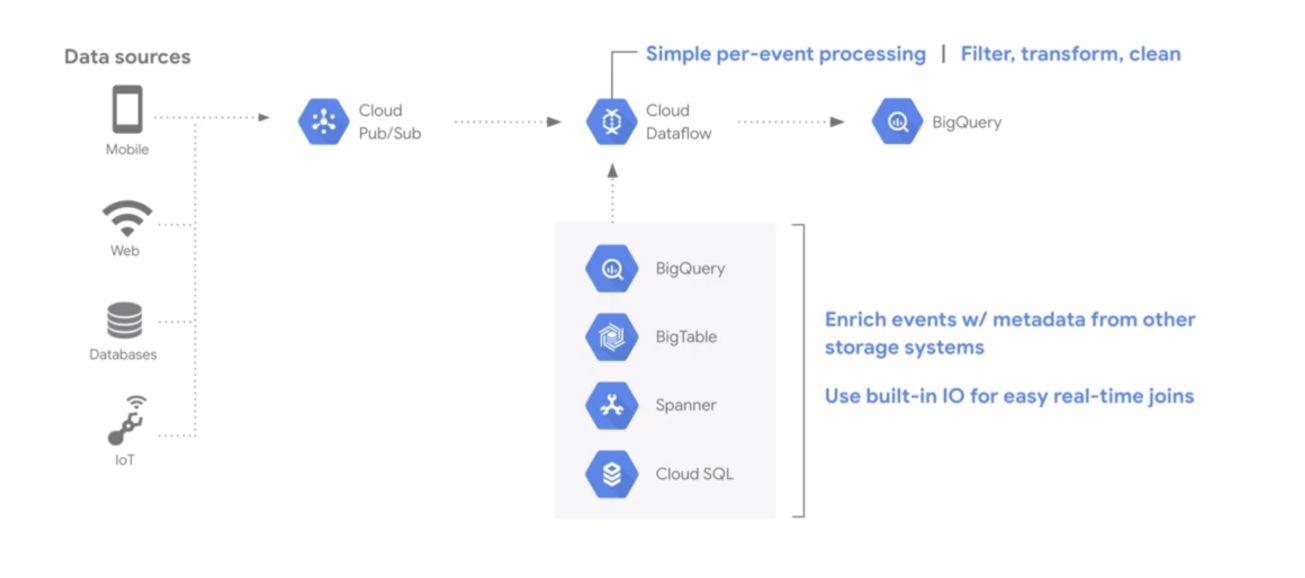
Example: Architecture overview of delivery service :
**Conclusion **: This is the end of the Introduction To Google Cloud Platform module, part of week 1 of the GCP Specialization on Coursera.