
In this article, we’ll get to the core of the exercise: launch a MapReduce WordCount job.
Launch the Job
There are several commands we can use over hadoop:
namenode -format: Formats the DFS filesystem.secondarynamenode: Runs the DFS secondary namenode.namenode: Runs the DFS namenode.datanode: Runs a DFS datanode.dfsadmin: Runs a DFS admin client.mradmin: Runs a Map-Reduce admin client.fsck: Runs a DFS filesystem checking utility.fs: Runs a generic filesystem user client.balancer: Runs a cluster balancing utility.oiv: Applies the offline fsimage viewer to an fsimage.fetchdt: Fetches a delegation token from the NameNode.jobtracker: Runs the MapReduce job Tracker node.pipes: Runs a Pipes job.tasktracker: Runs a MapReduce task Tracker node.historyserver: Runs job history servers as a standalone daemon.job: Manipulates the MapReduce jobs.queue: Gets information regarding JobQueues.version: Prints the version.jar <jar>: Runs a jar file.distcp <srcurl> <desturl>: Copies file or directories recursively.distcp2 <srcurl> <desturl>: DistCp version 2.archive -archiveName NAME -p <parent path> <src>* <dest>: Creates a hadoop archive.classpath: Prints the class path needed to get the Hadoop jar and the required libraries.daemonlog: Get/Set the log level for each daemon
To launch the Hadoop MapReduce job, you should simply type the following command from the VM’s terminal :
hadoop jar wc.jar WordCount TP/input TP/output
You can see the cluster work from this page : http://localhost:8088/.
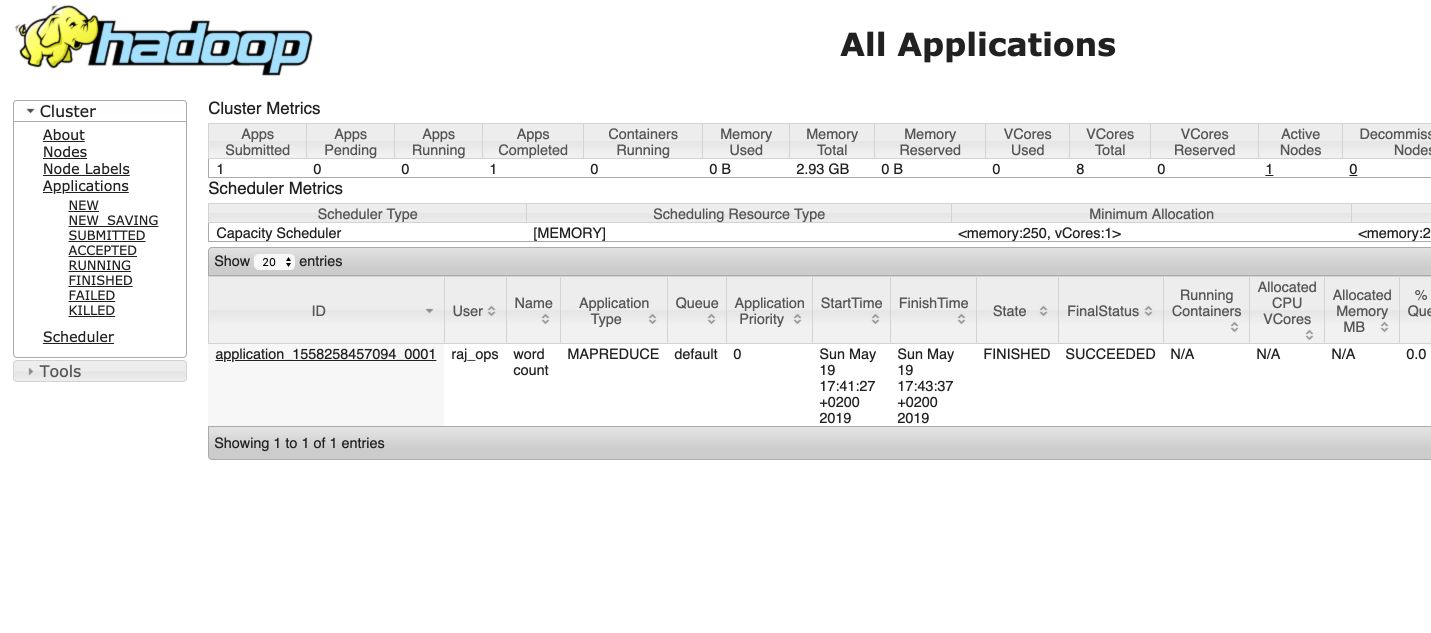
YARN
This page displays the work done on YARN. Apache Hadoop YARN is the resource management and job scheduling technology in the open-source Hadoop distributed processing framework. One of Apache Hadoop’s core components, YARN is responsible for allocating system resources to the various applications running in a Hadoop cluster and scheduling tasks to be executed on different cluster nodes.
YARN stands for Yet Another Resource Negotiator, but it’s commonly referred to by the acronym alone.

Apache Hadoop YARN decentralizes execution and monitoring of processing jobs by separating the various responsibilities into these components:
- A global ResourceManager that accepts job submissions from users, schedules the jobs and allocates resources to them
- A NodeManager slave that’s installed at each node and functions as a monitoring and reporting agent of the ResourceManager
- An ApplicationMaster that’s created for each application to negotiate for resources and work with the NodeManager to execute and monitor tasks
- Resource containers that are controlled by NodeManagers and assigned the system resources allocated to individual applications
Output
First of all, go the file viewer from http://localhost:8088/.
Go to user > raj_ops > TP > output and click on part-r-00000 to view the file :
You should see something like this :
"#Muscular 1
"'Come 1
"'Dieu 1
"'Dio 1
"'From 1
"'Grant 1
"'I 4
"'No 1
...
"Anna 2
"Annette, 1
"Announce 1
"Another 7
"Any 2
"Anybody 1
"Anyhow 1
"Anyhow, 2
"Anything 1
"Appeal 1
"Apropos, 1
"Arakcheev 1
"Are 30
"Aren't 2
"Arguing? 1
"Arinka! 1
"Arnauts!" 1
"Arrange 1
"Arranging 1
"Arthur 1
"As 36
And this is it! We managed to get the results of the MapReduce WordCount job. In the next article, we’ll see how to submit Python scripts for the Map and the Reduce Parts.
Conclusion: I hope this tutorial was clear and helpful. I’d be happy to answer any question you might have in the comments section.