December 2020
Started to work on my candidacy exam and research plan proposal for EPFL.
More and more research focuses on social network analysis (SNA) in criminal networks. However, are these methods acutally used by Law Enforcement Agencies (LEAs) and can they leverage it properly? This paper goes some way towards addressing these issues by drawing on qualitative interviews with criminal intelligence analysts from two Australian state law enforcement agencies.
Some past studies have shown that there is sometimes a missalignment between the suspects identified/followed by LEAs and the actual vital characters as identified by SNA. It is hard for researchers to access real world data for security reasons, and it is hard to track how efficient a SNA system actually is in production.
Semi-structured interviews were conducted among 2 Australian state-police, with respectively 10 and 17 participants, betweeen 2015-2016. These state police have budgets exceeding 3 billion $ each, and more than 10’000 employees each.
Participants are analysts working with digital tools, most of them learned about SNA through internal training.
The understanding of SNA for most analysts is limited to the understanding of the network structure (who knows who), and some basic metrics like the centrality. Most of them do not have a proper idea of what the difference between “betweenness centrality” and “degree centrality” is, it’s rather just buttons on the sidebar. Few tools that they use involve disrupting networks or predicting hidden links.
Some participants suggest that SNA is used to identify suspects that were not on the radar of LEAs so far. Also, some suggest that it helps identify if a new information is important or not.
Challenges can be grouped in 4 categories:
No or few feedbacks are provided on the tool. When a case is over, additional studies should be conducted and feedback should be given (could be automatic, re-train algorithms…). However, no organization is doing that for the moment.
The lack of training and the technical gap between the software capability and the understanding of analysts is also an issue.
I’ve had several meetings with LEAs these pasts months, and start to understand how they use SNAs tools. Quite often, the lack of training could be partly filled by simple videos explaining how betweenness centrality works for example. I’m pretty sure few softwares currently include that.
Then, I do believe in continual/incremental learning. This is a different learning paradigm for algorithms, since it does require constant feedback on the tool. Clicks (such as merging nodes) should re-train a matching algorithm automatically for example.
]]>If you don’t have Homebrew, here’s the command:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Spark requires Java8, and this is where I had to browse Github to find this alternative command:
brew cask install homebrew/cask-versions/adoptopenjdk8
You probably know it, but Apache-Spark is written in Scala, which is a requirement to run it.
brew install scala
We’re almost there. Let’s now install Spark:
brew install apache-spark
You might want to write your Spark code in Python, and pySpark will be useful for that:
pip install pyspark
Whether you have bashrc or zshrc, modify your profile with the following commands. Adapt the commands to match your Python path (using which python3) and the folder in which Java has been installed:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
export JRE_HOME=/Library/java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home/jre/
export SPARK_HOME=/usr/local/Cellar/apache-spark/3.0.1/libexec
export PATH=/usr/local/Cellar/apache-spark/3.0.1/bin:$PATH
export PYSPARK_PYTHON=/Users/maelfabien/opt/anaconda3/bin/python
Finally, source the profile using:
source .zshrc
And you are all set!
Now, in your Jupyter notebook, you should be able to execute the following commands:
import pyspark
from pyspark import SparkContext
sc = SparkContext()
n = sc.parallelize([4,10,9,7])
n.take(3)
And observe the SparkUI on the following link: http://localhost:4040/.
]]>MFCCs have long been the standard hand-crafted features used as inputs for the majority of speech-related tasks. Nowadays, most X-vectors for speaker identification and speaker verification systems still rely on MFCCs, voice activity detection (VAD) and cepstral mean and variance normalization (CMVN). MFCCs are used in speaker recognition, in conjunction with Gaussian mixture models, i-vectors, x-vectors, and more recently ResNet and DenseNet speaker embeddings.
Lately, some end-to-end models that directly embed the raw waveform and perform downstream tasks arised. These approaches, although encouraging, only reached limited performances.
At Interspeech 2020, a paper by Weiwei Lin and Man-Wai Mak caught my attention. The paper claims to learn speaker emebeddings from raw waveforms using a simple DNN architecture, with a similar approach to Wav2Vec.
Let’s dive into the paper :)
Why don’t we directly input waveforms to an X-vector system? Well, because the frames it processes are 25 to 30 ms long, and the effective receptive field of the X-vector would be too small.
One architecture that has often been used in speech is Convolutional Neural Networks. Using CNNs with large strides and kernel sizes as an encoder network has proven to be efficient in Wav2Vec. Here, the authors use 5 convolutional layers with kernel sizes (10, 8, 4, 4, 4) and strides (5, 4, 2, 2, 2). This encodes 30ms of speech and 10ms frame shift.
I hope this wav2vec series summary was useful. Feel free to leave a comment
All references:
]]>You might have already heard of Fairseq, a sequence-to-sequence toolkit written in PyTorch by FacebookAI. One of the most common applications of Fairseq among speech processing enthusiasts is wav2vec (and all the variants), a framework that aims to extract new types of input vectors for acoustic models from raw audio, using pre-training and self-supervised learning.
In this article, we will cover the 4 core papers of this wav2vec series, all of them coming from Facebook AI. All these papers are building blocks of what could be a great innovation in speech recognition but also a lot of other downstream tasks related to speech:
It is not new that speech recognition tasks require huge amounts of data, commonly hundreds of hours of labeled speech. Pre-training of neural networks has proven to be a great way to overcome limited amount of data on a new task.
What we mean by pre-training is the fact of training a first neural network on a task where lots of data are available, saving the weights, and creating a second neural network by initializing the weights as the ones saved from the first one. This learns general representations on huge amounts of data, and can supposedly improve the performance on the new task with limited data. This has been applied extensively in Computer Vision, Natural Language Processing, and more recently, for certain speech tasks.
When pre-training, you can either do it:
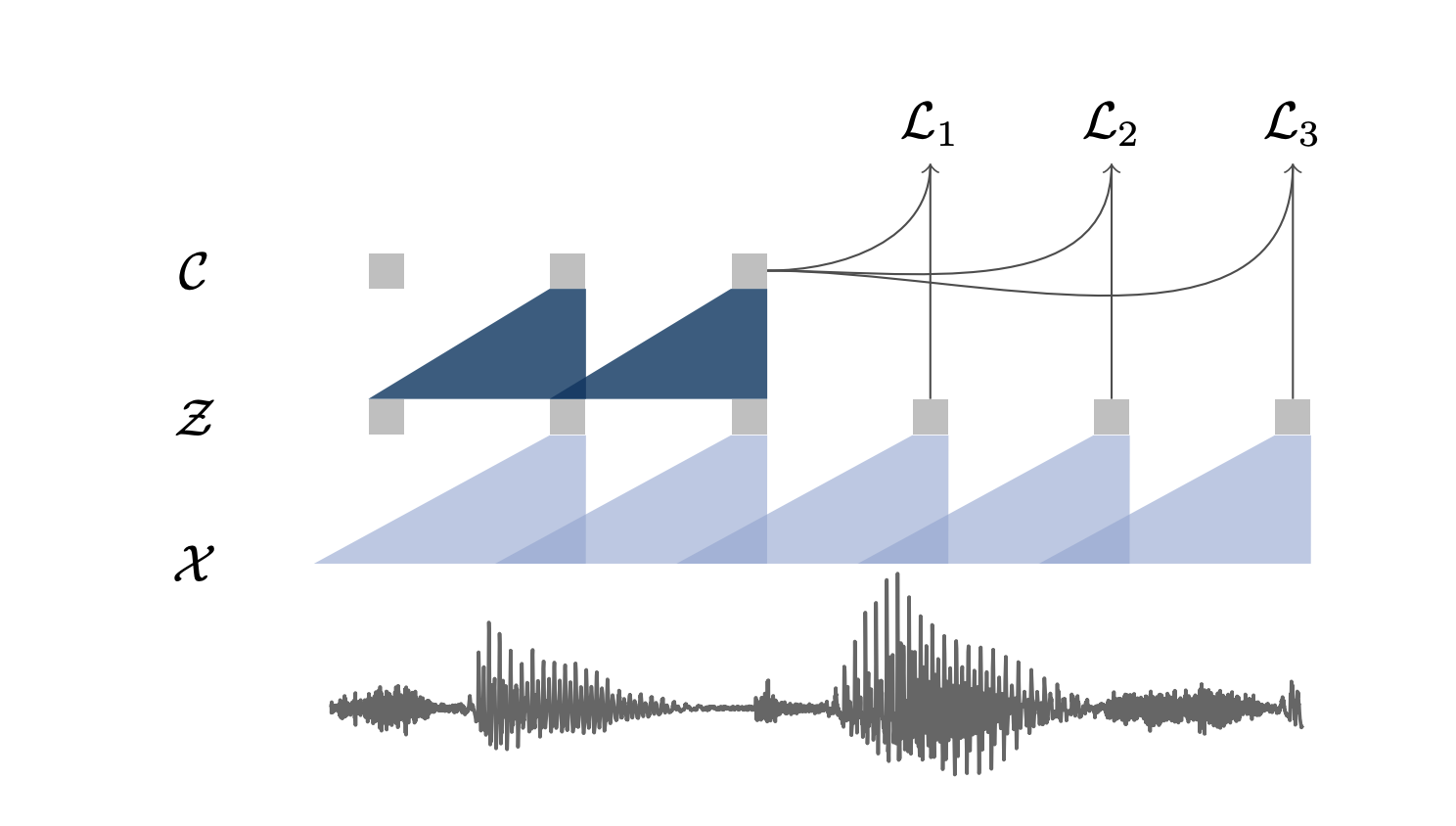
Supervised pre-training is clear. This is similar to transfer learning where you pre-train a model, knowing you \(X\) and \(y\). But for unsupervised pre-training, you learn a representation of speech. wav2vec, is a convolutional neural network (CNN) that takes raw audio as input and computes a general representation that can be input to a speech recognition system. The objective is a contrastive loss that requires distinguishing a true future audio sample from negatives.
Given an input signal context (speech up to a certain time-stamp), the aim is to predict the next observations from this speech sample.
Problem: This usually requires being able to properly model \(p(x)\), the distribution of speech samples.
Solution: Lower the dimensionality of the speech sample through an “encoder network”, and then use a context network to predict the next values. wav2vec learns representations of audio data by solving a self-supervised context-prediction task.
More formally, given audio samples \(x_i \in X\), we:
A representation of these 2 networks is presented in the figure below:
Here are the network details of wav2vec implementation:
The model learns to distinguish a true sample \(z_{ik}\), \(k\) steps in the future, from a proposal distribution \(p_n\), called a contrastive loss, defined by:
\[\mathcal{L}_{k}=-\sum_{i=1}^{T-k}\left(\log \sigma\left(\mathbf{z}_{i+k}^{\top} h_{k}\left(\mathbf{c}_{i}\right)\right)+\underset{\tilde{\mathbf{z}} \sim p_{n}}{\mathbb{E}}\left[\log \sigma\left(-\mathbf{\tilde { z }}^{\top} h_{k}\left(\mathbf{c}_{i}\right)\right)\right]\right)\]We then optimize the loss over several time steps:
\[\mathcal{L} = \sum_{k=1}^K \mathcal{L}_k\]To get the expectation of the proposal distribution, we sample ten negative examples by choosing uniformly distractors from these negative audio sequences. In order words, we average ten uniformly sampled values from different audio samples. \(\lambda\) is the number of negative samples (10 lead to the best performance).
By predicting the next steps, we perform a task, called self-supervised training for speech. But it is also widely applied in NLP and CV.
In self-supervised learning, we train a model using labels that are naturally part of the input data, rather than requiring separate external labels. For example, in an NLP model, we train a model to predict the next words. This information is part of the training data itself, and the model learns some information on the nature of language. Think of models like GPT or ULMFiT that do this in NLP. GPT-3 appears to be so good at this that you can use it for Question Answering on generic topics without fine-tuning, and get proper replies.
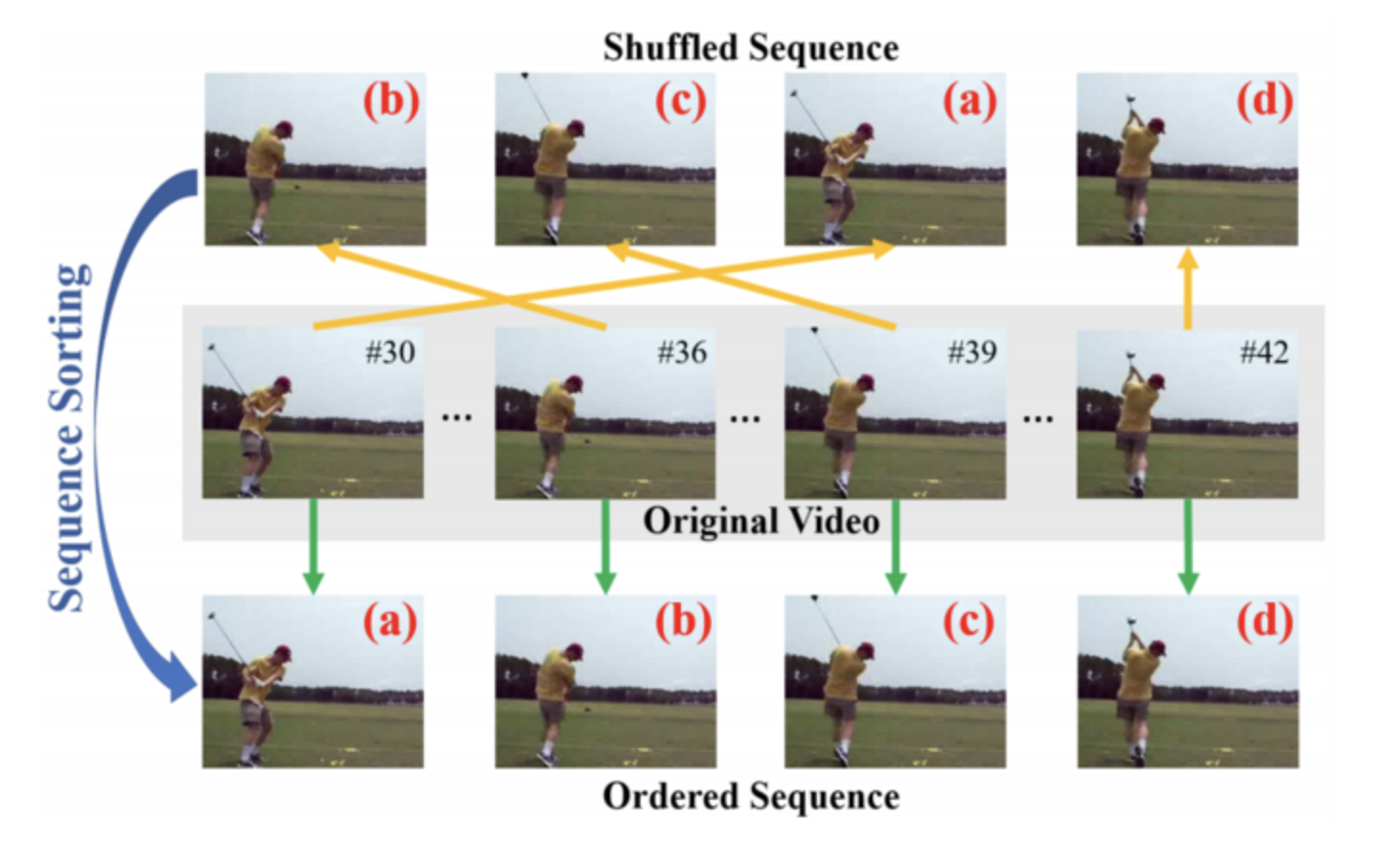
In Computer Vision, the implementation is slightly different. We still need to train a model in a self-supervised way using a “context task”, with the idea to focus on a “downstream task”. Several pretext tasks can be used, such as colorization, placing images in patches, placing frames in the right order… For videos, for example, a common workflow is to train a model on one or multiple pretext tasks with unlabelled videos and then feed one intermediate feature layer of this model to fine-tune a simple model on downstream tasks of action classification, segmentation, or object tracking.
Self-supervised training can allow you to use 1000x less training data for a given downstream task.
wav2vec is used as an input to an acoustic model. The vector supposedly carries more representation information than other types of features. It can be used as an input in a phoneme or grapheme-based wav2letter ASR model. The model then predicts the probabilities over 39-dimensional phoneme or 31-dimensional graphemes.
Regarding the language model decoding, the authors considered a 4-gram language model, a word-based convolutional language model, and a character-based convolutional language model. Word sequences are decoded using beam-search.
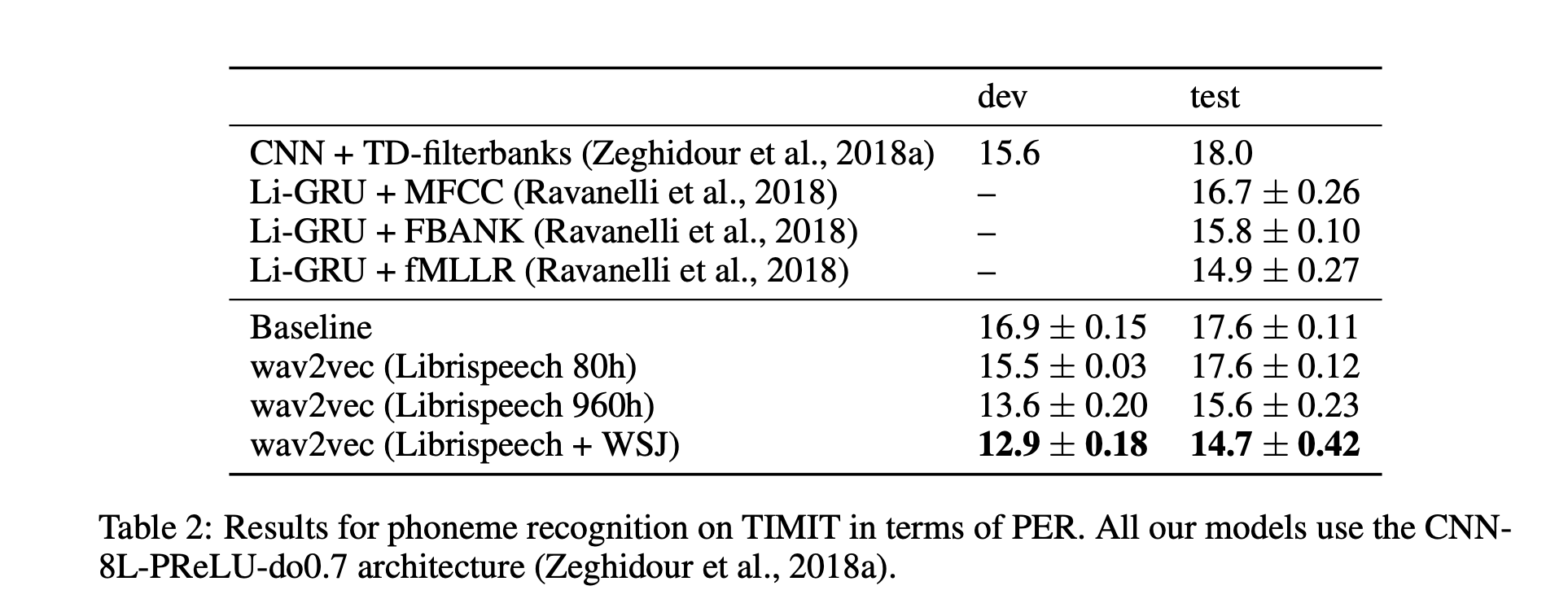
Pre-training reduces WER by 36 % on nov92 when only about eight hours of transcribed data is available. It also improved the PER on the TIMIT database compared to a baseline system, and the more pre-training data, the better the results were (Librispeech + WSJ in their best system). Results on TIMIT are presented in the table below.
vq-wav2vec introduces self-supervised learning of discrete speech representations. What we mean by discrete here is that we do not have vectors that take continuous values, but a set of given values only. Discretization, rather than enables the direct application of algorithms from the NLP community which require discrete inputs. In other words, vq-wav2vec, learns vector quantized (VQ) representations of audio data using a future time-step prediction task.
The model is said to word on discrete speech representations since it adds an additional layer of quantization.
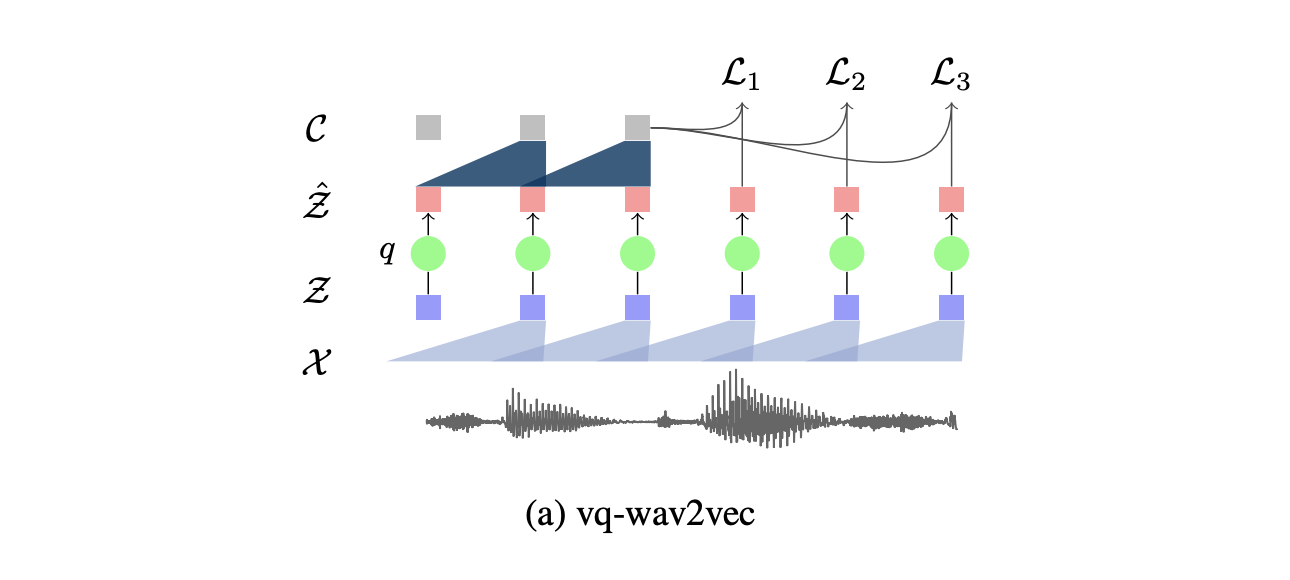
This additional layer \(q : Z \to \tilde{Z}\) that takes \(Z\), a dense representation learned by the first CNN, and outputs a discrete representation, using either K-means clustering or the Gumbel-Softmax as constraints in a Vector Quantized Variational Autoencoders.
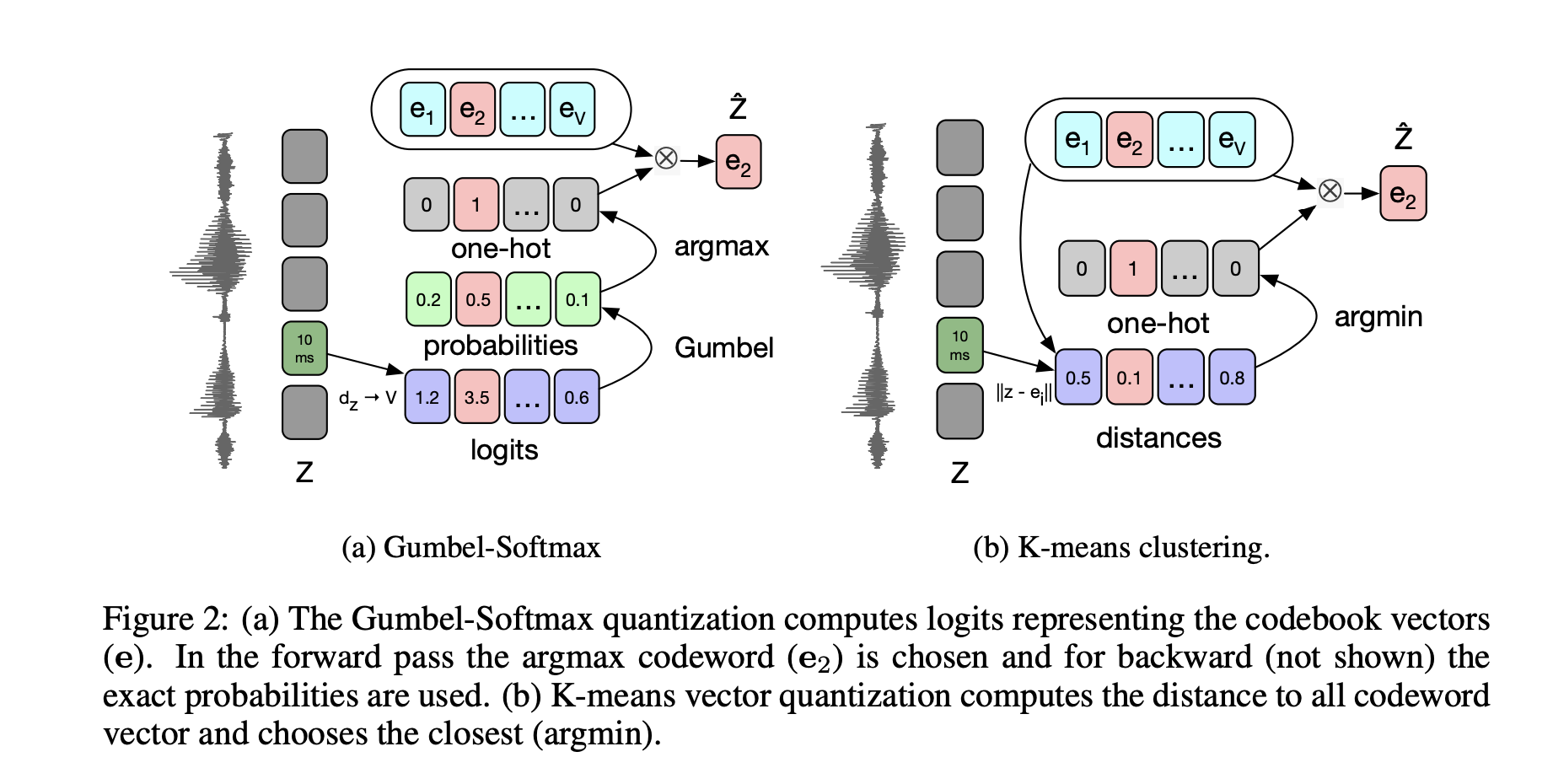
Finally, this discrete representation is fed as an input to the context network \(g : \tilde{Z} \to C\).
The discrete speech representation is then fed to train a BERT architecture. BERT is a pre-training approach for NLP tasks, which uses a transformer encoder model to build a representation of text. Transformers use self-attention to encode the input sequence as well as an optional source sequence.
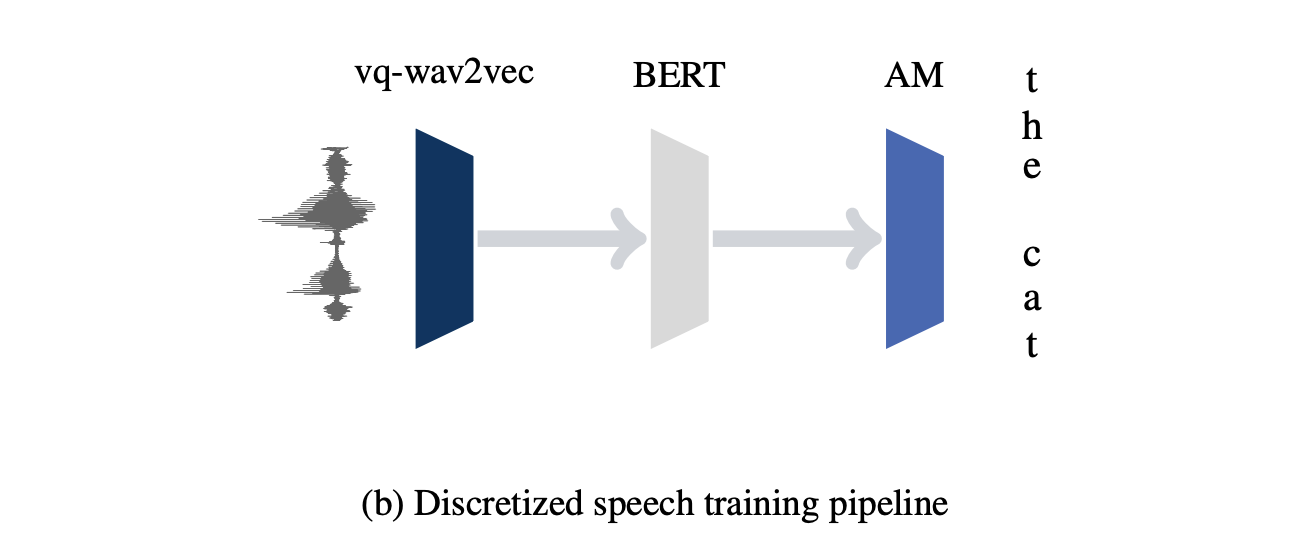
In prediction, we fetch speech representations that are used as inputs to an acoustic model.
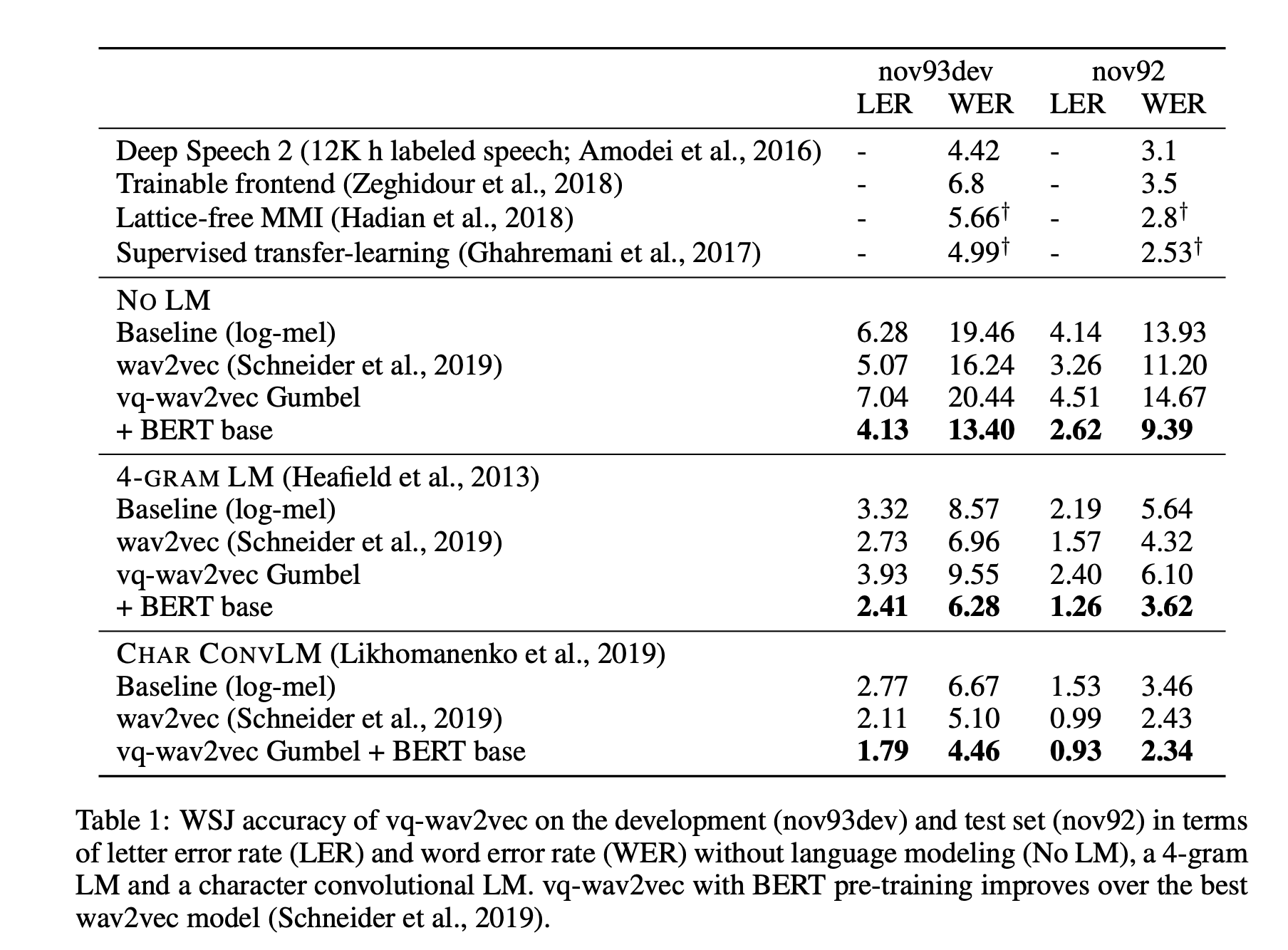
Authors used wav2letter as an acoustic model and trained for 1,000 epochs on 8 GPUs for both TIMIT and WSJ. Language models used were a 4-gram KenLM language model and a character-based convolutional language model.
Results on the character-based convolution language model and a Gumbel + Bert base vq-wav2vec reach state-of-the-art on the WSJ dataset.
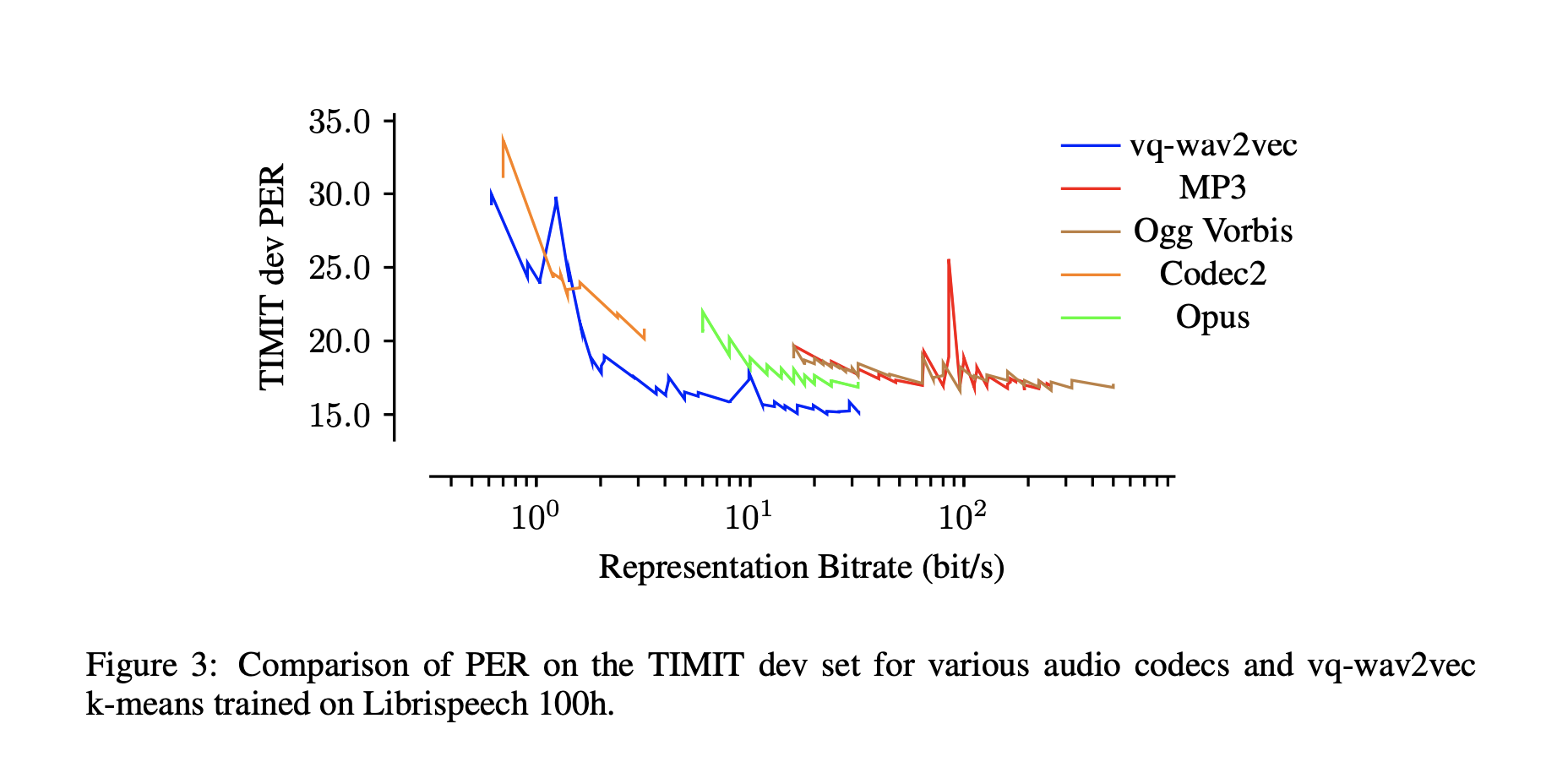
Another important contribution of this paper is that, by exploring quantization, highly reduces the bitrate for a given model performance. Acoustic models on vq-wav2vec achieve the best results across most bitrate settings.
One last important work, although results were not that good, is the sequence-to-sequence model that authors explain in a small paragraph. Rather than training BERT on discretized speech, and inputting it in the acoustic model, one could solve speech recognition as an end-to-end task.
This is solved by taking the discrete speech representation as an input to a Transformer architecture. Hence, no acoustic model is required. No language model or data augmentation was used, which might explain the limited results. But this work is an important step towards what the next papers of this series explore.
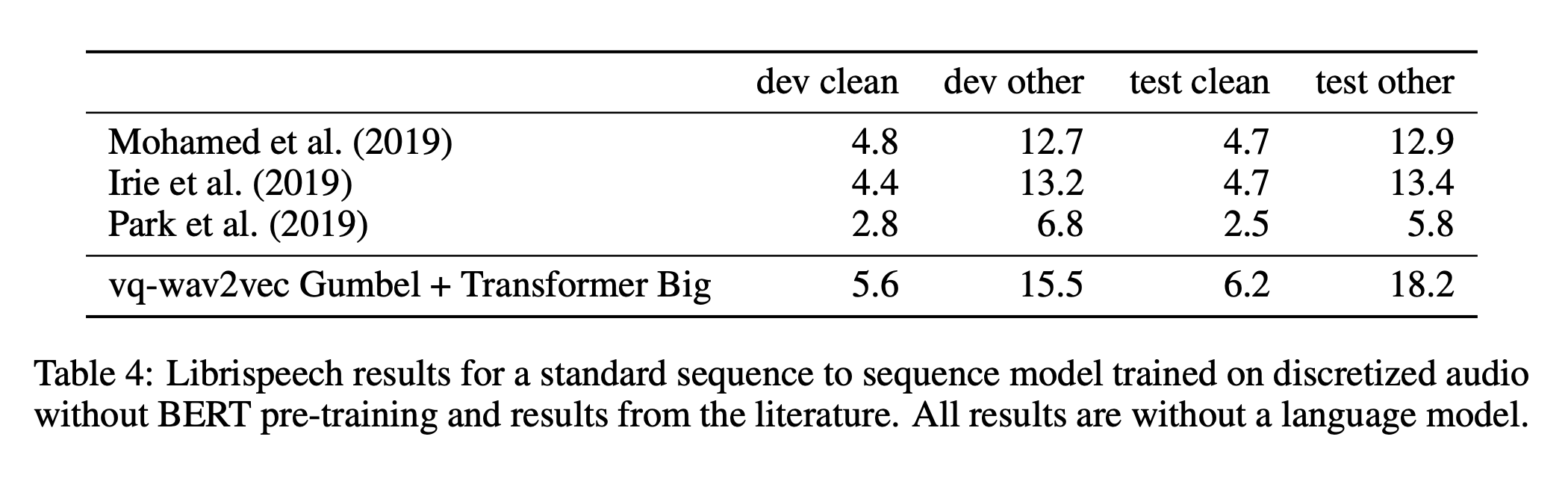
wav2vec 2.0 leverages self-supervised training, like vq-wav2vec, but in a continuous framework from raw audio data. It builds context representations over continuous speech representations and self-attention captures dependencies over the entire sequence of latent representations end-to-end.
Inspired by the end-to-end version of the vq-wav2vec paper, the authors further explored this idea with a novel model architecture:
The model architecture is summarized below:
As you might have seen, the loss depends on 2 components:
The overall loss is defined by :
\[L = L_m + \alpha L_d\]The authors added a randomly initialized linear projection on top of the context network (transformer) into \(C\) classes representing the vocabulary of the task. For Librispeech, we have 29 tokens for character targets plus a word boundary token. Models are optimized by minimizing a CTC loss.
2 types of language models were considered:
Beam search decoding was used.
If a pre-trained model captures the structure of speech, then it should require few labeled examples to fine-tune it for speech recognition.
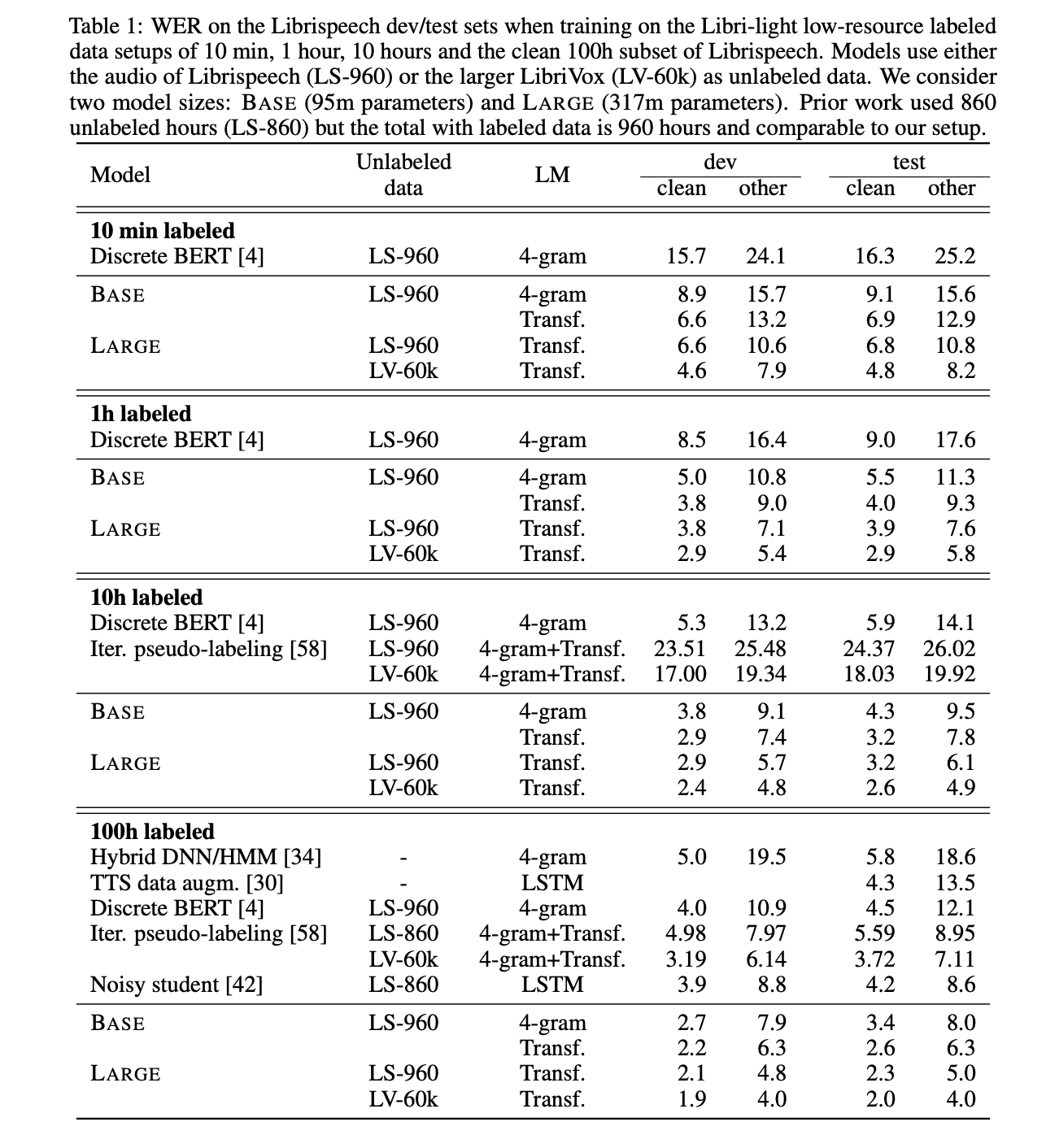
The LARGE model pre-trained on LibriVox (LV-60k) and fine-tuned on only 10 minutes of labeled data achieves a word error rate of 5.2/8.6 on the Librispeech clean/other test sets. This is definitely a major milestone in speech recognition for ultra-low resource language. This demonstrates that ultra-low resource speech recognition is possible with self-supervised learning on unlabeled data
Of course, the more labeled data is processed for fine-tuning, the better the model performance.
But what happens when lots of training data are available? Does it beat SOTA?
The ten-minute models without lexicon and language model tend to spell words phonetically and omit repeated letters, e.g., will → wil. Spelling errors decrease with more labeled data.
When even more training data are available, e.g. the whole of Librispeech, the architecture reaches SOTA results.
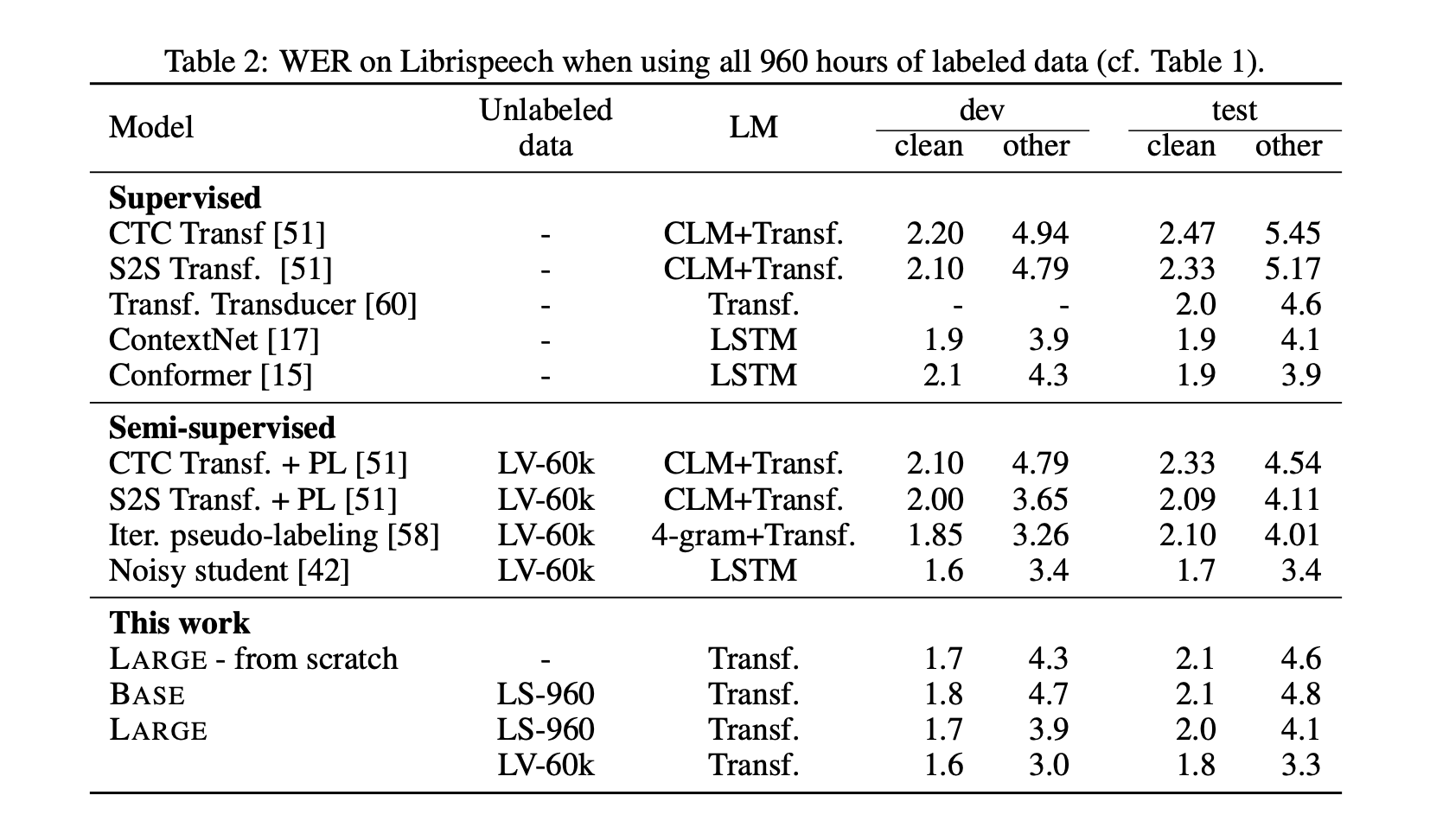
Finally, the authors mention that self-training is likely complimentary to pre-training and their combination may yield even better results. However, it is not clear whether they learn similar patterns or if they can be effectively combined.
This last work combines both self-supervised training and pre-training for speech recognition. It gained a lot of attention lately, especially on Twitter with this headline that just 10 minutes of labeled speech can reach the same WER than a recent system trained on 960 hours of data, from just a year ago.
Great progress in speech recognition: wav2vec 2.0 pre-training + self-training with just 10 minutes of labeled data rivals the best published systems trained on 960 hours of labeled data from just a year ago.
— Michael Auli (@MichaelAuli) October 26, 2020
Paper: https://t.co/niBzDiei1j
Models: https://t.co/frCK1GJMZQ pic.twitter.com/AjEWdna6J1
In their paper, the authors explore the complementarity of self-training and pre-training.
The pre-training approach adopted so far relied on self-supervised learning. This whole block will now be referred to as unsupervised pre-training. This paper introduces the notion of self-training.
In self-training, we train an initial acoustic model on the available labeled data and then label the unlabeled data with the initial model as well as a language model in a step we call pseudo-labeling. Finally, a new acoustic model is trained on the pseudo-labeled data as well as the original labeled data.
Self-training and pre-training are then mixed in the following way:
For the self-training part,
The final model trains a Transformer-based sequence to sequence model with log-Mel filterbank inputs after pseudo-labeling using wav2letter++. It uses a 10k word piece output vocabulary computed from the training transcriptions if the whole Librispeech training set is used as labeled data.
Results achieved on only 10 minutes of data are even better than wav2vec 2.0.

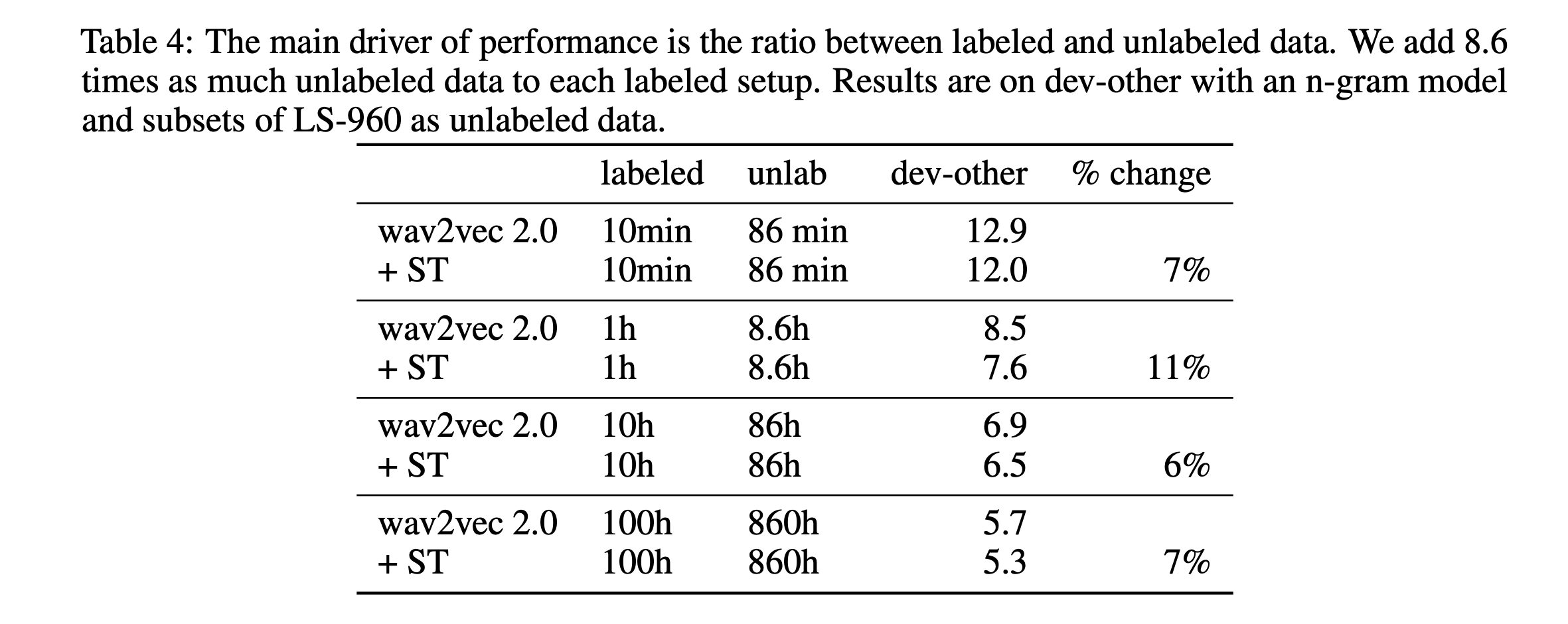
Finally, the authors explore to what extent self-training and pre-training are complementary. According to the table below, it appears when respecting a ratio of 8.6 times more unlabeled speech that labeled one, self-training keeps improving results by more than 7% on average.
Luckily, Patrick Von Platen, research engineer at Hugging Face, let a comment below, and guess what… Wav2Vec2 is in Hugging Face Transformer’s library!
Here is the link to the PR. And if you want to have access to a Wav2Vec2 model, pre-trained on LibriSpeech, it’s as easy as:
pip install git+https://github.com/huggingface/transformers
And then:
import librosa
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Tokenizer
import nltk
def load_model():
tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
return tokenizer, model
def correct_sentence(input_text):
sentences = nltk.sent_tokenize(input_text)
return (' '.join([s.replace(s[0],s[0].capitalize(),1) for s in sentences]))
def asr_transcript(input_file):
tokenizer, model = load_model()
speech, fs = sf.read(input_file)
if len(speech.shape) > 1:
speech = speech[:,0] + speech[:,1]
if fs != 16000:
speech = librosa.resample(speech, fs, 16000)
input_values = tokenizer(speech, return_tensors="pt").input_values
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = tokenizer.decode(predicted_ids[0])
return correct_sentence(transcription.lower())
Thanks a lot to Hugging Face for such an easy implementation. Next features will probably include training of such models, and that’s an exciting move towards speech for Hugging Face!
We have seen in this article:
initial self-supervised learning
Well, this is an open research question. I am really interested in exploring this. This is what I have currently found:
Speech representations can be used for several downstream tasks. I am rather convinced that it is a matter of time before these representations, learned from raw waveforms, approach SOTA or even beat it on other tasks such as speaker identification, voice activity detection, language identification, pathological speech detection… I see it as a very powerful tool.
I hope this wav2vec series summary was useful. Feel free to leave a comment
All references:
]]>I am keeping track here of my Ph.D. process. I don’t know if it will be of any interest for readers however.
Started to work on my candidacy exam and research plan proposal for EPFL.
BertAA paper was accepted at ICON 2020 as a long paper! And the paper on auto-encoders for dialect identification too.
TIM 2020 gets canceled due to COVID. BertAA paper was rejected from CoNLL2020. Worked on a new version, and submitted it to ICON 2020. Co-authoring a paper on dialect identification using auto-encoders, submitted to ICON 2020 too.
Accepted workshop to describe the use of speech processing criminal investigations at TIM 2020 (Traitement de l'Information Multimodale). Re-submission of Graph2Speak at ICASSP 2020.
Participated and won the International Create Challenge organized at Idiap with an assistive device to guide blind and visually impaired people, named SoundMap.
Submitted paper was rejected from Interspeech 2020. Working on a re-submission for ICASSP. Submitting BertAA, a second paper to CoNLL 2020 on Authorship Attribution.
Finished the EPFL class: Statistical Sequence Processing with some work presented on EM for Gaussian Mixture Models and Hidden Markov Models training.
First paper submitted to Interspeech 2020: Graph2Speak, Improving Speaker Identification using Network Knowledge in Criminal Conversational Data.
COVID-19 strikes, working from home on data processing and speaker identification.
Starting my Ph.D. at Idiap Research Institute, as an EPFL Student.
In the world, more than 6’000 languages exist, 3’000 of them currently being endangered. In Europe, 24 official languages are spoken. Google Cloud Speech API covers 60 languages and 50 accents/dialects, and Siri covers 20 languages and 20 accents/dialects.
Many of the low-resourced languages have:
There are several steps to manage and under-resources language:
We can use NN hidden layers to learn a multilingual representation, shared between languages, and add an output layer for monolingual language specific.
There are several ways to do this:
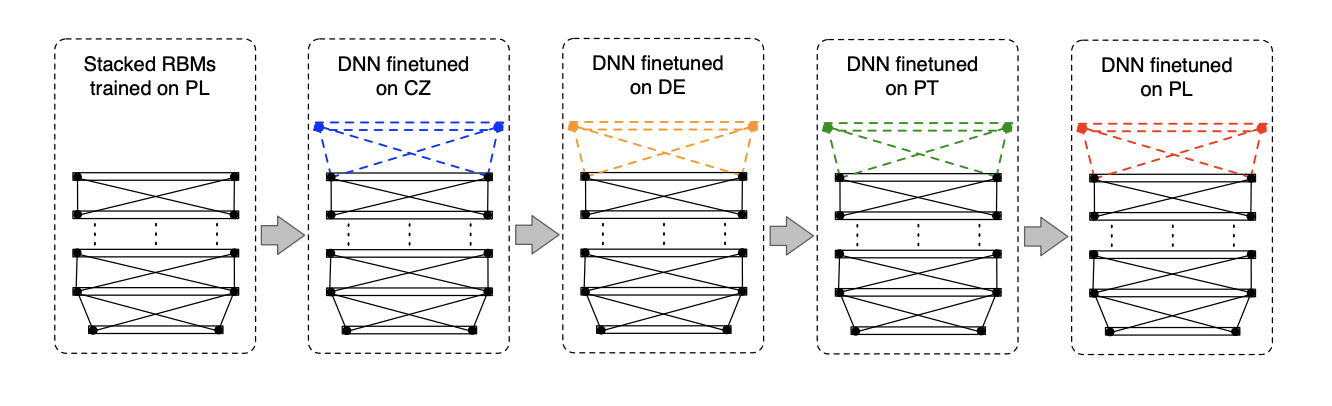
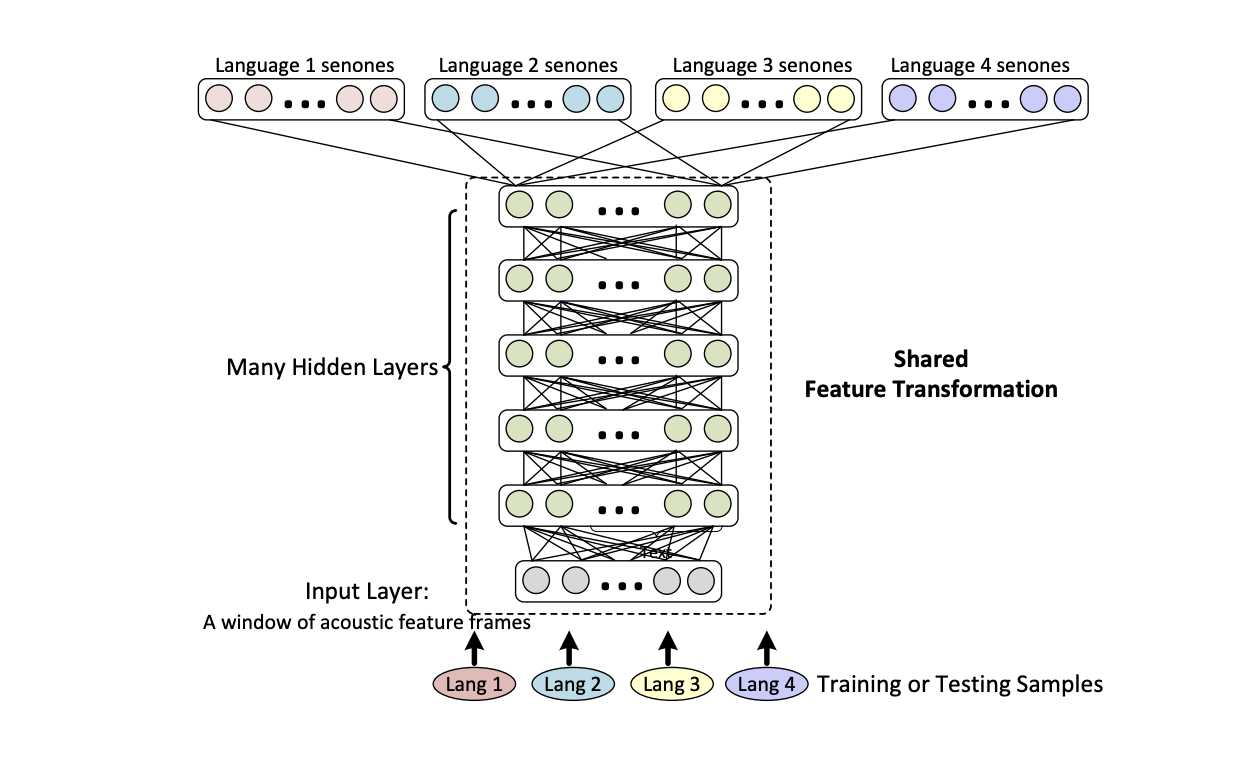
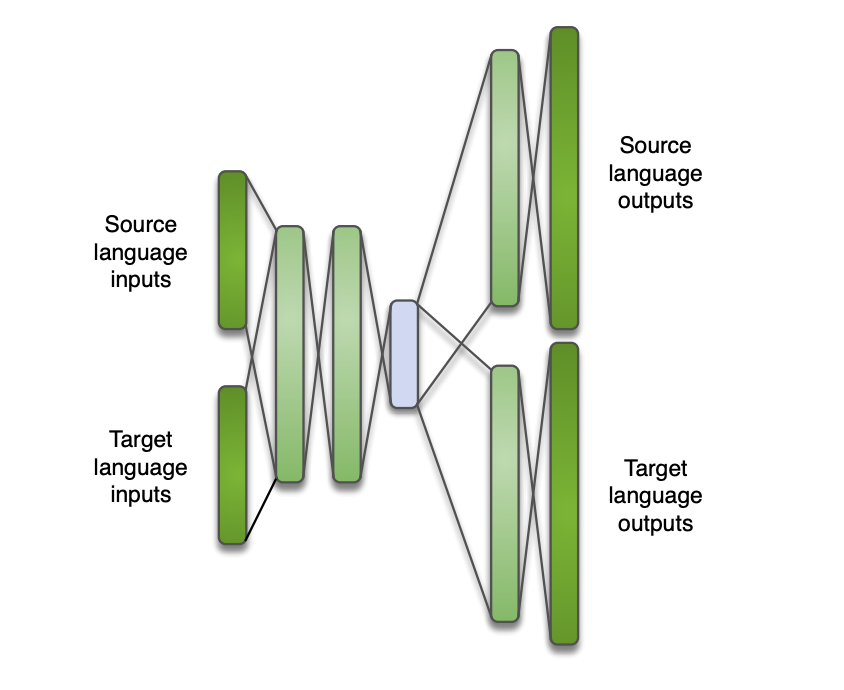
A way to overcome lacks of phone-based pronunciations is to use graphemes (letters) rather than phones. The only problem is that there is not always a direct link between graphemes and sounds, for example in English.
Many languages are harder than English, have larger vocabulary sizes, and:
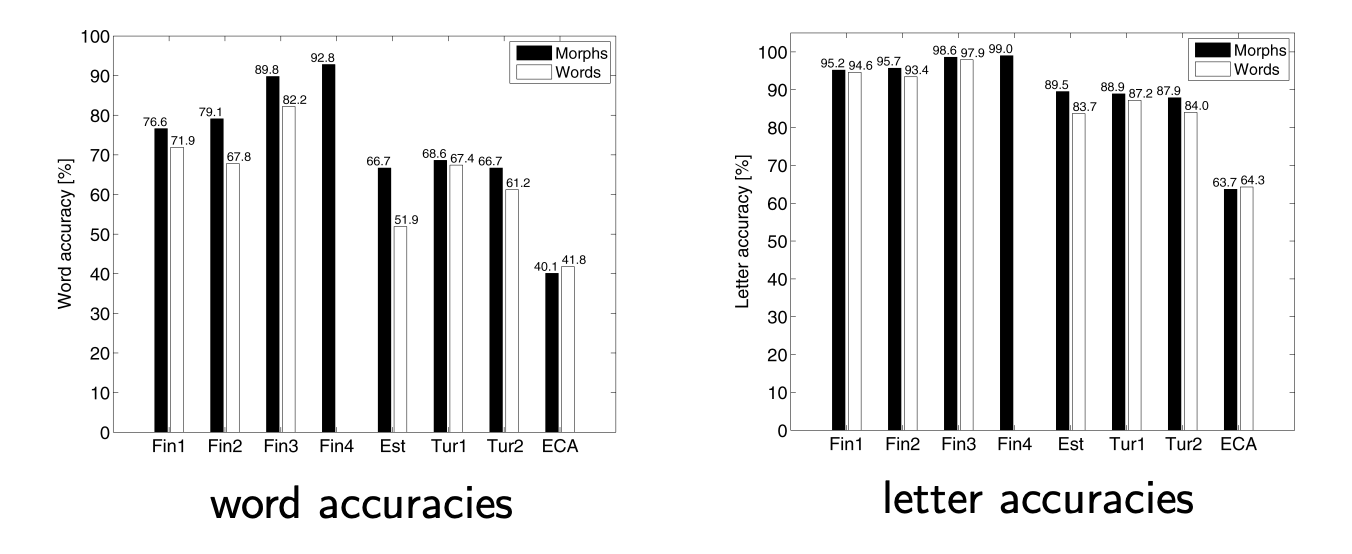
We can therefore model at the morph level in order to reduce the Out-Of-Vocabulary rate (OOV).
Segmenting speech and text into morphs requires a lot of linguistic work. However, some automatic approaches try to cluster words (wuch as Morfessor) based on the frequency of sub-strings of letters in a word list. It may however require larger context.
If you want to improve this article or have a question, feel free to leave a comment below :)
References:
]]>When training an ASR system, mismatch can occur between training and test data, due to various sources of variation. Speaker adaptation can help fill this gap.
Lots of speaker-specific variations exist in the acoustic model:
There are also variations not related to the speaker itself, but to the channel (telephone, distance to microphone, reverberation…).
Each speaker has a specific way to pronounce some words.
Test data might be related to a specific topic, or to user-specific documents. The language model should then be adapted.
To handle all of these potential variations, we perform speaker adaptation. The aim is to reduce the mismatch between test data and trained models.
ASR Systems can be said to be:
Adaptation can be:
It can also be:
Finally, we want SA to be:
We can adapt the parameters of acoustic models to better match the observed data, using:
MAP training will balance the estimated parameters of the Speaker Independent data and the new adaptation data.
Using Maximum Likelihood Estimate (MLE) os Speaker Independent model, the mth Gaussian in the jth state has the following mean:
\[\mu_{mj} = \frac{\sum_n \gamma_{jm}(n) x_n}{\sum_n \gamma_{jm}(n)}\]Where \(\gamma_{jm}\) is the component occupation probability. The aim of a MLE is to maximize: \(P(X \mid \lambda)\) where \(\lambda\) are the model parameters.
The MAP estimate of the adapted model uses the Speaker Independent models as a prior probability distribution over model parameters to estimate speaker-specific data. MAP training maximizes: \(P(\lambda \mid X) ∝ P(X \mid \lambda) P_0(\lambda)\)
It gives a new mean:
\[\hat{\mu} = \frac{ \tau \mu_0 + \sum_n \gamma(n)x_n} {\tau + \sum_n \gamma(n)}\]Where:
As the amount of training data increases, the MAP estimate converges to the ML one.
One of the issues with MAP is that with few adaptation data, most Gaussians will not be adapted. If instead we share the adaptation across the Gaussians, each adaptation data can affect many of, or all, the Gaussians.
As its name suggests, MLLR will apply a linear transformation on the Gaussian parameters estimated by MLE:
\[\hat{\mu} = A \mu + b\]Hence, if the observations have \(d\) -dimensions, then A is \(d \times d\) and b has \(d\) dimensions.
It can be re-written as:
\[\hat{\mu} = W \eta\]Where:
We then estimate \(W\) to maximize the MLE on the adaptation data. Such transformations can then be applied to all classes, or to a set of Gaussian sharing a transform, called a regression class.
We must then determine the number of regression classes. This is usually small (1, 2 (speech / non-speech), one per broad class, one per context-independent phone class…). We can obtain the number of regression classes by building a regression class tree, in a similar manner to a clustering tree.
As usual in MLE, we maximize the log-likelihood (LL), which turns out to be easier to solve. The LL is defined as:
\[L = \sum_r \sum_n \gamms_r(n) \log (K_r \exp(-\frac{1}{2}(x_n - W \eta_r)^T \Sigma_r^{-1} (x_n - W \eta_r)))\]Where \(r\) defines the different regression classes. Note that there is bi closed form solution if \(\sigma\) is a full covariance matrix, and it can be solved if \(\sigma\) is diagonal.
We apply the mean-only MLLR, by adapting only the mean, and it usually improves WER by 10-15% (relative). 1 minute of adaptation speech is more or less equal, in terms of model performance, to 30 minutes of speech in speaker dependent models.
In constrained MLLR (cMLLR), we use the the same linear transform for both the mean and the covariance. This is also called feature space MLLR (fMLLR), since it’s equivalent to applying a linear transform to the data:
\[\hat{\mu} = A^{'} \mu - b^{'}\] \[\hat{\Sigma} = A^{'} \Sigma A^{'}^T\]There are no closed form solution, this is solved iteratively.
In SAT, we adapt the base models to the training speaker while training, using MLLR or fMLLR for each training speaker. It results in higher training likelihoods and improved recognition results, but increases the complexity and the storage requirements. SAT can be seen as a type of speaker normalization at training time.
We can use the HMM/GMM system that we train to estimate the tied state, to also estimate a single cMLLR transform for a given speaker. We then use this to transform the input speech of the DNN for the target speaker.
In a Linear Input Network (LIN), a single linear input layer is trained to map input speaker-dependent speech to speaker independent network.
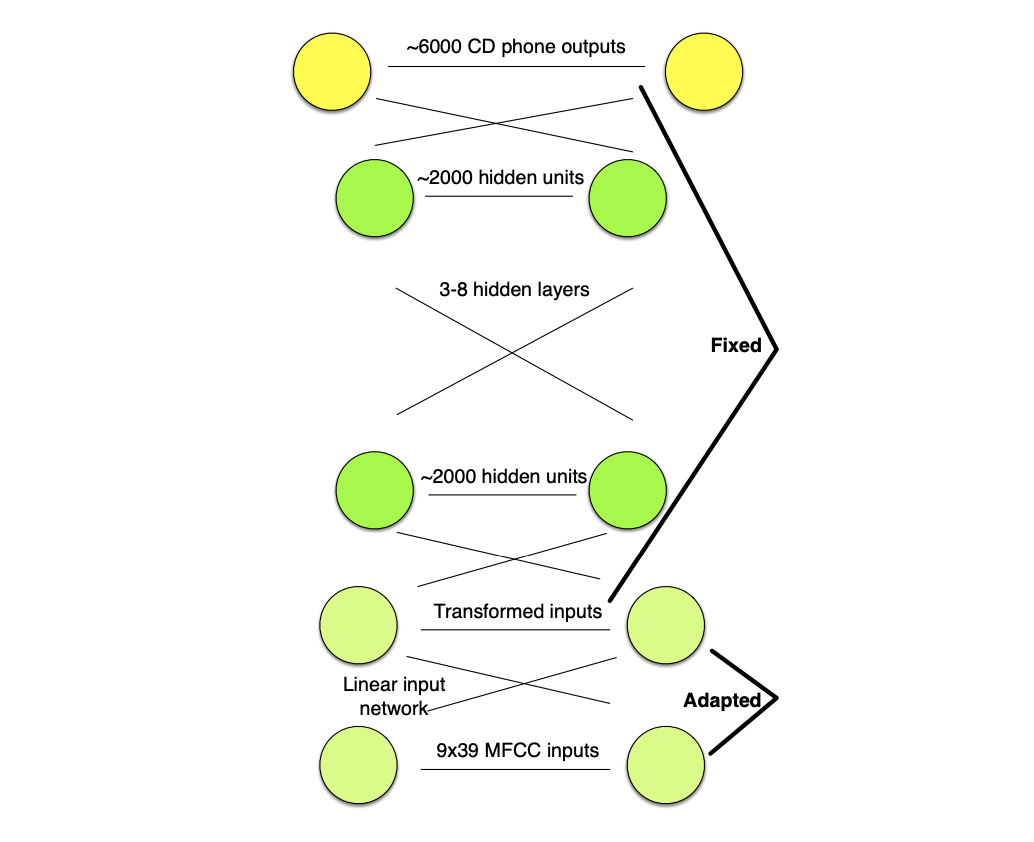
In training, the LIN is fixed and in testing, the main speaker-independent network is fixed.
We can also learn a short speaker code vector for talker, and combine that with the input feature vector, to compute transformed features. This allows an adaptation on speaker specific means.
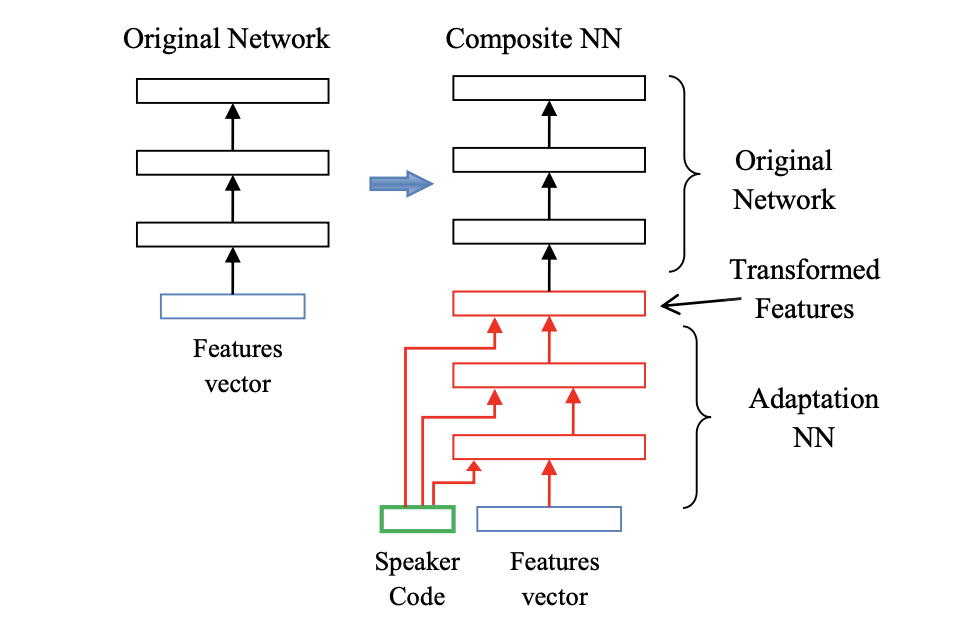
i-vectors are used as speaker codes. i-vectors are fixed-dimensional representations \(\lambda_s\) for a speaker \(s\). They model the difference between the means trained on all data \(\mu_0\) and the speaker specific means \(\mu_s\):
\[ \mu_s = \mu_0 + M \lambda_S\]i-vectors are derived from a factor analysis, and widely used in speaker identification.
In LHUC, we add a learnable speaker dependent amplitude to each hidden unit, which allows us to learn amplitudes from data, per speaker, and it “embeds” in a sense the adaptation part.
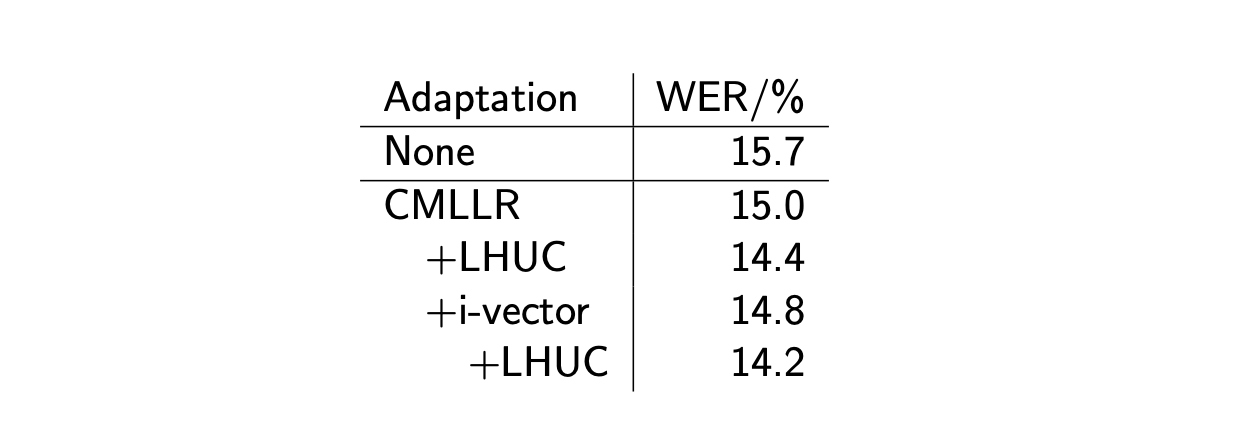
Below are the results, in terms of WER, of various adaptation methods, and their combinations.
If you want to improve this article or have a question, feel free to leave a comment below :)
References:
]]>So far, we considered the HMM training under the Maximum Likelihood Estimate (MLE). But the MLE is only optimal under certain model correctness assumptions: Observations should be conditionally independent given the hidden state, which is not the case if states are phone based for example.
The MLE identifies the best set of parameters to maximize the objective function:
\[F_{MLE} = \sum_{u=1}^U \log P_{\lambda}(X_u \mid M(W_u))\]Where:
Then, in an HMM-GMM for example, we define the mean vector \(\mu_{jm}\) for the mth Gaussian component in the jth state as:
\[\hat{\mu_{jm}} = \frac{\sum_u \sum_t \gamma_{jm}^u(t) x_t^u}{\sum_u \sum_t \gamma_{jm}^u(t)}\]Where \(\gamma_{jm}^u(t)\) is the probability of being in mixture m at state j at time t given training sentence u.
Before introducing discriminative training, let us introduce 2 additional pieces of notation:
\[\Theta_{jm}^u(M) = \sum_t \gamma_{jm}^u(t) x_t^u\] \[\Gamma_{jm}^u(M) = \sum_t \gamma_{jm}^u(t)\]Therefore, we can re-write the mean vector as:
\[\hat{\mu_{jm}} = \frac{\sum_u \Theta_{jm}^u(M(W_u)) }{\sum_u \Gamma_{jm}^u(M(W_u)) }\]This sections applies for HMM-GMM architectures.
The MMIE aims to directly maximize the posterior probability.
\[F_{MMIE} = \sum_u \log P_{\lambda}(M(W_u) \mid X_u)\]We can then decompose it into an acoustic and a language model:
\[F_{\mathrm{MMIE}}=\sum_{u=1}^{U} \log \frac{P_{\lambda}\left(\mathbf{X}_{u} \mid M\left(W_{u}\right)\right) P\left(W_{u}\right)}{\sum_{W^{\prime}} P_{\lambda}\left(\mathbf{X}_{u} \mid M\left(W^{\prime}\right)\right) P\left(W^{\prime}\right)}\]What this ratio represents is the likelihood of data given correct word sequence divided by the total likelihood of data given all possible word sequences.
We optimise \(F_{MMIE}\) by making the correct word sequence likely (numerator goes up), and the other word sequences unlikely (denominators goes down).
The optimization is done using an Extended Baum-Welch algorithm (EBW), and the new mean update equation is given by:
\[\hat{\mu}_{j m}=\frac{\sum_{u=1}^{U}\left[\Theta_{j m}^{u}\left(\mathcal{M}_{\mathrm{num}}\right)-\Theta_{j m}^{u}\left(\mathcal{M}_{\mathrm{den}}\right)\right]+D \mu_{j m}}{\sum_{u=1}^{U}\left[\Gamma_{j m}^{u}\left(\mathcal{M}_{\mathrm{num}}\right)-\Gamma_{j m}^{u}\left(\mathcal{M}_{\mathrm{den}}\right)\right]+D}\]To compute the denominator in the \(F_{MMIE}\), we must sum over all possible word sequences, which is hard. The idea of using lattices is to estimate the denominator by generating word lattices and summing over all words in the lattice. This way, we approximate the sum by a set of likely word sequences determined via a decoding run on the training data.
A word lattice is a directed acyclic graph with a single start point and edges labeled with a word and weight. It’s usually represented as a WFSTs, and allow you to only explore possible paths for word sequences rather than all combinations. Pruning in that WFST is also possible.
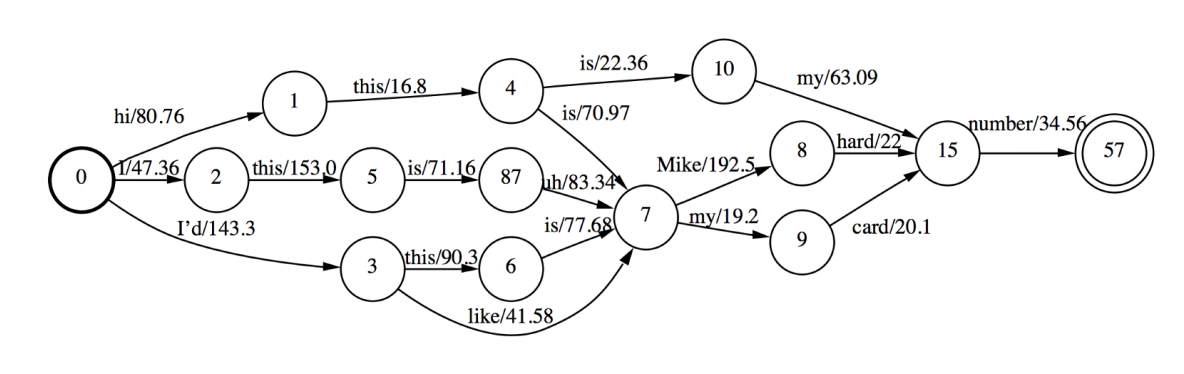
We can also adjust the optimization criterion so that it’s directly related to the Word Error Rate in a method called Minimum Phone Error.
The new criterion becomes:
\[F_{\mathrm{MPE}}=\sum_{u=1}^{U} \log \frac{\sum_{W} P_{\lambda}\left(\mathbf{X}_{u} \mid \mathcal{M}(W)\right) P(W) A\left(W, W_{u}\right)}{\sum_{W^{\prime}} P_{\lambda}\left(\mathbf{X}_{u} \mid \mathcal{M}\left(W^{\prime}\right)\right) P\left(W^{\prime}\right)}\]Where \(A(W, W_u)\) is the phone transcription accuracy of the sentence \(W\) given reference \(W_u\).
It’s a weighted average over all possible sentences \(w\) of the raw phone accuracy, and finds probable sentences with low phone error rates.
So far, we saw what could be applied for HMM-GMM architectures. DNNs are trained in a discriminative manner, since the cross entropy (CE) with a softmax pushes the correct label and pulls down the competing labels. But can we train DNN systems with an MMI objective function?
Yes, we can, and this is usually done the following way:
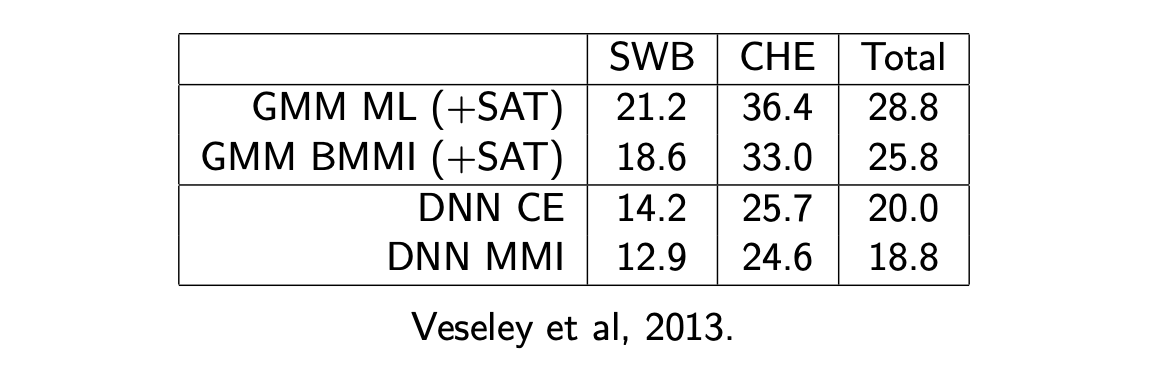
The results of various approaches on the Switchboard dataset are presented below:
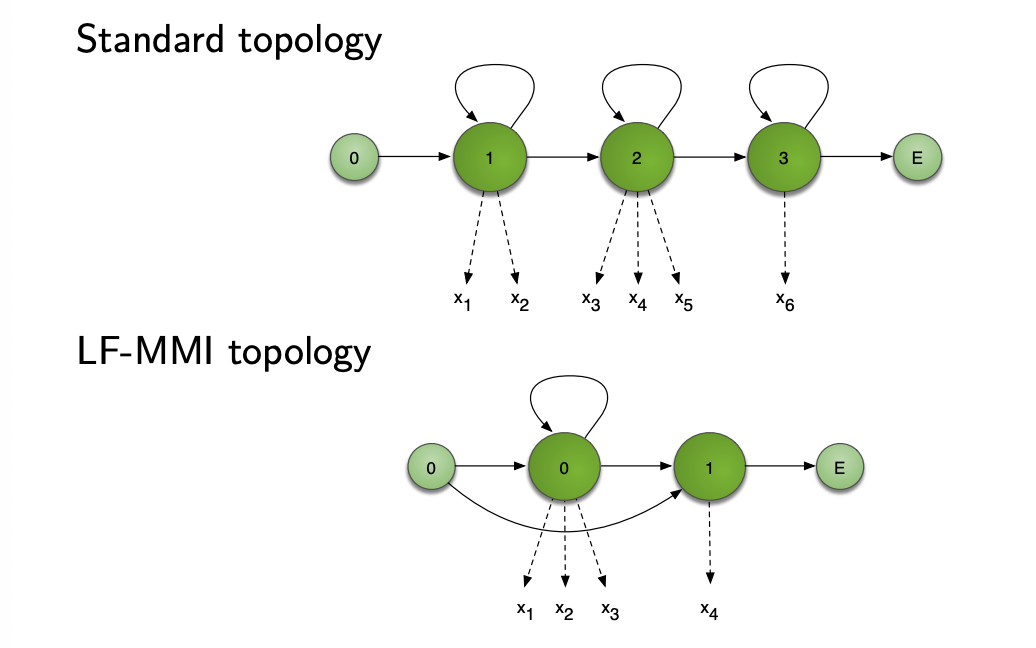
The aim of Lattice-Free MMI is to avoid the need to pre-compute lattices for the denominator, and the need to train using frame-based Cross Entropy before sequence training.
Lattice-free MMI is basically made of a few tips:
Regularisation is also used, by using standard CE objective as a secondary task. All layers but the final are then shared between tasks.
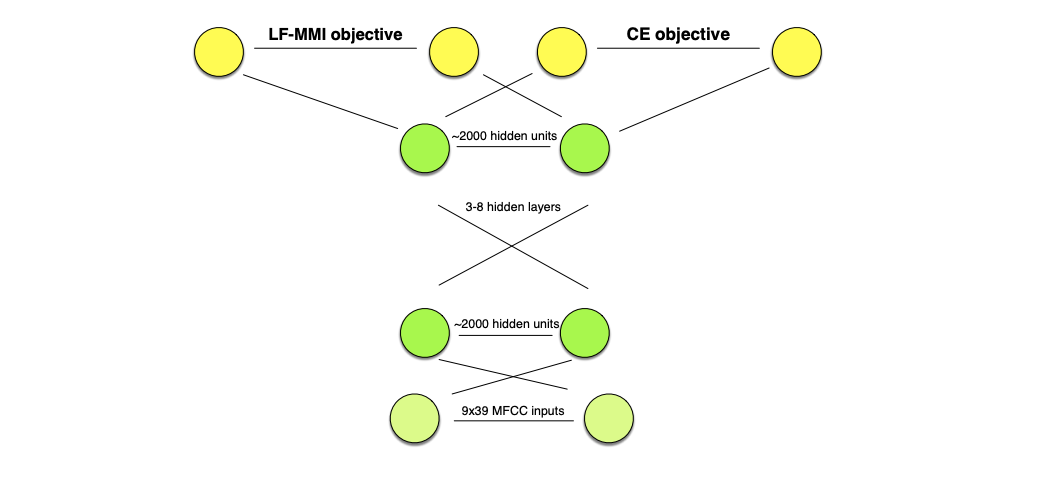
We also apply L2 regularisation on the main output.
LF-MMI is faster to train and decode and achieves better WER. It however performs worse when training transcripts are unreliable.
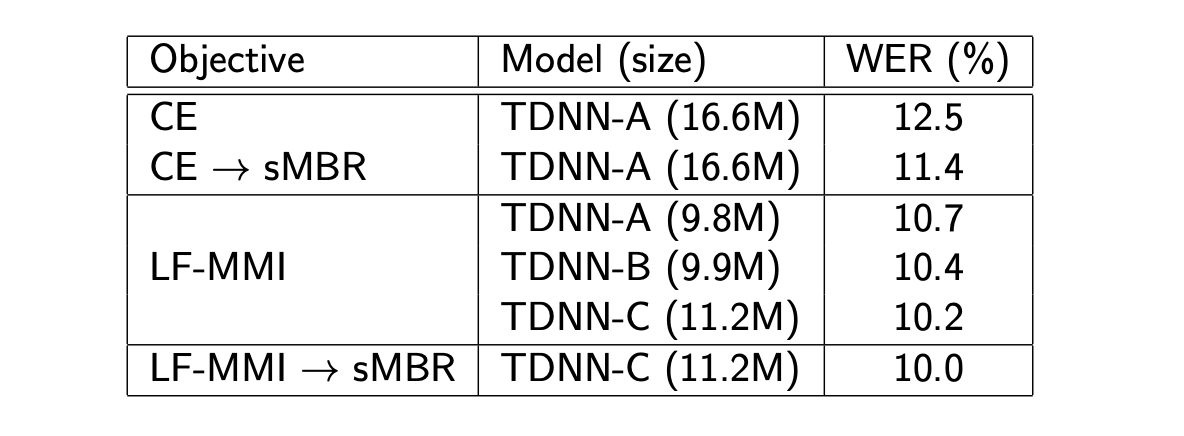
As a summary, we usually intialise sequence discriminative training:
But LF-MMI seems to bring current SOTA and lower computational costs.
If you want to improve this article or have a question, feel free to leave a comment below :)
References:
]]>So far, we have covered HMM-GMM acoustic modeling and some practical issues related to context and less frequent phonemes.
There is an alternative way to build an acoustic model, and it consists in using neural networks to:
Let’s consider a single-layer neural network, that takes as an input an acoustic frame \(X_t\) and outputs phonetic scores \(f(t)\) (one score for each phone).
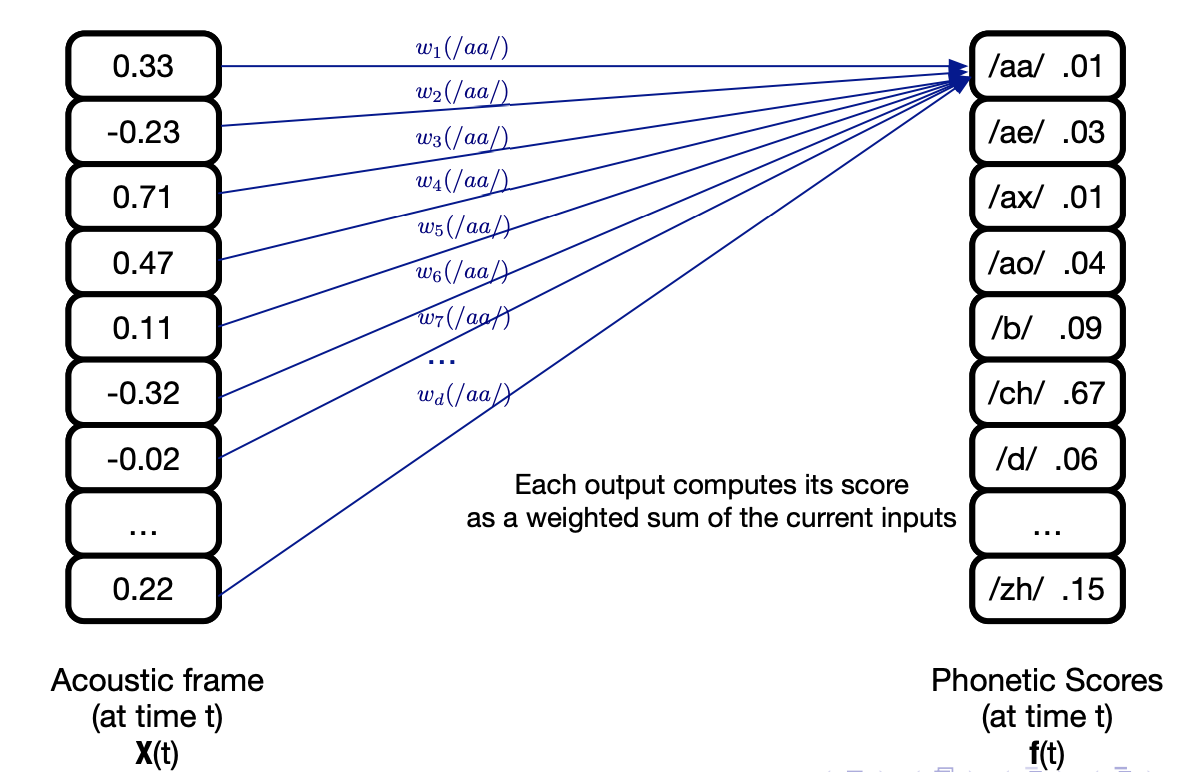
It can be expressed as:
\[f = Wx + b\]Where \(W\) is the weight matrix made of weights \(w_{ij}\) that reflect the weifht between input \(i\) and output \(j\), and \(b\) is the bias term.
How do we learn the parameters \(W\) and \(b\)? We target the minimization of the error function \(E\), the Mean Square Error (MSE) between the output and the target:
\[E = 0.5 \times \frac{1}{T} \sum_{t=1}^T {\mid \mid f(x_t) - r(t) \mid \mid}^2\]Where \(r(t)\) are the target outputs.
The error minimization is typically done using gradient descent, and we must compute the terms:
\(\frac{d E}{d W}\) and \(\frac{d E}{d b}\)
Reminder: Stochastic gradient descent (SGD)
In SGD, we:
The network that predicts phonetic scores is a classifier, so we need to take a softmax to force output values to act as probabilities:
\[y_j = \frac{exp(f(x_j))}{\sum_{k=1}^K exp(f(x_k))}\]Where \(f(x_j) = \sum_{d=1}^D w_{jd} x_d + b_j\)
However, the MSE is not the wisest choice when working with probabilities. We can directly maximize the log probability of observing the correct label using the Cross-Entropy (CE) error function:
\[E_t = - \sum{j=1}^J r_j^t \ln y_j^t\]Using CE, the gradients of the outputs weights simplify to:
\[\frac{dE^t}{dW_{jd}} = (y_j^t - r_j^t) x_d\]There are several extensions possible to this very very simple model:
This looks interesting, and overall simpler than the HMM-GMM. But there is a major limitation, since we cannot do speech recognition with this approach. There are several phone recognition tasks:
Using only DNN, we lack the notion of data segmentation that HMMs are good at doing. But can’t we mix HMMs and DNNs ?
In an HMM-GMM, replacing the GMM by a DNN to estimate output pdfs build a so-called HMM-DNN architecture. In a HMM-DNN, we consider one-state per phone, and train a NN as a phone-state classifier.
It can be shown that the outputs corresponding to class \(j\) given an input \(x_t\) are an estimate of the posterior probability \(P(q_t = j \mid x_t)\), \(q_t\) being a state, because we have softmax outputs and use a CE loss function.
And using Bayes Rule, we can relate the posterior \(P(q_t = j \mid x_t)\) to the likelihood \(P(x_t \mid q_t = j)\):
\[P(q_t \mid x_t) = \frac{P(x_t \mid q_t = j) P(q_t = j)}{P(X_t)}\]If we want HMM-DNNs to output probabilities, we should scale the likelihoods:
\[\frac{P(q_t = j \mid x_t)}{P(q_t = j)} = \frac{P(x_t \mid q_t = j)}{P(x_t)}\]This means we can obtain scaled likelihoods by dividing each network output by the prior, i.e. the relative frequency of class \(j\) in training data.
There are several approaches to continuous speech recognition with HMM-DNN:
The architecture of a HMM-DNN is presented below:
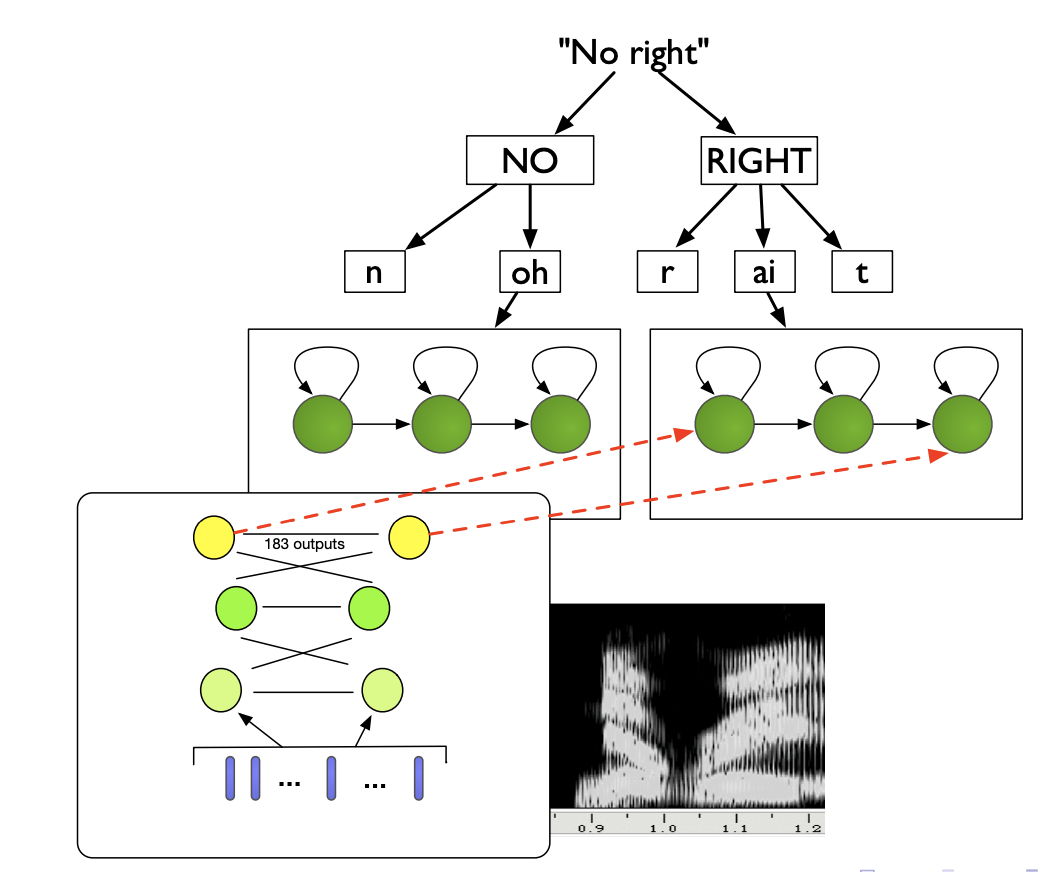
NN are more flexible, learn richer representations and handle correlated features. In terms of speech features, experiments indicate that mel-scaled filter bank features (FBANK) work better than MFCCs, and results in better clustering when applying t-SNE on the hidden layers. Indeed, in FBANK the useful information is distributed over all the features, whereas in MFCC it is concentrated in the first few.
Modling the phonetic context with DNNs was considered hard until 2011, but a simple solution emerged: use the state-tying process from a GMM system, and train a HMM-DNN on it.
More precisely, the context-dependent hybrid HMM/DNN approach is:
Concretely, we model the acoustic context by including neighbour frames in the input layer.
We use richer Neural Network models for acoustic context:
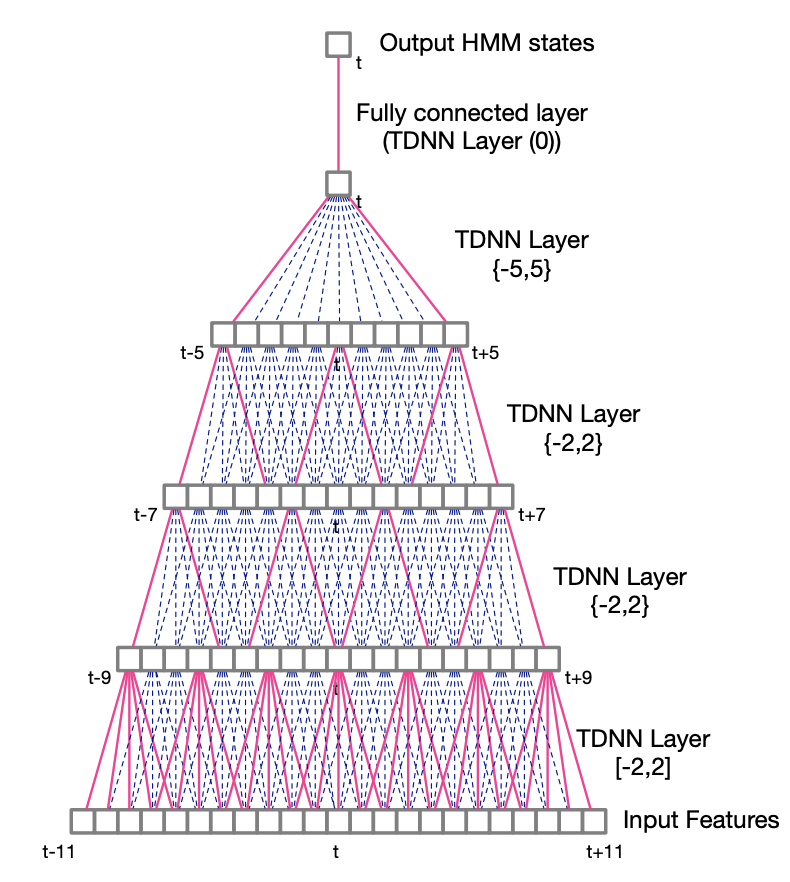
In TDNNs, higher hidden layers take input from a larger acoustic context, and lower hidden layers from narrower contexts. TDNNs can be seen as a 1D convolutional network.
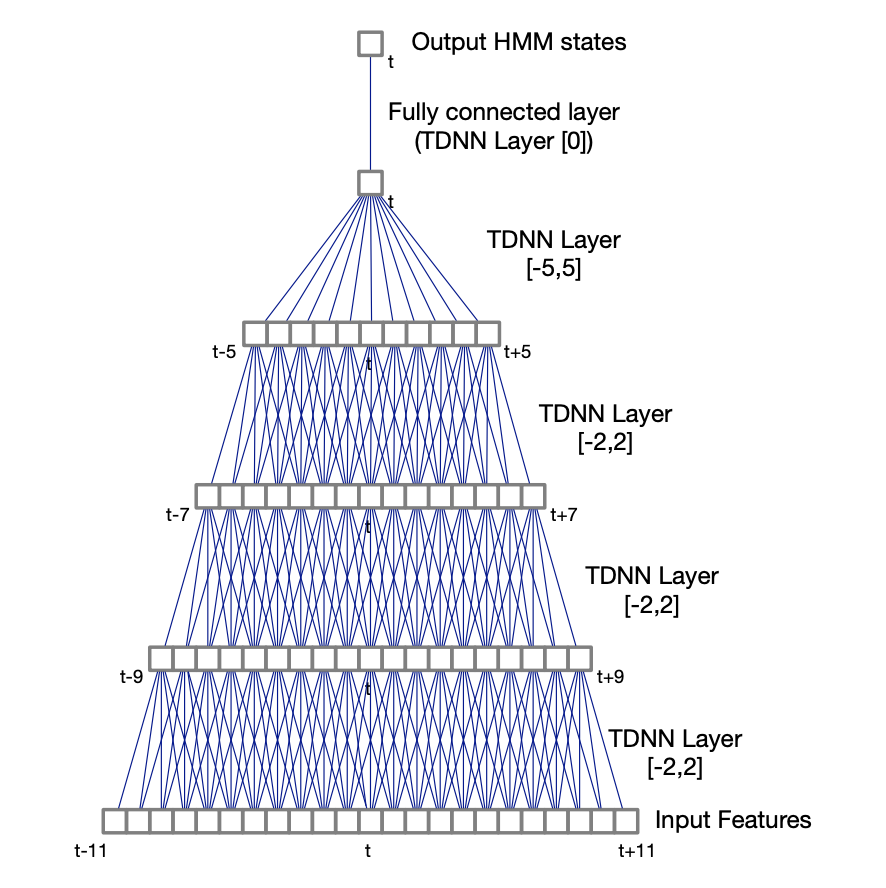
A TDNN with a context (-2, 2) has 5 times more weights than a regular DNN. For this reason, sub-sampled TDNNs are explored. Due to the large overlaps between input contexts at adjacent time steps, which are likely to be correlated, we take a sub-sample window of hidden unit activations. It reduces computation time and model weights.
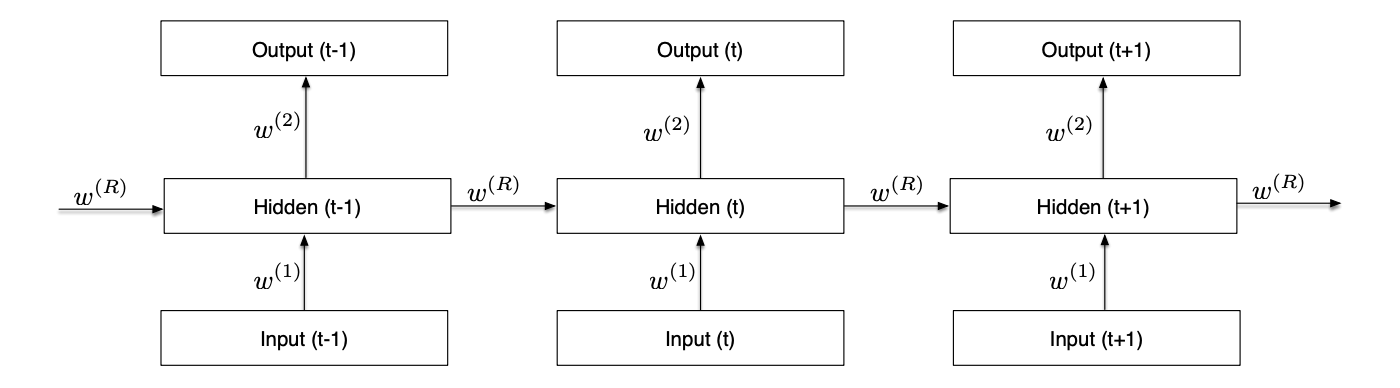
In its unfolded representation, the RNN for a sequence of T inputs is a T-layer network with shared weights. It can keep information through time.
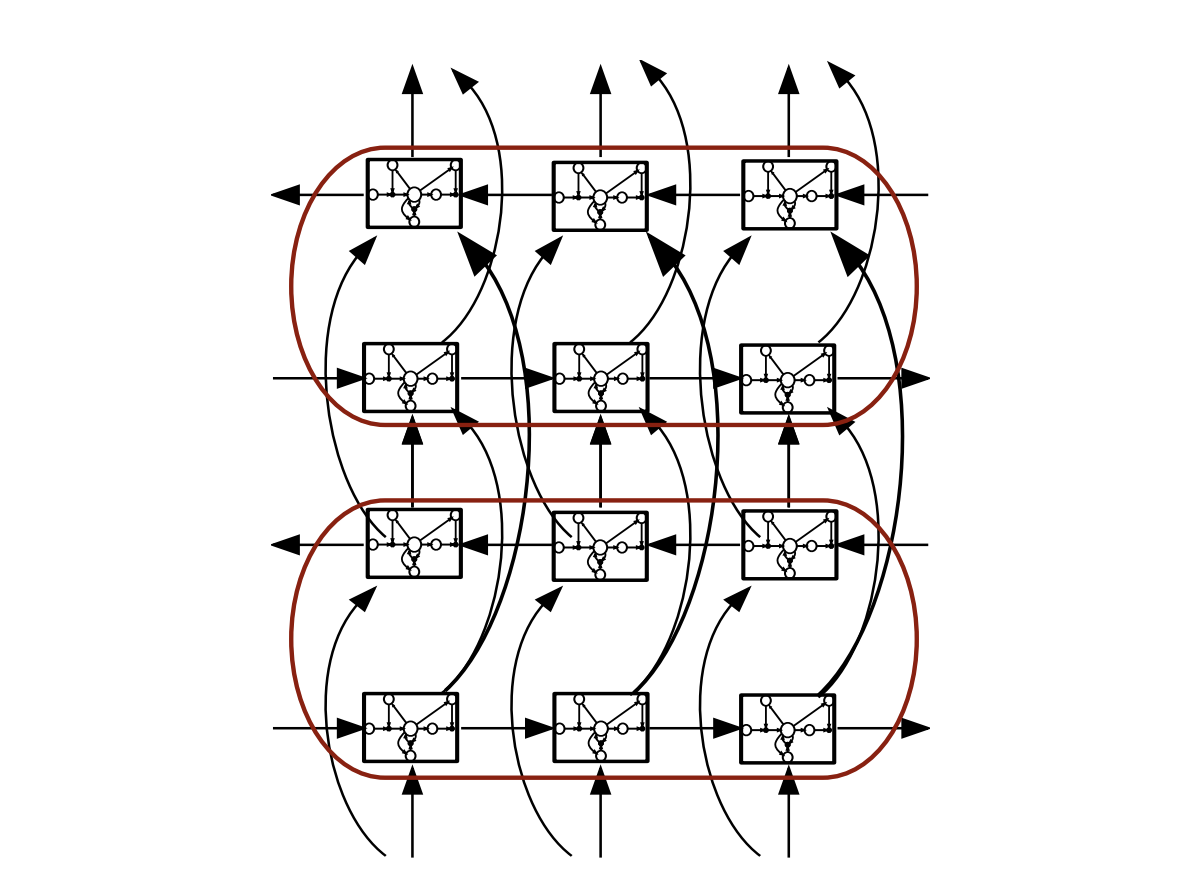
LSTMs avoid the vanishing gradient problem of RNNs. Bidirectional RNNs consider both the right and the left context, in a forward layer and a backward layer. Deep RNNs have several hidden layers, and deep bidirectional LSTM combine the advantages of all these methods:
Here is an example of a Bidirectional LSTM Acoustic Model training on the Switchboard dataset:
LSTMs + feature fusion currently reach close to state-of-the-art.
If you want to improve this article or have a question, feel free to leave a comment below :)
References:
]]>Acoustic modeling allows you to identify phonemes and transitions between them. But we still miss a step to return proper words: a language model that helps identify the correct words.
Recall the fundamental equation of speech recognition:
\[W^{\star} = argmax_W P(W \mid X)\]This is known as the “Fundamental Equation of Statistical Speech Processing”. Using Bayes Rule, we can rewrite is as :
\[W^{\star} = argmax_W \frac{P(X \mid W) P(W)}{P(X)}\]Where \(P(X \mid W)\) is the acoustic model (what we have done so far), and \(P(W)\) is the language model.
In brief, we use pronunciation knowledge to construct HMMs for all possible words, and use the most probable state sequence to recove the most probable word sequence.
In continuous speech recogniton, the number of words in the utterance is not known. Word boundaries are not known. We therefore need to add transitions between all word-final and word-initial states.
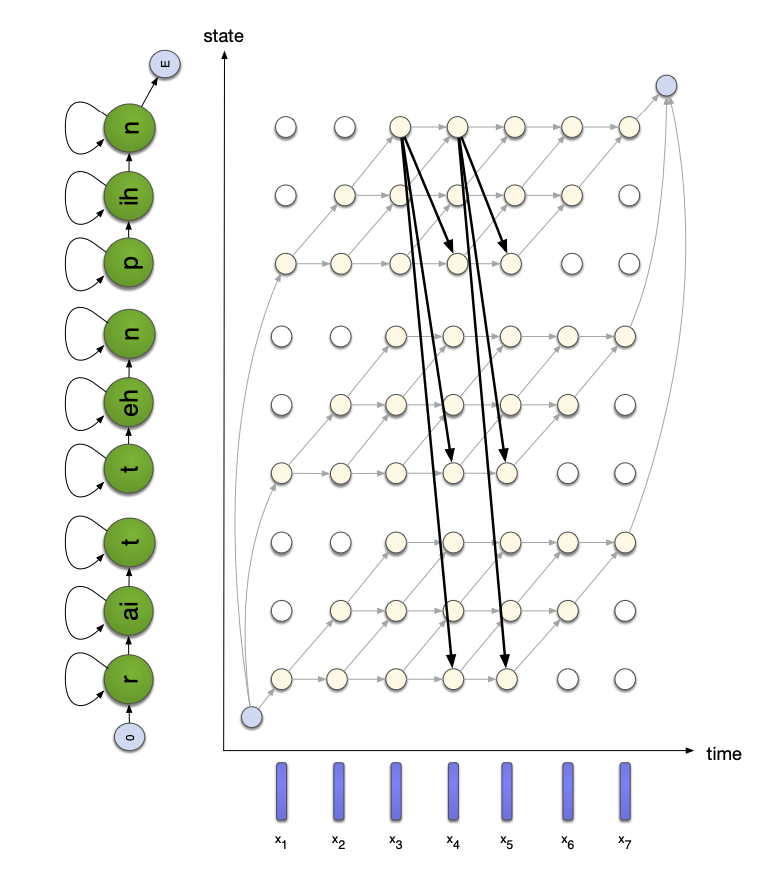
If we then apply Viterbi decoding to find the optimal word sequence, we need to consider \({\mid V \mid}^2\) inter-word transitions at every time step, where \(V\) is the number of words in the vocabulary. Needless to say, it can become a problem that is way too long to compute. However, if the HMM models are simples and the size of the vocabulary is small, we can decode the Markov Chain exactly with the Viterbi decoding.
So the question becomes: can we speed up the Viterbi search of the best sequence using some kind of information? And the answer is yes, using the Language Model (LM).
Recall that in an N-gram language model, you model the probability of observing \(w_i\) after a sequence of words \(w_{i-n}, w_{i-n+1}, ... w_{i-1}\)
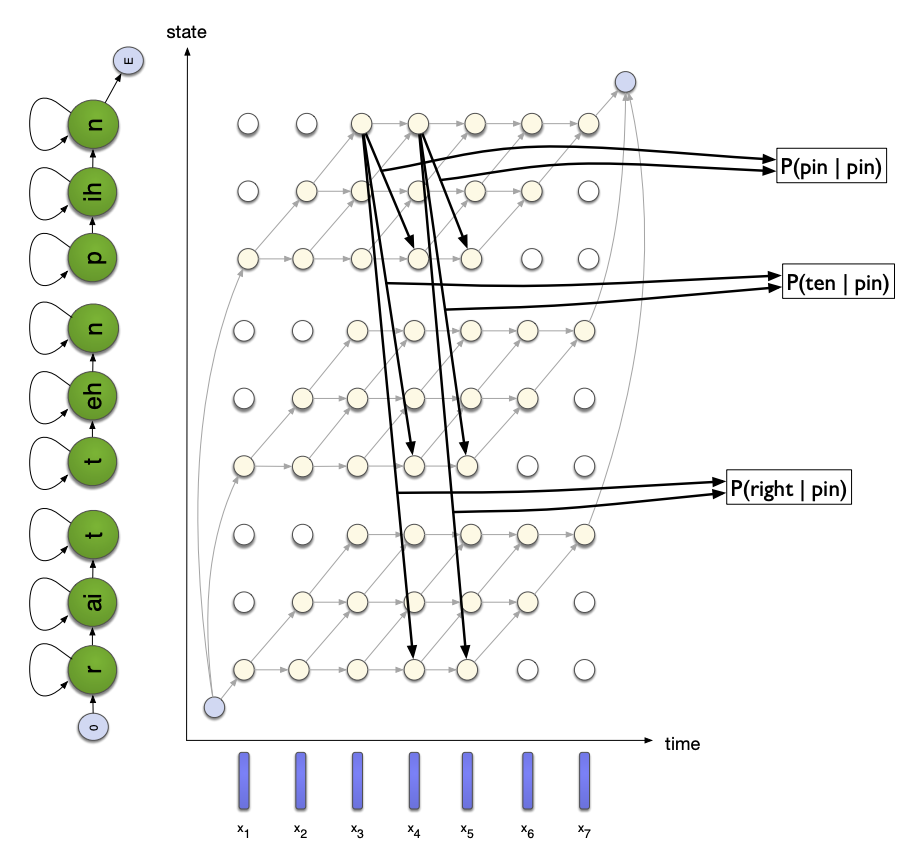
However, the exact search is not possible for large vocabulary tasks, especially in the case of the use of cross-words. There are several solutions to this:
In tree-structured lexicons, we represent the possible words of a language in a tree, nodes being phones, and leaves being words. Therefore, when we have a sequence of phones, we only need to follow the corresponding branch of the tree, which greatly reduces the number of state transition computations :
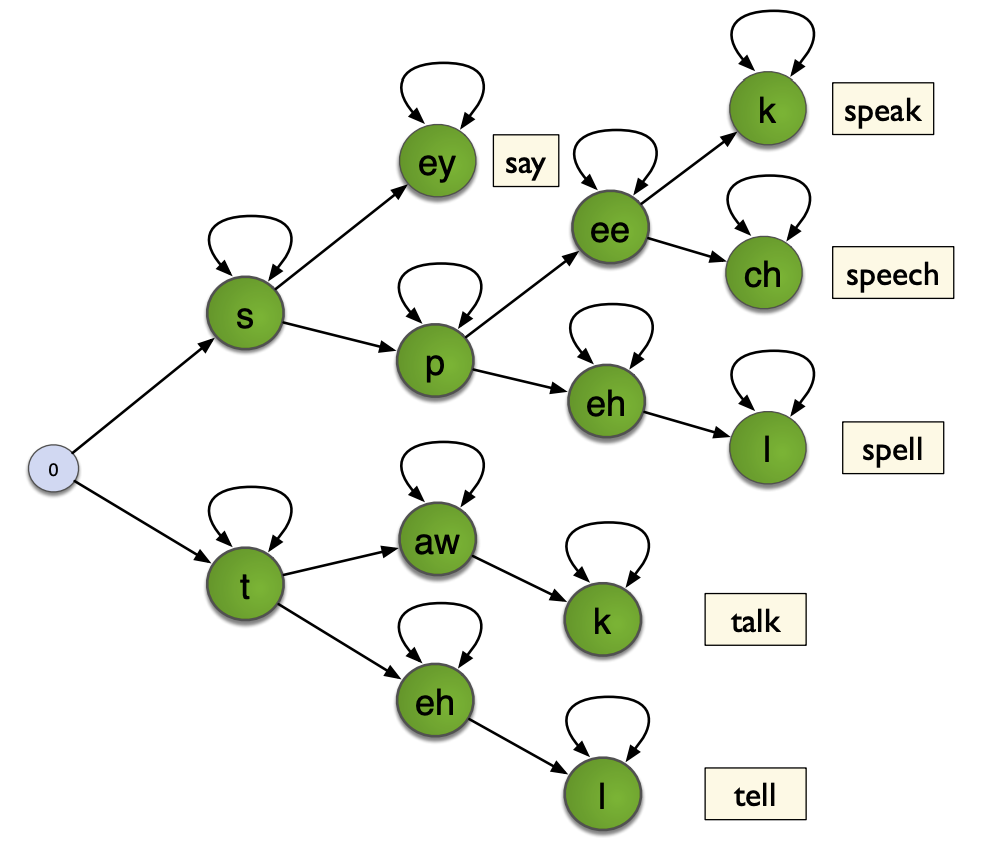
In a tree-structured decoding, we look ahead to find the best LM scores for any words further down the tree, and states are pruned early if they lead to a low probability. This makes the decoding faster, since many branches are dropped.
WFSTs are implemented and used in Kaldi. WFSTs transduce input sequences into output sequences. Each transition has an input label, an output label, and weights.
Let’s get back to the basics.
Finite State Automata (FSA) are extensively used in Speech. We define them as an abstract machine consisting of:
You migh recognize here a more generic definition of Hidden Markov Models (HMMs). HMMs are in fact a sub-base of Stochastic FSAs. A path in FSA is a series of directed edges.
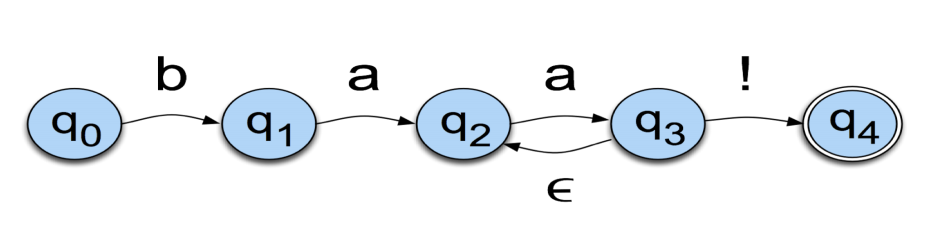
Let us conside the language of a sheep for example: /baa+!/. This language has 5 states:
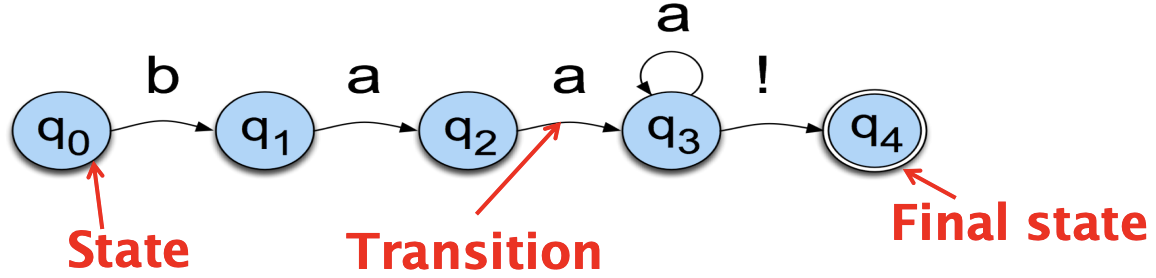
The state labels are mentioned in the circles, and the labels/symbols are on the arcs. More formally, FSAs are usually presented this way:
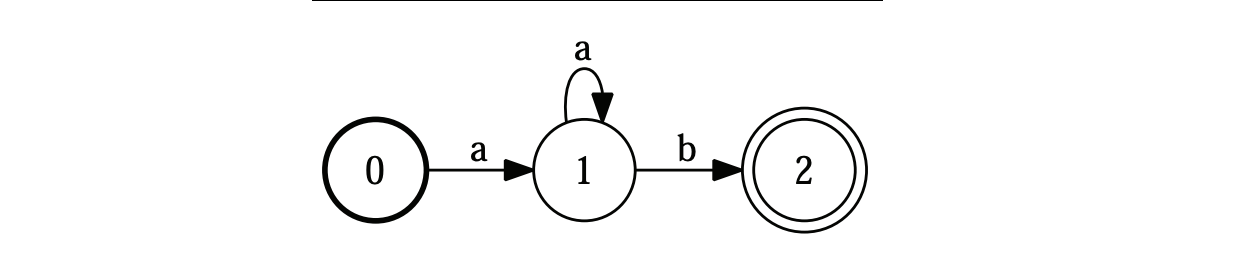
In our sheep example, the alphabet is made of 3 letters: b, a and !. It has a start state and an accept / final state, as well as 5 transitions. FSA acts as an Acceptor, in the sense that it can reject a set of strings/sequence:
A string is accepted if:
An additional symbol that has a special meaning in FSAs is \(\epsilon\). It means that no symbol is generated. This is a way to go back to a previous state without generating anything:
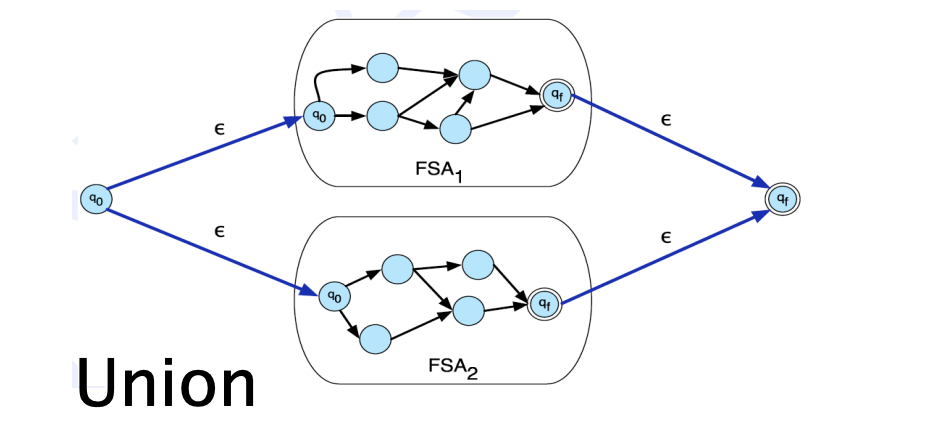
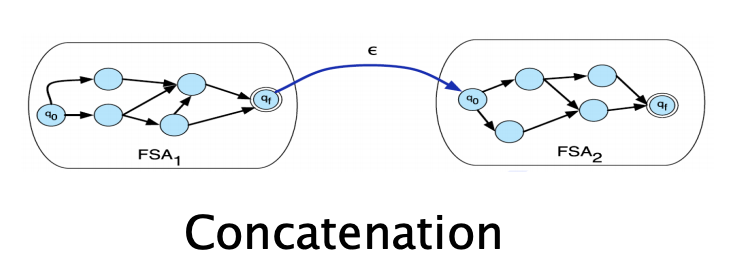
Formal languages are just sets of strings, and we can apply set operations on them. There are two main types of operations used on FSA and WFSTs:
Weighted FSA simply introduce a notion of weights on arcs and final states. These weights are also refered as costs. The idea is that is multiple paths have the same string, we take the one with the lowest cost. The cost, on the diagram below, is represented after the “/”.

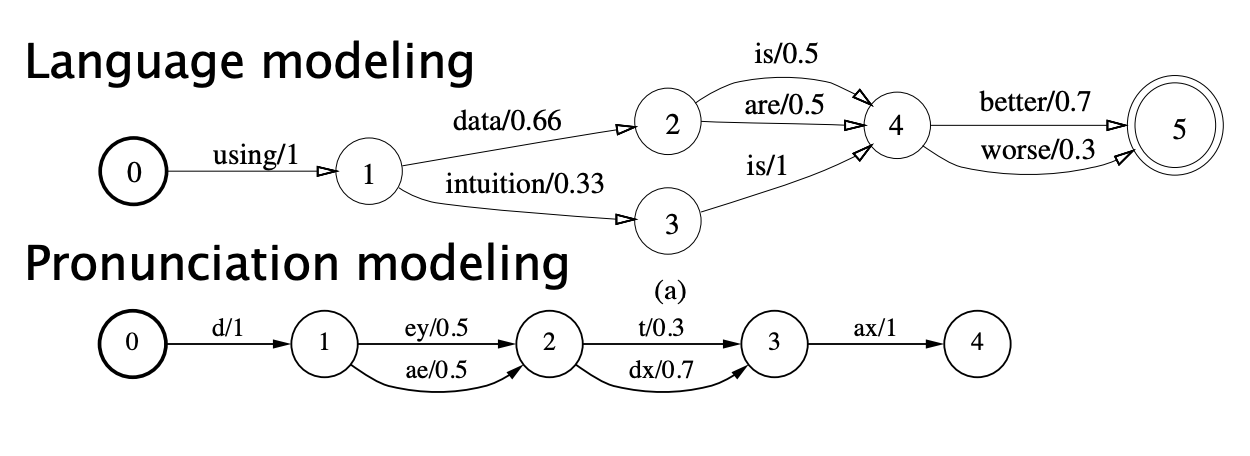
Weighted FSAs are used in speech, for language modeling or pronunciation modeling:
Finite Automata do no produce an output, whereas Finite State Transducers (FSTs) have both inputs and outputs. Now, on the arcs, the notation is the following:
a:b/0.3
Where:
Why do we need to produce outputs? For decoding ! We can typically take input phonemes and output words.
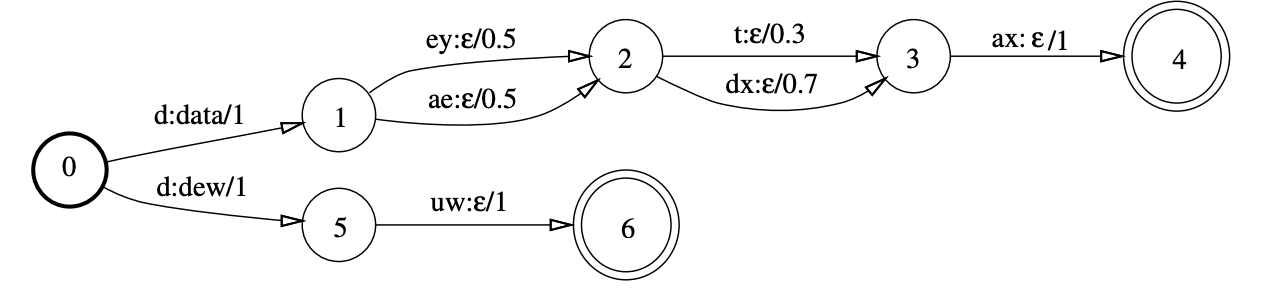
In this example, the output word is mentioned as the output of the 1st input. In this example, from the phoneme “d”, we can build 2 words:
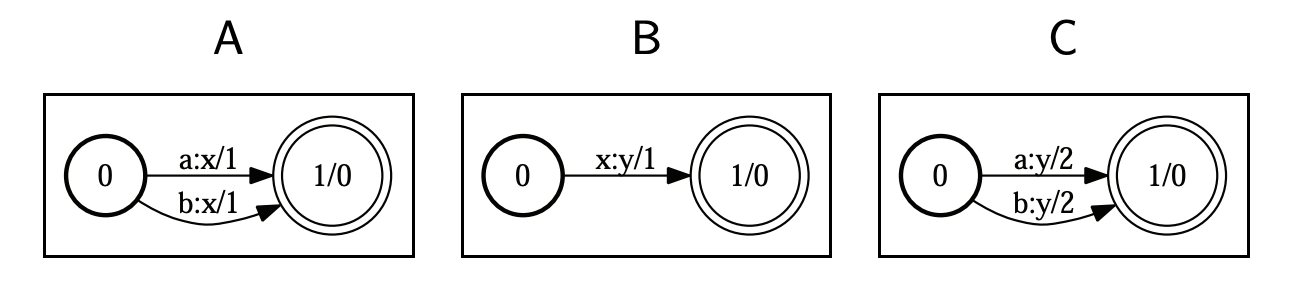
WFSTs can be composed by matching up inner symbols. In the example below, we match A and B in C, denote it C=A◦B, and since in A the inputs a and b and matched with x, and in b x is matched with y, in C, a and b are matched with y:
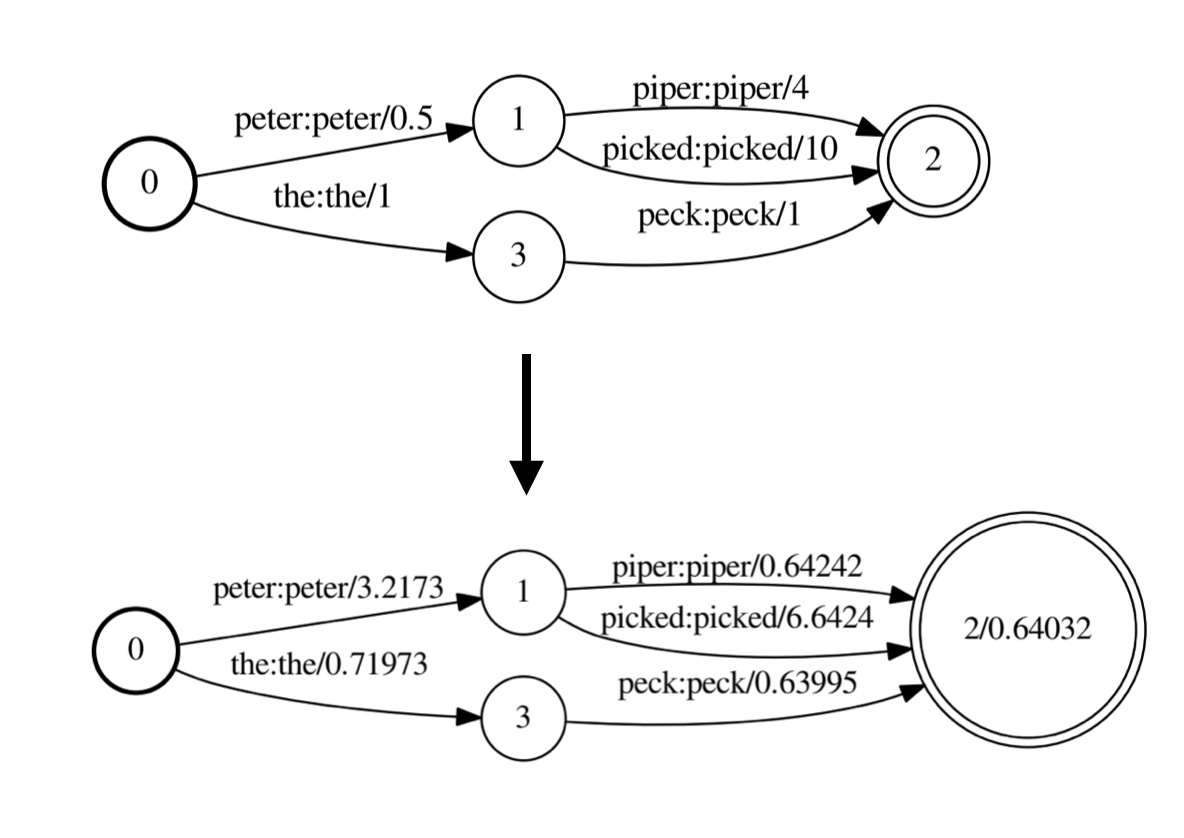
There are several algorithms to remember for WFSTs:
The weight pushing process could be illustrated this way:
The idea of the decoding network is to represent all components that allow us to find the most likely spoken word sequence using WFSTs:
HCLG = H◦C◦L◦G
Where:
All the components are built separately and composed together.
HMMs can be represented natively as WFSTs the following way:
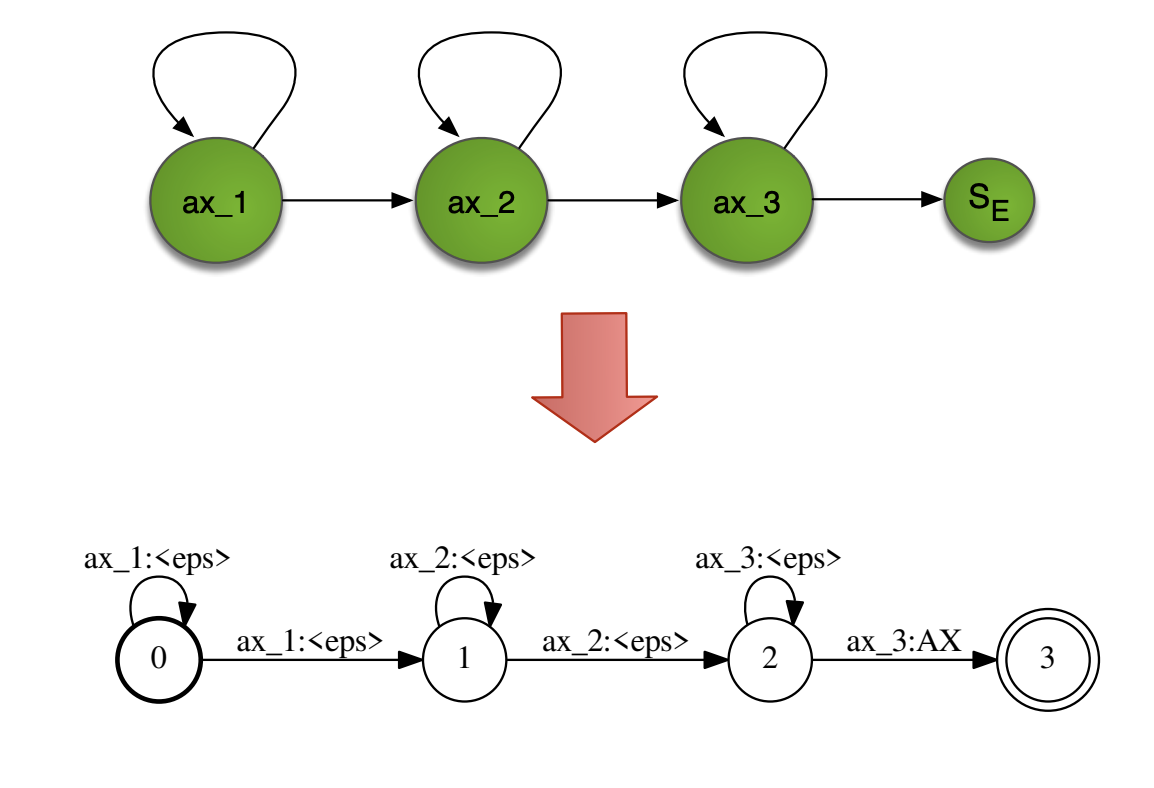
To avoid having too many context-dependent models (\(N^3\)), we apply what was mentioned in the HMM-GMM acoustic modeling: clustering based on a phonetic decision tree.
HMMs take into account context through context-dependent phones (i.e triphones). To feed it into the pronunciation lexicon, we need to build from these context-dependent phones a set of context-independent phones. To do that, a FST is built and explicits the transitions between triphones. For example, from a triphone “a/b/c”(i.e. central phone “b” with left context “a” and right context “c”), the arcs represent the individual phones “a”, “b”, “c”.
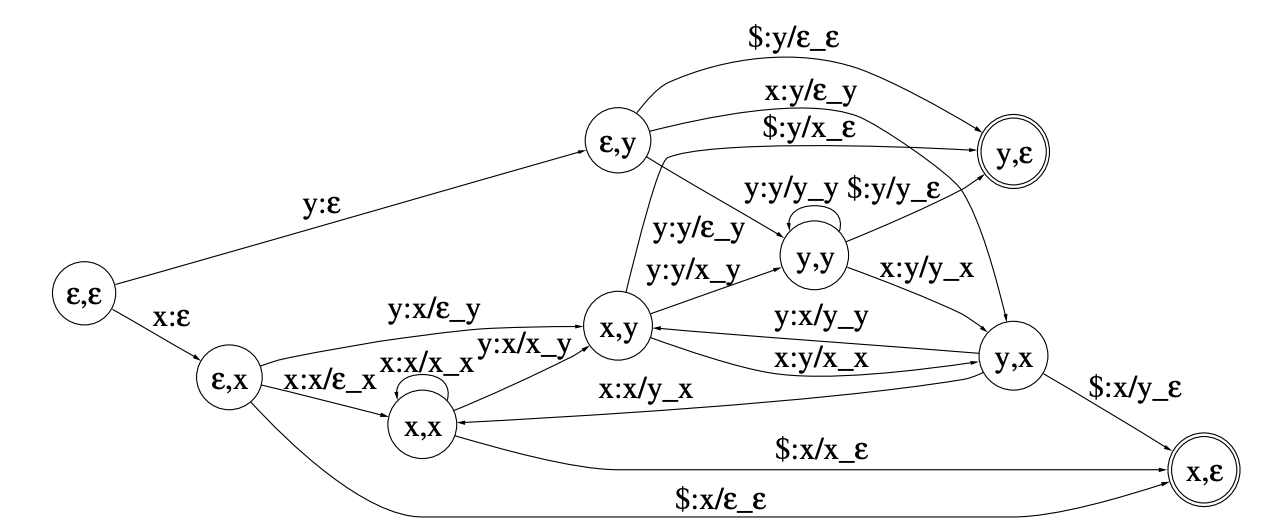
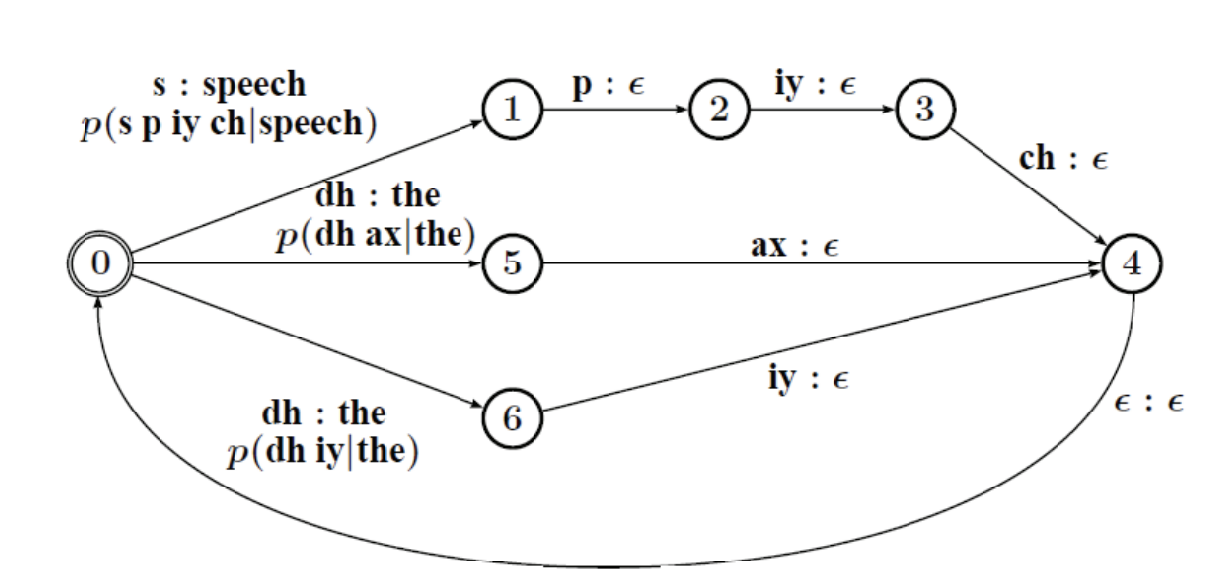
The Pronunciation lexicon L is a transducer that takes as an input context-independent phones and outputs words. The weights of this WFST are defined by the pronounciation probability.
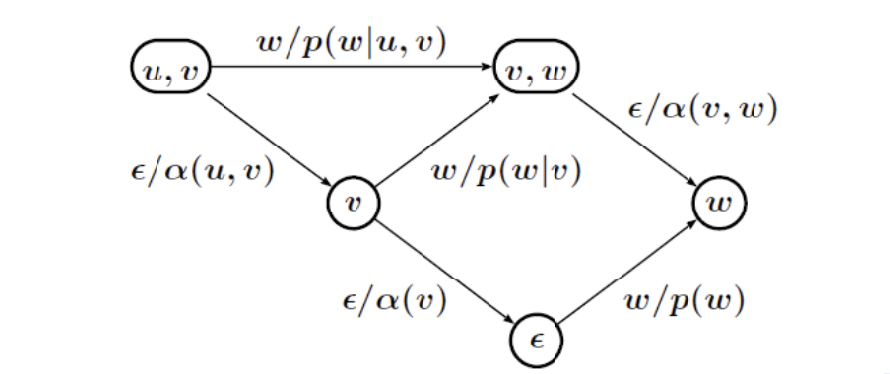
We can represent language models (LMs) as WFSAs easily too, and any type of LM will actually be implemented as a WFSA in Kaldi or other softwares. They do no produce any output, so they remain Automatas and not Transducers, since our aim is just to estimate the “cost” of a path.
In a unigram LM, the probability of each word only depends on that word’s own probability in the document, so we only have one-state finite automata as units.
In a bigram LM, the probability of a word depends on the previous word too, and in a trigram LM, on the 2 previous words. You would represents a trigram WFSA this way:
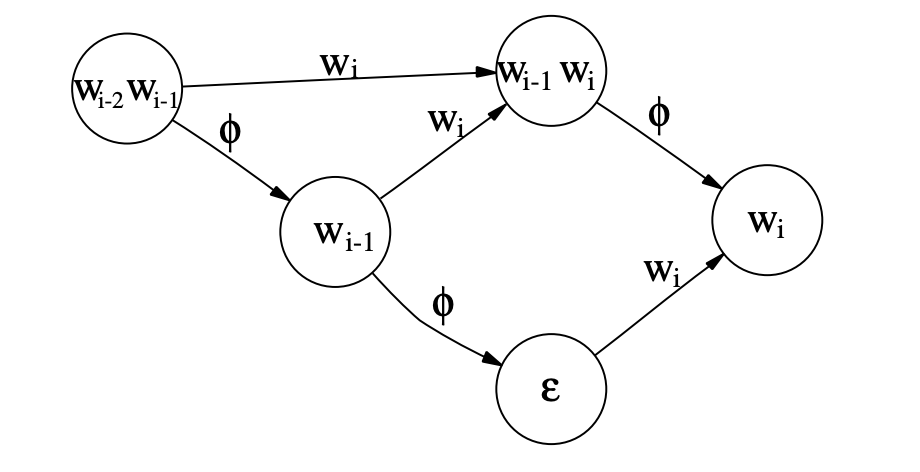
The different components of the deconding graph have now be explicited, and can be more formally defined as:
\[HCLG = rds(min(det(H ◦ det(C ◦ det( L ◦ G)))))\]Where:
If you want to improve this article or have a question, feel free to leave a comment below :)
References:
]]>